Apache Drill初探
Apache Drill初探
- 介绍
Apache Drill是一个开源的,对于Hadoop和NoSQL低延迟的SQL查询引擎。
Apache Drill 实现了 Google's Dremel.那么什么是Google's Dremel?网络中一段描述:Dremel 是Google 的"交互式"数据分析系统。可以组建成规模上千的集群,处理PB级别的数据。MapReduce处理一个数据,需要分钟级的时间。作为MapReduce的发起人,Google开发了Dremel将处理时间缩短到秒级,作为MapReduce的有力补充。Dremel作为Google BigQuery的report引擎,获得了很大的成功。
一些特性:
-
实时分析及快速应用开发
![]()
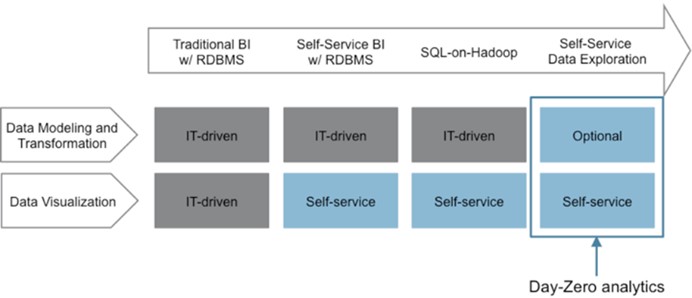
2.兼容已有的 SQL 环境和 Apache Hive
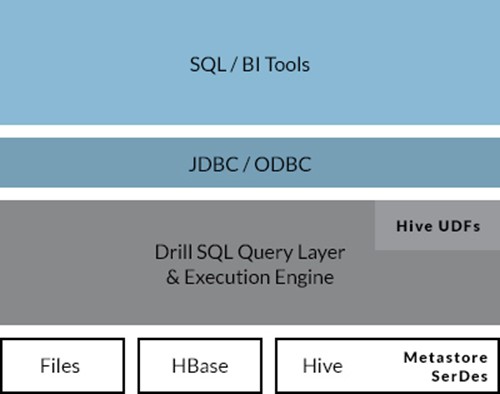
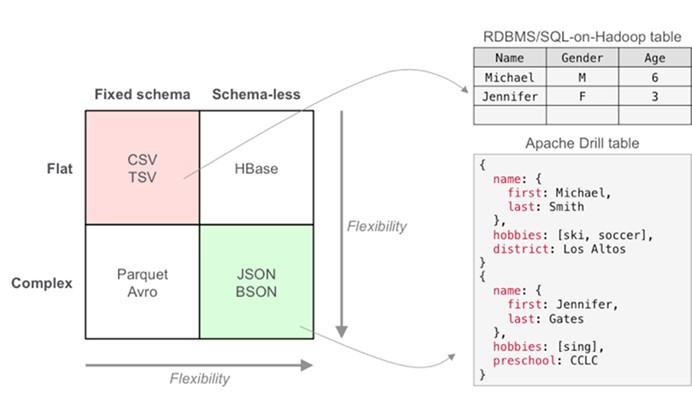
3.半结构化/嵌套数据结构
- 安装
- https://drill.apache.org/download/下载最新版Drill 0.7.0
-
单机模式运行,在drill 安装目录执行命令:
bin/sqlline -u jdbc:drill:zk=local -n admin -p admin
进入drill shell命令行交互模式:
![]()

输入!tables查看系统默认的一些表

查询实例表:SELECT * FROM cp.`employee.json` LIMIT 20;
安装成功!输入!quit命令退出。
分布式安装运行:
将drill-override-example.conf的内容复制到drill-override.conf
修改其中Zookeeper配置
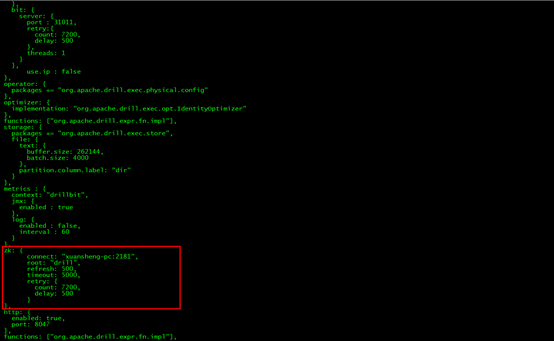
bin目录执行drillbit.sh即可
三、架构原理
1. Drill查询架构
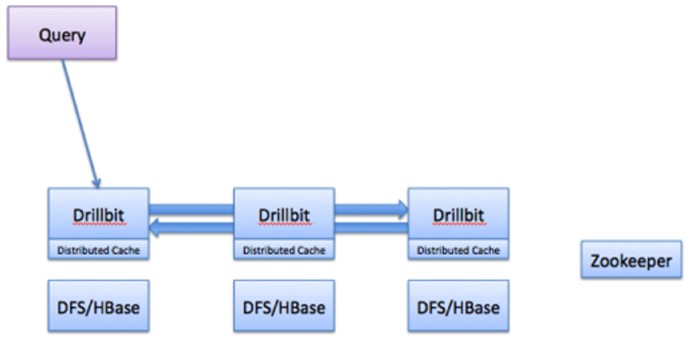
查询的流程常包括以下步骤:
- drill客户端发起查询,客户端可以是一个JDBC、ODBC、命令行界面或REST API。集群中任何drill单元可以接受来自客户端的查询,没有主从概念。
- drill单元对查询进行分析、优化,并针对快速高效执行生成一个最优的分布式执行计划。
- 收到请求的drill单元成为该查询的drill单元驱动节点。这个节点从ZooKeeper获取整个集群可用的一个drill单元列表。驱动节点确定合适的节点来执行各种查询计划片段到达最大化数据局部性。
