

堆 【笔记】
一.堆的性质
1.堆是一颗完全二叉树
2.堆的顶端一定是“最大”,最小”的,但是要注意一个点,这里的大和小并不是传统意义下的大和小,它是相对于优先级而言的,当然你也可以把优先级定为传统意义下的大小,但一定要牢记这一点,初学者容易把堆的“大小”直接定义为传统意义下的大小,某些题就不是按数字的大小为优先级来进行堆的操作的
(但是为了讲解方便,下文直接把堆的优先级定为传统意义下的大小,所以上面跟没讲有什么区别?)
3.堆一般有两种样子,小根堆和大根堆,分别对应第二个性质中的“堆顶最大”“堆顶最小”,对于大根堆而言,任何一个非根节点,它的优先级都小于堆顶,对于小根堆而言,任何一个非根节点,它的优先级都大于堆顶(这里的根就是堆顶啦qwq)
来一张图了解一下堆(这里是小根堆)(原谅我丑陋无比的图)
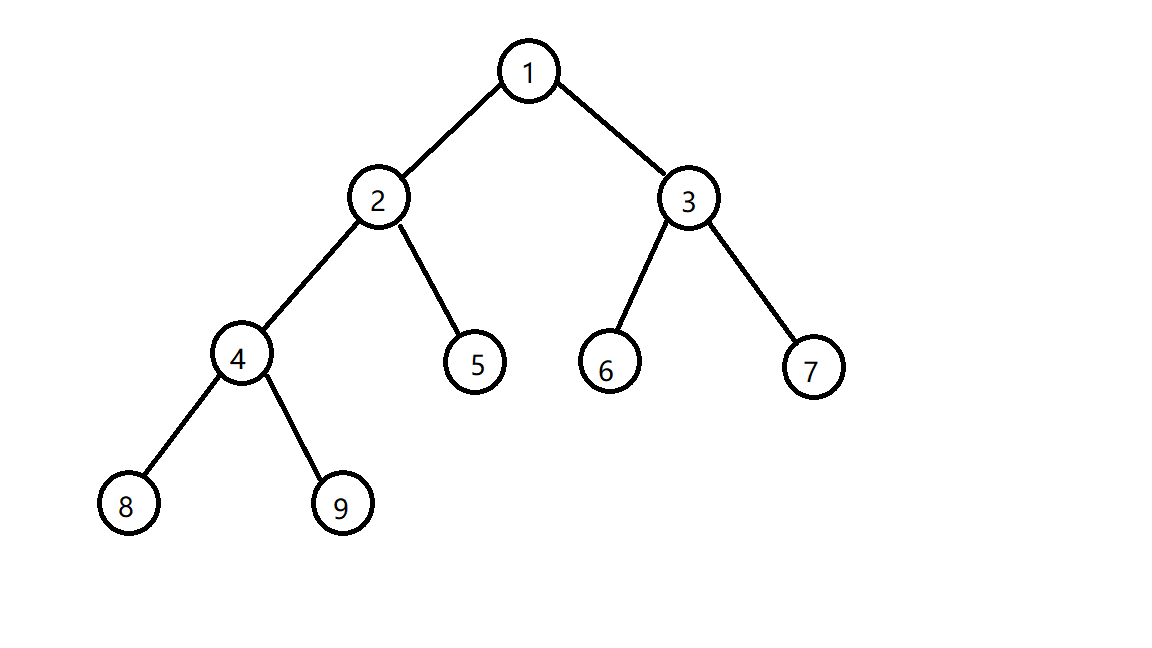
