

python学习笔记day08 文件操作
文件操作
想要打开一个文件需要:
1.文件所在位置:绝对路径;
2.文件编码方式:utf-8,gbk...;
3.打开文件的方式:只读,只写,追加,读写,写读;
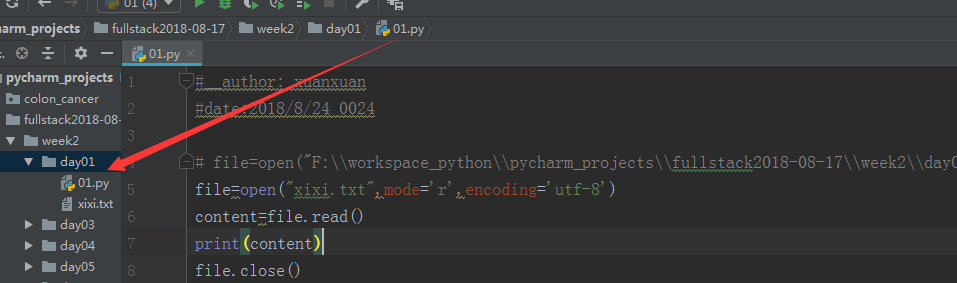
file=open("F:\\workspace_python\\pycharm_projects\\fullstack2018-08-17\\week2\\day01\\xixi.txt",mode='r',encoding='utf-8') content=file.read() print(content)
file.close()
文件操作三部曲:打开文件,读取文件内容,关闭文件;
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day01/01.py
城市越来越大,我们却越来越远。也许我们之间的感情就像杯子一样,碰一碰才不会有距离。
有时候,杯子多了就是一群人的狂欢,其实也是每个人的孤单,心情不好的时候,有谁愿意和我们说话;
有时候我们听不进去别人的批评,也不愿意去多说,总在回忆过去那些兄弟姐妹之间的真心对话;
生活中有些人,走近了又走远了。就像聚会再热闹,总有散伙的一刻;
生活犹如一个杯子,满了,又空了,我们在对话,我们和杯子在对话,我们和自己在对话;
Process finished with exit code 0
注:
1.使用文本文档新建一个文件,这时候open()函数中的参数encoding='utf-8' 就不需要啦,因为默认txt文件不是utf-8??反正我是会报错的,编码方式不写就可以直接打开txt文件啦;
2.但是如果encoding='utf-8' 那么文本文档需要使用记事本打开,另存为的时候下方编码方式需要选择utf-8的形式保存;
3.open()函数中文件的绝对路径的写法有三种:
a. 路径前面加上 r:
r 'F:\workspace_python\pycharm_projects\fullstack2018-08-17\week2\day01' #加r 避免\当成转义字符
b. \ 变为\\:
"F:\\workspace_python\\pycharm_projects\\fullstack2018-08-17\\week2\\day01\\xixi.txt" #\---->\\
c. \变为/:
F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day01/xixi.txt
当然由于我的py文件和所要读取的txt文件在同一个目录下,所以可以不用写绝对路径,写相对路径即可:
要注意:文件以什么方式存储就要以什么方式读取~
读:r---读取文件 ; rb 二进制方式读取文件;
file=open("dang",mode='r',encoding='utf-8') content=file.read() print(content) file.close()
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day01/01.py
我是一个小可爱
当以rb读取时:
file=open("dang",mode='rb',encoding='utf-8') content=file.read() print(content) file.close()
会报错:
Traceback (most recent call last): File "F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day01/01.py", line 11, in <module> file=open("dang",mode='rb',encoding='utf-8') ValueError: binary mode doesn't take an encoding argument
因为文件file本身就是用 rb 二进制读取的(bytes类型本身就是utf-8 参数没必要写啦)
rb:当所要读取的文件是图像类型(非文字)或者是需要上传下载时可以用到 ~b方式
正确写法:
file=open("dang",mode='rb') content=file.read() print(content) file.close()
运行结果:(bytes类型中文表现形式就是b后面十六进制)
b'\xe6\x88\x91\xe6\x98\xaf\xe4\xb8\x80\xe4\xb8\xaa\xe5\xb0\x8f\xe5\x8f\xaf\xe7\x88\xb1'
写:w ----写;wb---二进制方式写;
file=open("dang",mode='w',encoding='utf-8') content=file.write("大吉大利,今晚吃鸡") file.close()
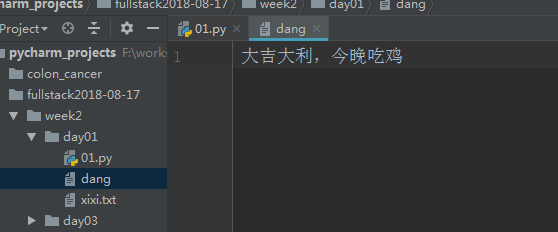
以wb方式向文件中写内容时,open()函数中的参数encoding就不用写啦,因为本身wb就是以二进制方式写,bytes编码方式就是utf-8 (gbk)~~
但是当你写内容时,是字符串对象,python3中字符串编码方式unicode 所以需要进行转换成utf-8才可以正确写入;
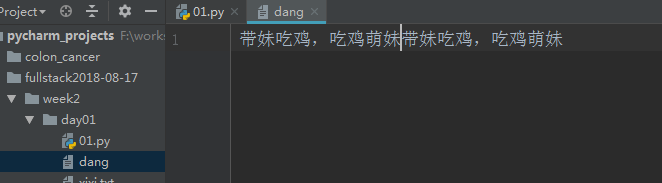
file=open("dang",mode='wb') #这里wb 已经是bytes类型编码是utf-8了就不用encoding啦 content=file.write("带妹吃鸡,吃鸡萌妹".encode('utf-8')) #由于所写的内容是str类型,str编码unicode 所以需要str(unicode)-->bytes(utf-8) file.close()