- 各个节点查询片段执行计划按照它们的drill单元计划表执行。
- 各个节点完成它们的执行后返回结果数据给驱动节点。
- 驱动节点以流的形式将结果返回给客户端。
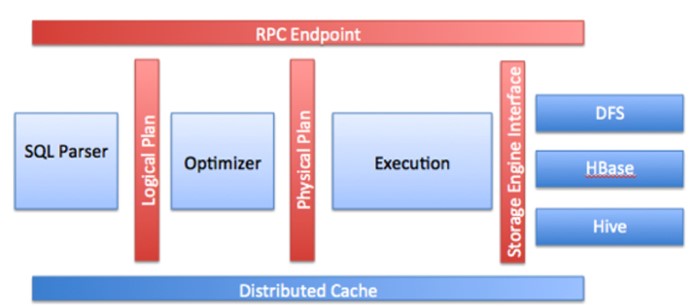
2.Drillbit核心模型
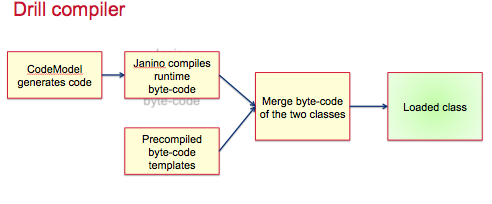
3. Drill 编译器
四、应用
1.Drill接口
①Drill shell (SQLLine)见安装部分
②Drill Web UI(安装目录命令行启动bin/sqlline -u jdbc:drill:zk=local -n admin -p admin)
进入查询窗口
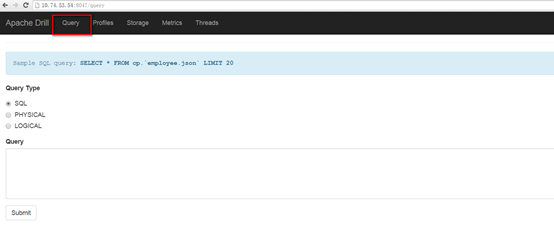
数据源设置
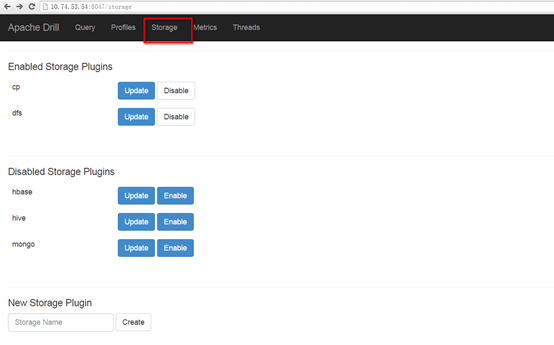
③ODBC & JDBC,可以在第三方应用配置相关的驱动直接连接
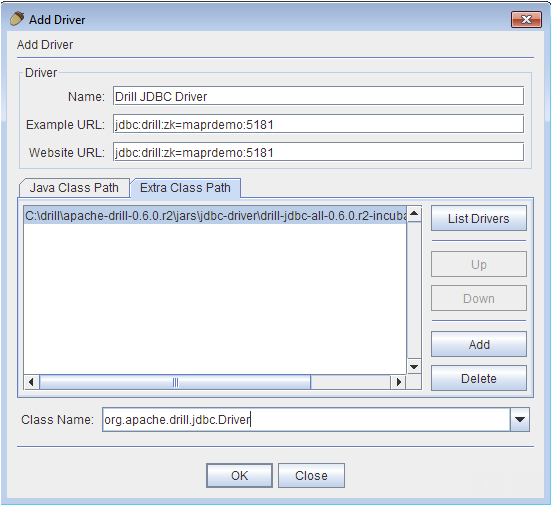
也可以使用编程模式, JDBC编程接口
加载驱动org.apache.drill.jdbc.Driver;使用Connection URL: jdbc:drill:zk=xuansheng-pc
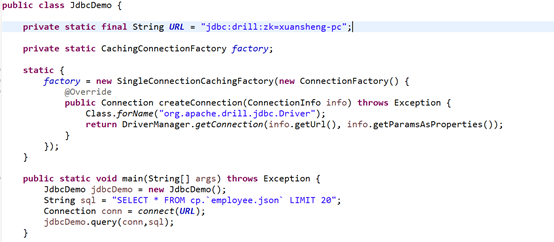
更多代码:
https://github.com/asinwang/drill-demo/blob/master/src/main/java/org/apache/drill/jdbc/JdbcDemo.java
④C++ API(没有看见相关资料,貌似还在开发中)
⑤REST接口
import org.apache.http.client.fluent.Content;
import org.apache.http.client.fluent.Request;
import org.apache.http.entity.ContentType;
import com.alibaba.fastjson.JSON;
public class RestDemo {
private static final String HOST_NAME = "http://xuansheng-pc:8047/query.json";
private static String buildRequestBody(String queryType, String query) {
RequestBody reques = new RequestBody(queryType, query);
