

python学习笔记 day44 mysql练习题(一)
习题来自: http://www.cnblogs.com/wangfengming/articles/7944029.html
1. 习题内容:
1.创建留言数据库: liuyandb;
2.在liuyandb数据库中创建留言表liuyan,结构如下:
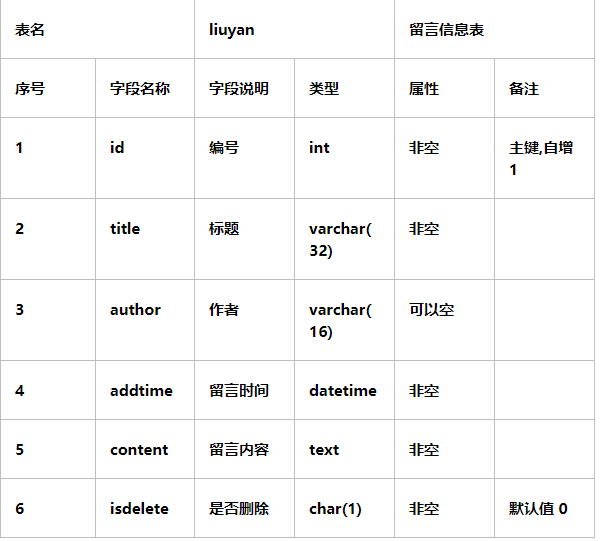
3.在留言表最后添加一列状态(status char(1) 默认值为0)
4.修改留言表author的默认值为’youku’,设为非空
5.删除liuyan表中的isdelete字段
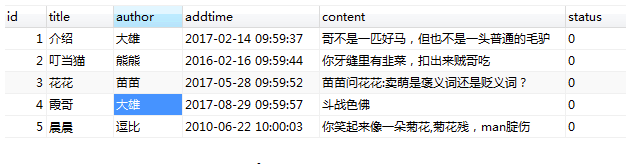
6.为留言表添加>5条测试数据 (例如:)
7. 要求将id值大于3的信息中author 字段值改为admin
8. 删除id号为4的数据。
附加题:
- 为留言表添加>10条测试数据,要求分三个作者添加数据
- 查询某一个作者的留言信息。
- 查询所有数据,按时间降序排序。
- 获取id在2到6之间的留言信息,并按时间降序排序
- 统计每个作者留了多少条留言,并对数量按从小到大排序。
- 将id为8、9的两条数据的作者改为’doudou’.
- 取出最新的三条留言。
- 查询留言者中包含”a”字母的留言信息,并按留言时间从小到大排序
- 删除”作者”重复的数据,并保留id最大的一个作者
2. 解法:
2.1 1-8小题:
create table message( id int not null auto_increment primary key, title varchar(32) not null, author varchar(16) null, addtime datetime not null, content text not NULL, isdelete char(1) not null default 0) desc message; alter table message add status char(1) default 0; -- 在留言表最后添加一列状态(status char(1) 默认值为0) alter table message modify author varchar(16) not null default "youku"; # 修改留言表author 默认值为youku 设为非空 desc message; alter table message drop isdelete; -- 删除留言表中的isdelete字段; desc message; insert into message values(1,"介绍","大雄","2017-02-14 09:59:37","哥不是一匹好马,但也不是一头普通的毛驴",0); insert into message values(2,"叮当猫","熊熊","2016-06-16 09:59:44","哥迷人的五官就是你犯罪的开端",0); insert into message values(3,"璇璇","小仙女","2018-11-03 09:40:37","喜欢一个人太累了,所以我喜欢十个",0); insert into message values(4,"西西","小天使","1996-04-12 00:00:00","嗯嗯好的知道了就这样恩恩欧克好的敷衍",0); insert into message values(5,"夏夏","宝贝","2018-06-05 16:20:37","我手机快没电了,先不聊了(电量99%)",0); select * from message; update message set author ="admin" where id>3; -- 将id值大于3的信息中author字段值改为admin; delete from message where id=4; -- 删除id=4的数据;
2.2 附加题:
insert into message(title,author,addtime,content) values("作家","村上春树","2018-11-03 09:57:01","你要做一个不动声色的大人了,不准情绪化,不准偷偷想念,不准回头看"); insert into message(title,author,addtime,content) values("作家","村上春树","2018-11-03 09:58:12","哪里会有人喜欢孤独,不过是不喜欢失望罢了"); insert into message(title,author,addtime,content) values("作家","村上春树","2018-11-03 10:00:01","其实我一直以为人是慢慢变老的,其实不是,人是一瞬间变老的"); insert into message(title,author,addtime,content) values("作家","村上春树","2018-11-03 10:02:34","希望你可以记住我,记住我这样活过,这样在你身边呆过"); insert into message(title,author,addtime,content) values("作家","老舍","2018-11-03 10:03:56","苦人是容易死的,苦人死了是容易被忘掉的"); insert into message(title,author,addtime,content) values("作家","老舍","2018-11-03 10:13:45","乱世的热闹来自迷信,愚人的安慰只有自欺"); insert into message(title,author,addtime,content) values("作家","老舍","2018-11-03 