

python学习笔记 day21 包和异常
包: 一大堆模块的集合
通俗的讲之前我们学序列化模块时,有个json 它其实是一个文件夹(里面有很多py文件),应该就算是一个包;
然后导入包的时候,.前面一定是一个包名,然后可以有两种方式 import 包名 或者 from 包 import 模块 (这种导入方式 包那块可以有. 但是import 后面必须是一个变量名,绝对不能有.)
首先创建一系列文件夹(包)和文件(py文件 模块)
import os os.makedirs('glance/api') # 使用os.makedirs('filename1/filename2')创建文件夹 os.makedirs('glance/cmd') os.makedirs('glance/db') L=[] # L中存放的是一系列文件句柄 L.append(open('glance/__init__.py','w')) L.append(open('glance/api/__init__.py','w')) L.append(open('glance/api/test1.py','w')) L.append(open('glance/api/test2.py','w')) L.append(open('glance/cmd/__init__.py','w')) L.append(open('glance/cmd/test1.py','w')) L.append(open('glance/db/__init__.py','w')) L.append(open('glance/db/test1.py','w')) map(lambda f :f.close(), L) # 利用map()函数 主要是挨个从放着文件句柄的列表L中依次取值,然后传给lambda函数 关掉该文件
运行结果: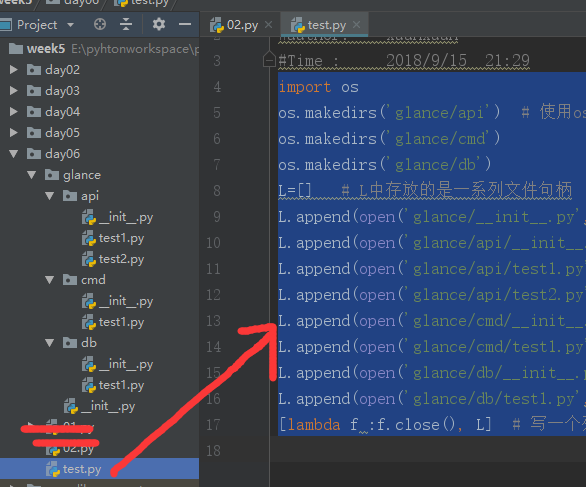
然后在api文件夹下的test1.py test2.py 文件,cmd文件夹下的test1.py 文件 和db文件夹下的test1.py 下面写相应的print()语句 或者定义函数~
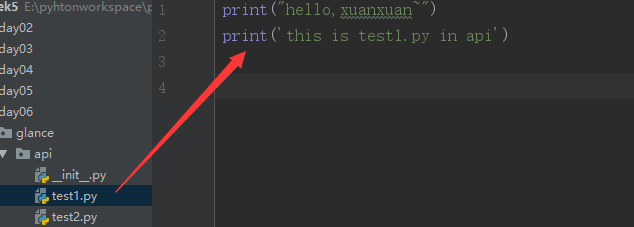
然后进行各种方式的导入:
import glance.api.test1 glance.api.test1
或者这种方式:
import glance.api.test1 as test test
或者:
from glance.api import test1 test1
运行结果:

再来看一下test2.py 的内容: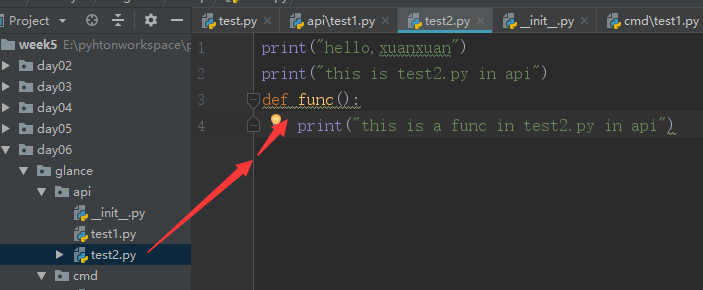
然后我们导入:
from glance.api import test2 test2.func()
或者:
from glance.api.test2 import func func()
运行结果:
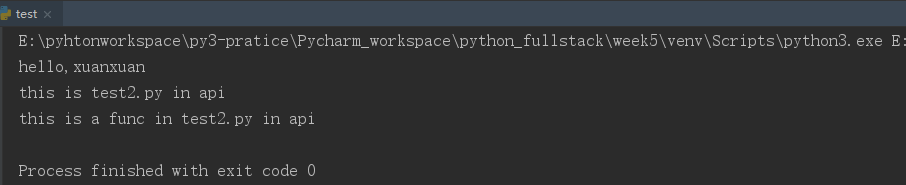
然后其他文件夹(包)的py文件(模块)的导入都跟上面的类似;
接下俩我们有一个新的需求就是在test.py(与glance文件夹位于同一级目录)中只写 import glance 就可以使用glance.api.test1 运行test1.py 文件 或者glance.api.test2.func()就可以运行api下面的test2.py中的func()函数~
这样应该怎么操作呢?