追加(也是写的一种): a----在文件原来内容基础上追加新内容;ab---以二进制方式追加
file=open("dang",mode='a',encoding='utf-8') content=file.write("带妹吃鸡,吃鸡萌妹") file.close()
file=open("dang",mode='ab') #以二进制方式追加,bytes默认编码utf-8 所以不用再在open()中写encoding content=file.write("我是追加的内容".encode('utf-8')) print(content) file.close()
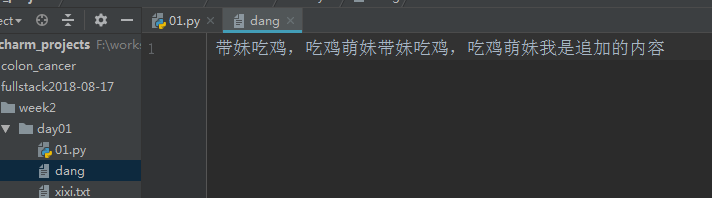
总结,当以wb 或者 ab 方式忘文件中写入内容时,open()函数中参数encoding 不用再写了,因为bytes类型本身默认编码就是utf-8 ;
写入内容时由于是str 类型,编码方式是unicode 需要进行一个转换str.encode('utf-8') 把unicode编码的str 转换为utf-8编码的bytes;
读写:r+ 读写
上面的r rb w wb a ab 都是只能读 或者只能写(清空了重新写,覆盖;和追加写),r+是既可以读又可以写:
file=open('dang',mode='r+',encoding='utf-8') print(file.read()) file.write("哈哈哈") file.close()
运行结果:
F:\workspace_python\pycharm_projects\venv\Scripts\python.exe F:/workspace_python/pycharm_projects/fullstack2018-08-17/week2/day01/01.py
带妹吃鸡,吃鸡萌妹带妹吃鸡,吃鸡萌妹我是追加的内容
然后我们刚才写的‘哈哈哈’已经在文件中啦:
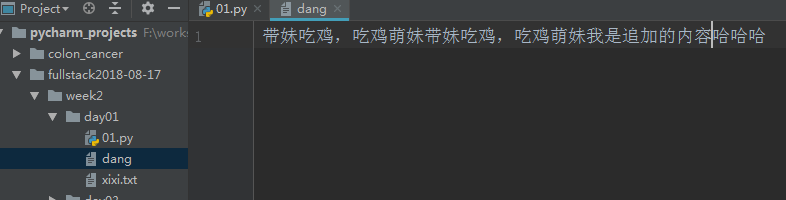
如果我们再在写完之后再读一遍,是不是可以把哈哈哈也读到呢?


file=open('dang',mode='r+',encoding='utf-8') print(file.read()) file.write("哈哈哈") print(file.read()) file.close()

是不可以的~因为r+是读取,可以再写,但是写之后的内容是读不到啦~就是因为写完之后光标已经移至最后一个位置,再度时从光标位置开始,所以后面没有东西当然读不到啦~
我们可以这样操作:
file=open('dang',mode='r+',encoding='utf-8') print(file.read()) file.write("哈哈哈") file.seek(0) #写完之后将光标移至最开始,在进行读取就ok了 print(file.read()) file.close()

其实 r+读写,也可以先写,再读:
file=open('dang',mode='r+',encoding='utf-8') file.write("哈哈哈") print(file.read()) file.close()

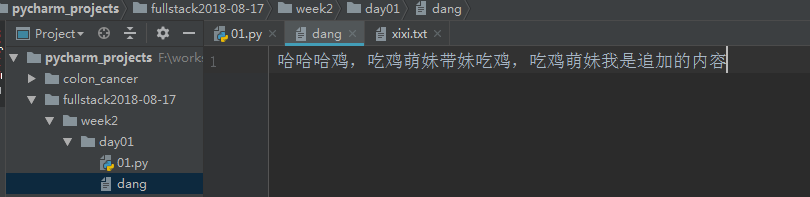
可以发现此时文件中的内容已经不是在末尾的哈哈哈了,而是从开头开始写,将原来的相应长度的内容覆盖了,然后此时先写再读的话读取的是剩下的原来未被覆盖的内容~
不过一般不这样操作,知道就行啦~
写读: w+
file=open("dang",mode='w+',encoding='utf-8') file.write("我是中国人,我骄傲") print(file.read()) file.close()


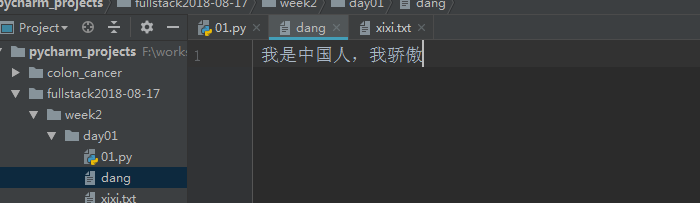
可以看出来文件内容已经被新的内容覆盖了,而且w+写完再进行读取时是读不到内容的(类比w写完再进行读操作是会报错的),但是我们可以把光标移动到开头再进行读取:
file=open("dang",mode='w+',encoding='utf-8') file.write("我是中国人,我骄傲") file.seek(0) #写完之后将光标移至开头再进行读取 print(file.read()) file.close()

追加读:a+ 原来a只可以写(追加的方式)现在可以追加完再读:
file=open('dang',mode='a+',encoding='utf-8') file.write('小日本大坏蛋') file.seek(0) #追加完之后把光标移动到开头,可以进行读取(包括追加完的内容) print(file.read())