不难看出,对于堆的每个子树,它同样也是一个堆(因为是完全二叉树嘛)
二.堆的操作
1.插入
假设你已经有一个堆了,就是上面那个
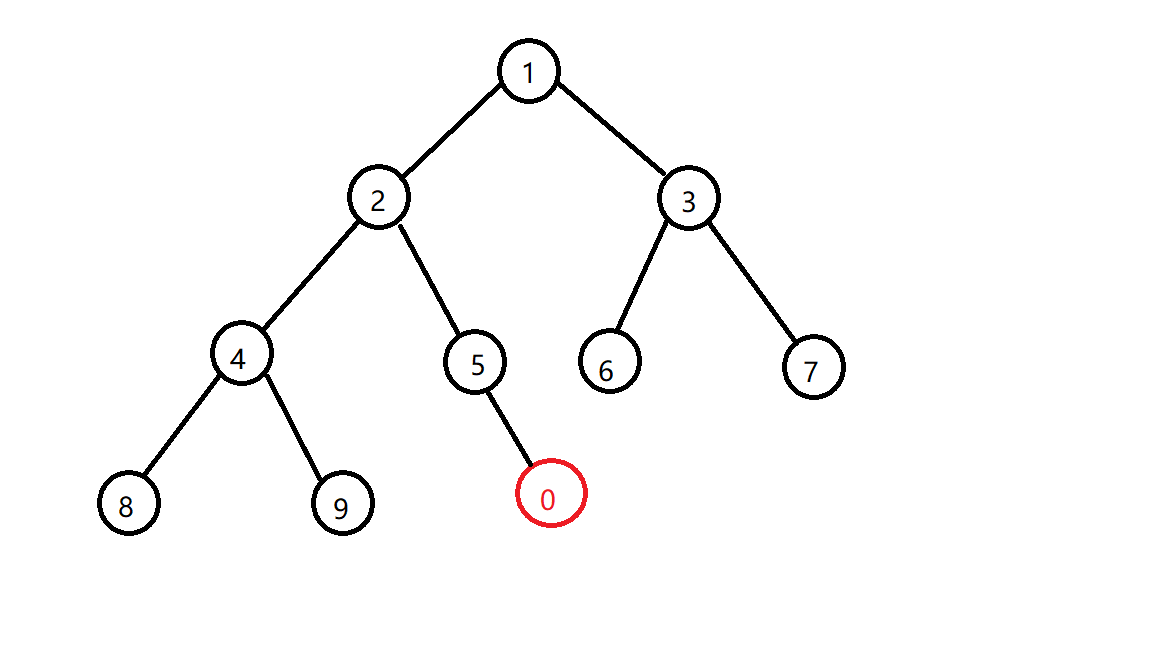
这个时候你如果想要给它加入一个节点怎么办,比如说0?
先插到堆底(严格意义上来说其实0是在5的左儿子的,图没画好放不下去,不过也不影响)
然后你会发现它比它的父亲小啊,那怎么办?不符合小根堆的性质了啊,那就交换一下他们的位置
交换之后还是发现不符合小根堆的性质,那么再换
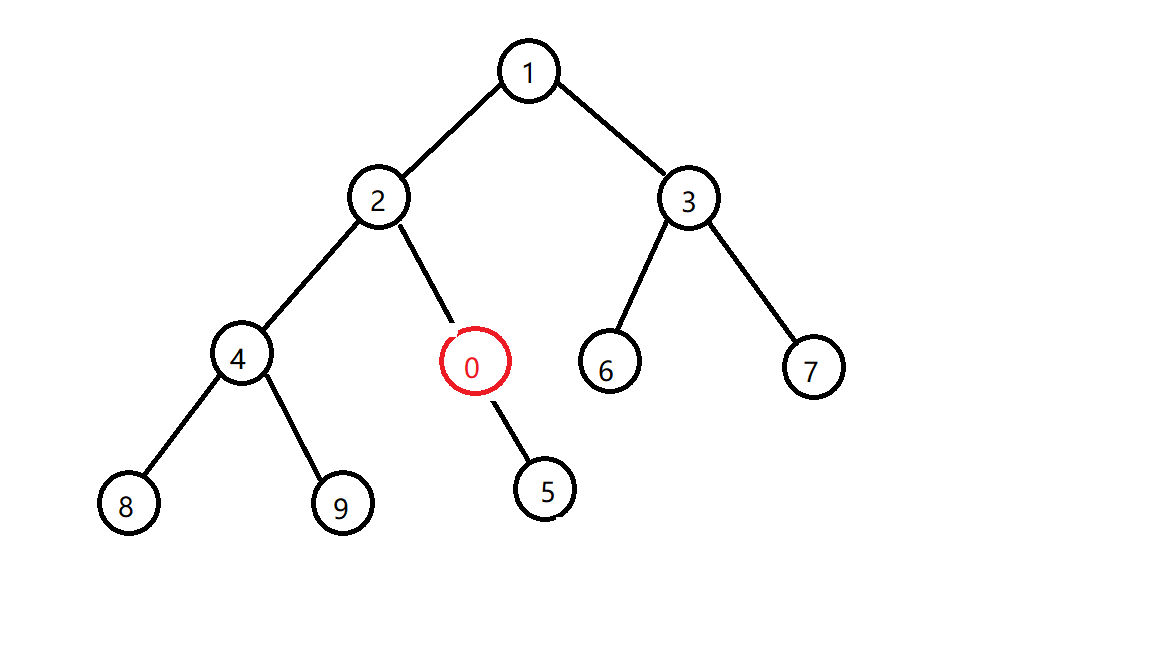
还是不行,再换
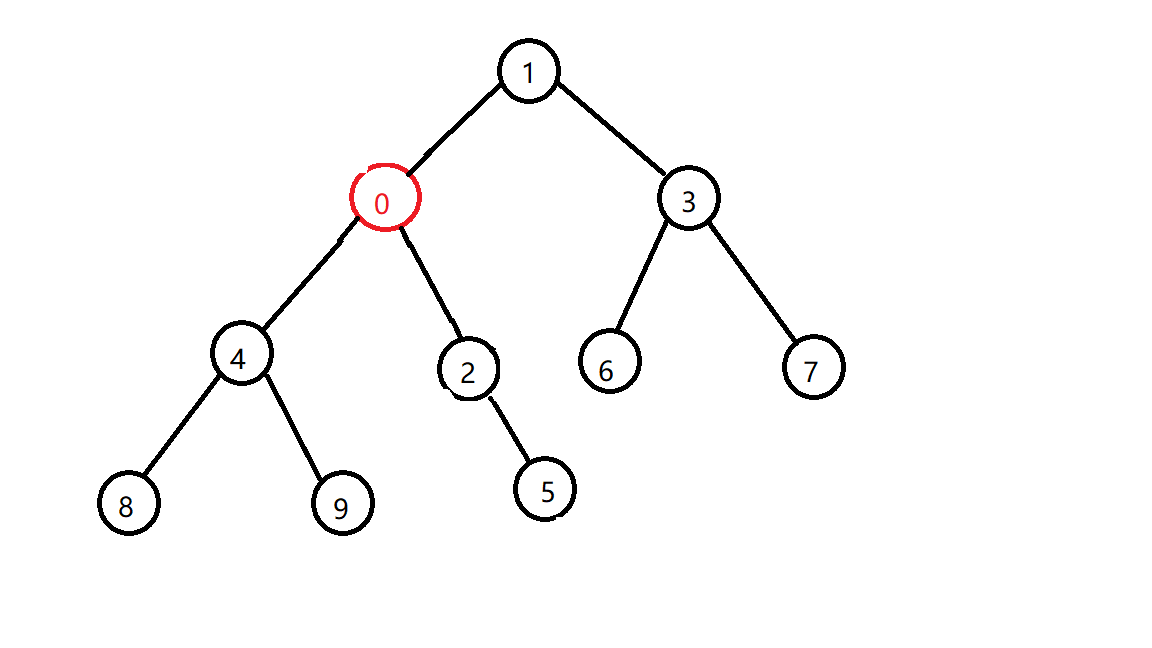
好了,这下就符合小根堆的性质了,是不是顺眼很多了?(假的,图越来越丑,原谅我不想再画)
事实上堆的插入就是把新的元素放到堆底,然后检查它是否符合堆的性质,如果符合就丢在那里了,如果不符合,那就和它的父亲交换一下,一直交换交换交换,直到符合堆的性质,那么就插入完成了
void swap(int &x,int &y){int t=x;x=y;y=t;}//交换函数
int heap[N];//定义一个数组来存堆
int siz;//堆的大小
void push(int x){//要插入的数
heap[++siz]=x;
now=siz;
//插入到堆底
while(now){//还没到根节点,还能交换
ll nxt=now>>1;//找到它的父亲
if(heap[nxt]>heap[now])swap(heap[nxt],heap[now]);//父亲比它大,那就交换
else break;//如果比它父亲小,那就代表着插入完成了
now=nxt;//交换
}
return;
}
2.删除
把0插入完以后,忽然你看这个0不爽了,本来都是正整数,怎么就混进来你这个0?