String json = JSON.toJSON(reques).toString();
return json;
}
public static void main(String[] args) throws Exception {
String queryType = "SQL";
String query = "SELECT * FROM cp.`employee.json` LIMIT 20";
String buildRequestBody = buildRequestBody(queryType, query);
System.out.println("buildRequestBody:" + buildRequestBody);
Content returnContent = Request.Post(HOST_NAME).bodyString(buildRequestBody, ContentType.APPLICATION_JSON)
.execute().returnContent();
System.out.println(returnContent);
}
}
class RequestBody {
private String queryType;
private String query;
public RequestBody() {
}
public RequestBody(String queryType, String query) {
super();
this.queryType = queryType;
this.query = query;
}
public String getQueryType() {
return queryType;
}
public void setQueryType(String queryType) {
this.queryType = queryType;
}
public String getQuery() {
return query;
}
public void setQuery(String query) {
this.query = query;
}
}
-
连接Hbase、HDFS等
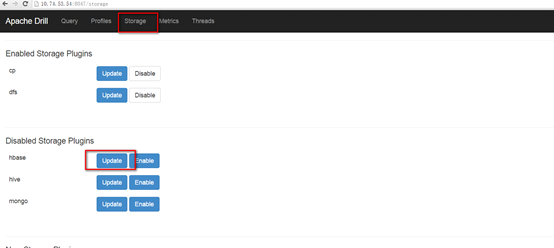
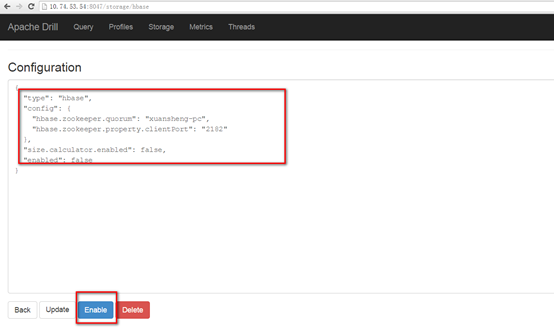
查询时使用对应的type作为命名空间即可
工程代码见:https://github.com/asinwang/drill-demo.git
相关资源


 浙公网安备 33010602011771号
浙公网安备 33010602011771号