我们需要明确一点:导入包时,都是自动会运行该包下面的__init__.py文件!!!
先来验证一下这个操作:
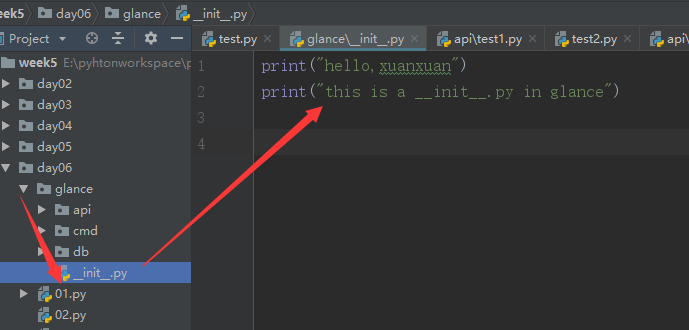
然后我们导入 glance模块,看是否会运行glance包下面的__init__.py文件中的内容:
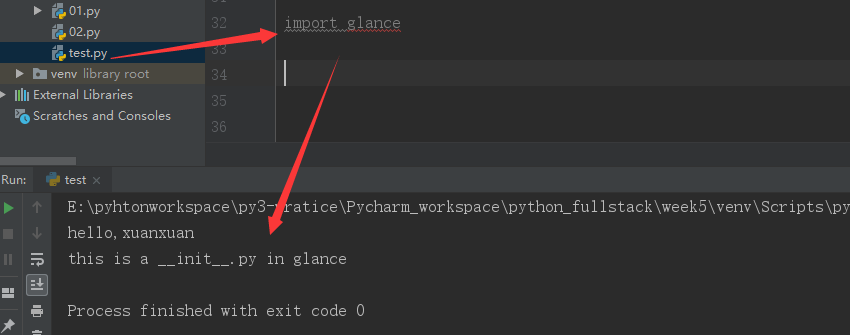
所以我们可以在相应包下面的__init__.py文件中做手脚,相当于联动触发,这一级出发下一级别:
我们先来看一下,在test.py中查看模块路径是什么样的:
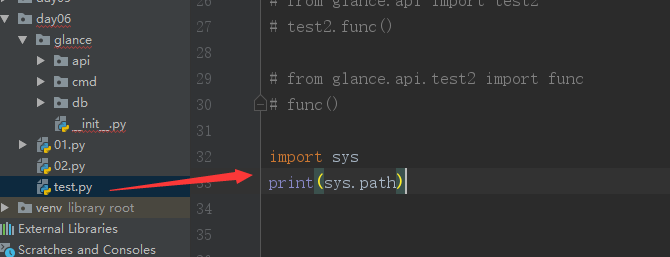
运行结果:
所以相当于day06文件夹其实就是类似于根目录的样子~,不知道这样说对不对,反正就是test.py是在day06文件夹下嘛,所以相当于它的根目录直接就是day06 ,就是在test.py中导入模块时,优先从da'y06这个目录下面找有没有该模块,然后我们继续:
首先在glance包下面的__init__.py中写:
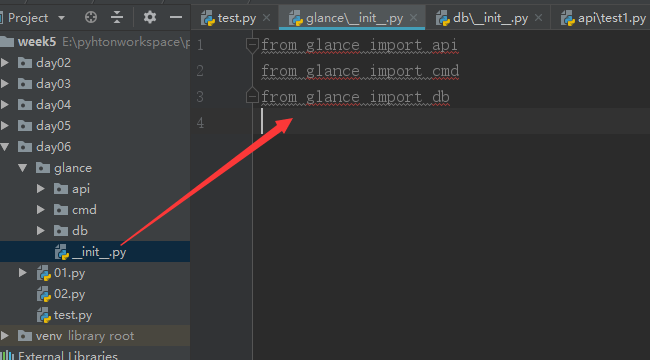
然后在 api 下面的__init__.py中: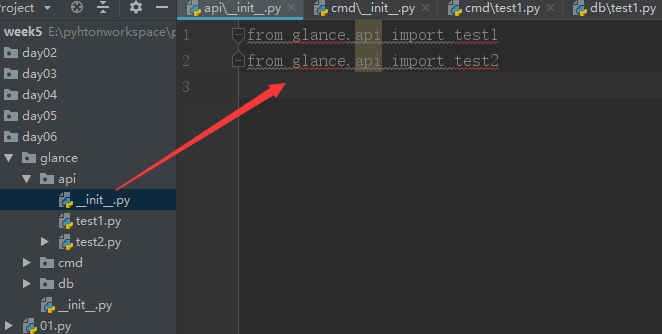
另外两个也一样: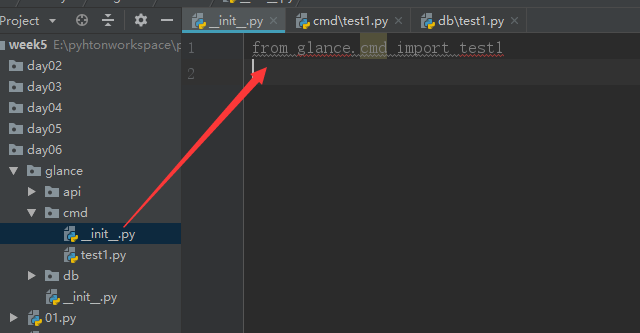
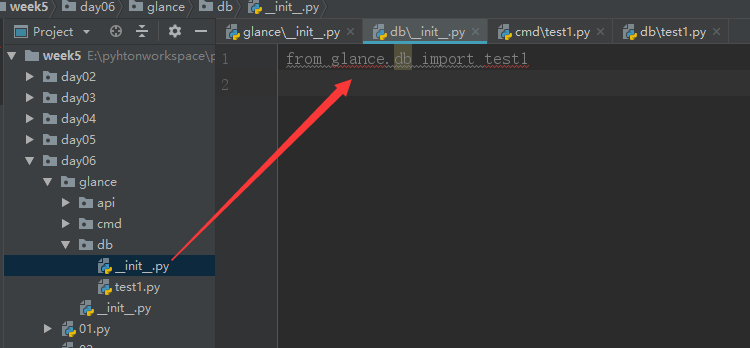
进行完上面的操作之后
当我们在test.py中导入glance后,我们就可以 直接拿着这个包名进行操作下面的任何一个文件了:
import glance glance.api.test1 glance.api.test2.func() # api下面的test2.py中定义了一个函数func glance.cmd.test1 glance.db.test1
运行结果:
所以导入包的时候需要格外注意~
另外,当你直接导入py文件或者通过包.包 导入文件(只要最后导入的是py文件 ---模块)导入的那一刻就会运行该py文件的内容;
但是当你最后导入的是包时,它只会运行这个包下面的__init__.py这个是自动运行的~