于是这时候你就想把它删除掉
怎么删除?在删除的过程中还是要维护小根堆的性质
如果你直接删掉了,那就没有堆顶了,这个堆就直接乱了,所以我们要保证删除后这一整个堆还是个完好的小根堆
首先在它的两个儿子里面,找一个比较小的,和它交换一下,但是还是没法删除,因为下方还有节点,那就继续交换
还是不行,再换
再换
好了,这个碍眼的东西终于的下面终于没有节点了,这时候直接把它扔掉就好了
这样我们就完成了删除操作,但是在实际的代码操作中,并不是这样进行删除操作的,有一定的微调,代码中是直接把堆顶和堆底交换一下,然后把交换后的堆顶不断与它的子节点交换,直到这个堆重新符合堆性质(但是上面的方式好理解啊)
手写堆的删除支持任意一个节点的删除,不过
void pop(){
swap(heap[siz],heap[1]);siz--;//交换堆顶和堆底,然后直接弹掉堆底
int now=1;
while((now<<1)<=siz){//对该节点进行向下交换的操作
int nxt=now<<1;//找出当前节点的左儿子
if(nxt+1<=siz&&heap[nxt+1]<heap[nxt])nxt++;//看看是要左儿子还是右儿子跟它换
if(heap[nxt]<heap[now])swap(heap[now],heap[nxt]);//如果不符合堆性质就换
else break;//否则就完成了
now=nxt;//往下一层继续向下交换
}
}
3.查询
因为我们一直维护着这个堆使它满足堆性质,而堆最简单的查询就是查询优先级最低/最高的元素,对于我们维护的这个堆
一般的题目里面查询操作是和删除操作捆绑的,查询完后顺便就删掉了,这个主要因题而异
三.堆的STL实现
这年头真的没几个人写手写堆(可能有情怀党?)
一是手写堆容易写错代码又多,二是
手写堆和STL的优先队列有什么 区别?没有区别
速度方面,手写堆会偏快一点,但是如果开了
定义一个优先队列:
priority_queue<int> Q;//这是一个大根堆Q
priority_queue<int,vector<int>,less<int> > q1;//这个也是大根堆q1
priority_queue<int,vector<int>,greater<int> >q;//这是一个小根堆q
优先队列的操作:
//q.push() 压入元素。
//q.pop() 弹出堆顶元素。
//q.top() 返回堆顶元素。
//q.empty() 返回是否为空(返回值 bool 类型)。
//q.size() 返回堆大小。
//q.modify(iterator, key) 修改迭代器位置的值。
//q.erase(iterator) 删除迭代器位置的值。
//q.join() 把另一个堆和当前堆合并并清空被合并的堆。
四.堆的复杂度
因为堆是一棵完全二叉树,所以对于一个节点数为n的堆,它的高度不会超过
所以对于插入,删除操作复杂度为
查询堆顶操作的复杂度为
五.堆的其他稀奇古怪的东西
首先要知道
#include <ext/pb_ds/assoc_container.hpp>
#include <ext/pb_ds/priority_queue.hpp>
万能头不能解决问题,只包含标准库的所有头文件,而
库中有主要有五种类型
__gnu_pbds::pairing_heap_tag A;
//配对堆push,pop效率较好push,join复杂度为O(1)但pop的最差复杂度很高
__gnu_pbds::binary_heap_tag B;
//二叉堆push,pop效率高
__gnu_pbds::binomial_heap_tag C;
//二项堆push,pop效率较差.但pop函数的时间复杂度最慢只有亚线性。
__gnu_pbds::rc_binomial_heap_tag D;
//冗余计数二项堆相比二项堆push,pop更差但是push O(1)
__gnu_pbds::thin_heap_tag E;
//斐波那契堆(注:合并堆的复杂度与斐波那契堆不同)适合图论算法
//在一些方面甚至优于斐波那契堆,不过由于封装过紧,常数大,反而在非图论算法上最劣.
还有一个小知识,就是可删堆
这个堆我自己也不会用
大家看代码就行了...
struct PQ{
priority_queue<int> val,delv;
void clear(){priority_queue<int> nv,nd;swap(nv,val);swap(nd,delv);}
void pop(int x){delv.push(x);}
void push(int x){val.push(x);}
int top(){
while(!delv.empty()&&delv.top()==val.top()) delv.pop(),val.pop();
return val.empty()?0:val.top();
}
};


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