10:23:36","经验就是生活中最重要的催化剂,有什么样得经验就会变成什么样的人,就像沙漠里养不出牡丹一样"); insert into message(title,author,addtime,content) values("作家","张爱玲","2018-11-03 11:34:12","如果你认识从前的我,也许你会原谅现在的我"); insert into message(title,author,addtime,content) values("作家","张爱玲","2018-11-03 11:24:11","人总是在接近幸福时倍感幸福,在幸福进行时却患得患失"); insert into message(title,author,addtime,content) values("作家","张爱玲","2018-11-03 11:45:34","我要你知道,在这个世界上总有一个人是等着你的,不管在什么时候,不管在什么地方,反正你知道,总有这么一个人"); select * from message;
运行结果:
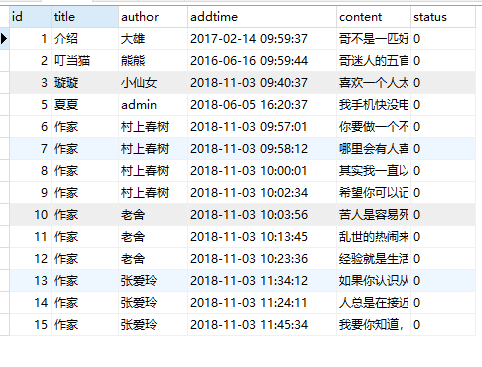
select content from message where author ="张爱玲"; -- 查询某一个作者(张爱玲)的留言信息; select * from message order by addtime desc; -- 查询所有数据,按时间降序排序; select id,content,addtime from message where id between 2 and 6 order by addtime desc; -- 查询id在2-6之间的留言信息,并按照时间降序排序; select id,author,count(content) as number from message group by author order by number asc; -- 统计每位作者留言数目,并且对数量按照从小到达的顺序排序 update message set author="doudou" where id in (8,9); -- 将id为8,9的两条数据作者改为doudou select * from message; select id,author,content from message order by addtime desc limit 0,3; -- 取出最新的三条留言(首先按照时间降序排序,然后使用limit分页显示,只显示前三条) select id,author,content,addtime from message where content like "%你%" order by addtime asc; -- 查询留言中包含“你”的留言信息,并按照留言时间从小到大排序(包含:使用通配符) create table message_copy select * from message; -- 先复制一张表,来操作,要不然删错了就尴尬了,,, select * from message_copy;
第九小题:参考了别人的答案: https://blog.csdn.net/qq_25067905/article/details/54970514
首先我可以把那些"作者"重复,id不是最大的那些数据项查出来:
select * from message_copy as t1 left join (select author,max(id)as mid,count(author)as number from message_copy group by author)as t2 on t1.author=t2.author where t1.id<mid and number>1; select * from message_copy;
运行结果:
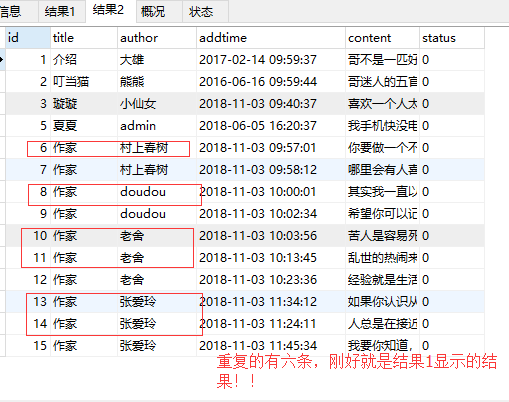
我只能把作者重复的并且id不是最大的数据项筛选出来,也就是上面第一张表,可是我怎么把他们从下面那张表中删掉啊!!!
我知道啦!!!
create table t select * from message_copy;-- 先复制一张表t select * from t; delete from t where id in (select id from message_copy as t1 left join (select author,max(id)as mid,count(author)as number from message_copy group by author)as t2 on t1.author=t2.author where t1.id<mid and number>1 ) # 然后再删t表中id为 连接表中id的数据 select * from t;
运行结果: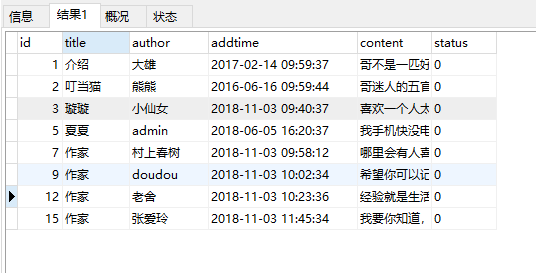
之前我是:
delete from message_copy where id in (select id from message_copy as t1 left join (select author,max(id)as mid,count(author)as number from message_copy group by author)as t2 on t1.author=t2.author where t1.id<mid and number>1 )
出错:
我查了一下,发现是:
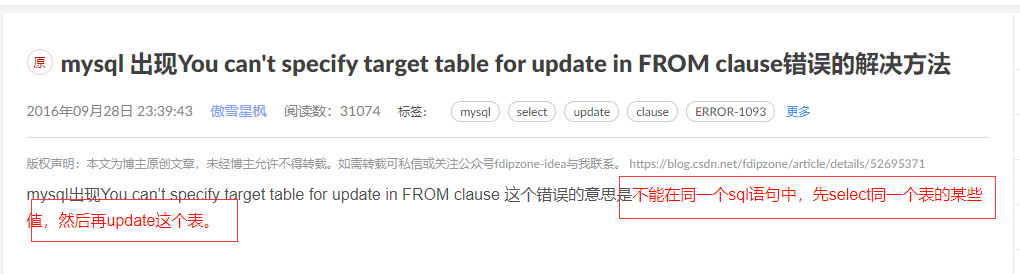
终于做出来了!!!
talk is cheap,show me the code

