
R自动数据收集第二章HTML笔记1(主要关于handler处理器函数和帮助文档所有示例)
本文知识点:
1潜在畸形页面使用htmlTreeParse函数
2startElement的用法
3闭包
4handler函数的命令和函数体主要写法
5节点的丢弃,取出,取出标签名称、属性、属性值、内容
6修改树中节点的属性、节点计数、存储节点
7匿名函数写法
8xmlHashTree函数和xmlRoot函数和trun参数(此条存疑)
9编码
10try和trycatch,中断
11xinclude
原书中虽然主要是关于HTML的,但是我想把重心放在2.4解析一节的内容,进行扩充和增加自己的理解。
==========================================================================
一、HTML部分简要的摘抄几条吧
1在chrome(chrome的效果相对比用360极速好,虽然内核一致),选中一行文本,右键检查(inspect),就可以选中对应的那一行HTML源码2Attributes are always placed within the start tag right after the tag name. A tag can hold multiple attributes that are simply separated by a space character. Attributes are expressed as name–value pairs, as in name="value". The value can either be enclosed by single or double quotation marks. However, if the attribute value itself contains one type of quotation mark, the other type has to be used to enclose the value:
3
Spaces and line breaks in HTML source code do not translate directly into spaces and line
breaks in the browser presentation. While line breaks are ignored altogether, any number
of consecutive spaces are presented as a single space
以下是本章用到的HTML文件的链接
二、 关于使用R
读取页面:
url <- "http://www.r-datacollection.com/materials/html/fortunes.html"> fortunes <- readLines(con = url)> fortunes[1] "<!DOCTYPE HTML PUBLIC \"-//IETF//DTD HTML//EN\">"[2] "<html> <head>"[3] "<title>Collected R wisdoms</title>"[4] "</head>"[5] ""[6] "<body>"[7] "<div id=\"R Inventor\" lang=\"english\" date=\"June/2003\">"[8] " <h1>Robert Gentleman</h1>"[9] " <p><i>'What we have is nice, but we need something very different'</i></p>"[10] " <p><b>Source: </b>Statistical Computing 2003, Reisensburg"[11] "</div>"[12] ""[13] "<div lang=english date=\"October/2011\">"[14] " <h1>Rolf Turner</h1>"[15] " <p><i>'R is wonderful, but it cannot work magic'</i> <br><emph>answering a request for automatic generation of 'data from a known mean and 95% CI'</emph></p>"[16] " <p><b>Source: </b><a href=\"https://stat.ethz.ch/mailman/listinfo/r-help\">R-help</a></p>"[17] "</div>"[18] ""[19] "<address><a href=\"www.r-datacollectionbook.com\"><i>The book homepage</i><a/></address>"[20] ""[21] "</body> </html>"
上面的结果有两个问题(以浅蓝色底纹标出):
问题1:部分属性的值未有加上引号
问题2:漏了第二个段落标签的结束标签</p>
此处,readLines函数是将输入文件的每一行映射到一个字符向量的元素里,也就是说,向量fortunes的每一个元素就是一行HTML代码。
正因为上述的问题,我们使用以下方式解析:
> library(XML)> parsed_fortunes <- htmlParse(file = url)> print(parsed_fortunes)
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN"><html><head><title>Collected R wisdoms</title></head><body><div id="R Inventor" lang="english" date="June/2003"><h1>Robert Gentleman</h1><p><i>'What we have is nice, but we need something very different'</i></p><p><b>Source: </b>Statistical Computing 2003, Reisensburg</p></div><div lang="english" date="October/2011"><h1>Rolf Turner</h1><p><i>'R is wonderful, but it cannot work magic'</i> <br><emph>answering a request for automatic generation of 'data from a known mean and 95% CI'</emph></p><p><b>Source: </b><a href="https://stat.ethz.ch/mailman/listinfo/r-help">R-help</a></p></div><address><a href="www.r-datacollectionbook.com"><i>The book homepage</i></a><a></a></address></body></html>
此时OK。
看一下的说明描述
Parses an XML or HTML file or string containing XML/HTML content, and generates an R structure representing the XML/HTML tree. Use htmlTreeParse when the content is known to be (potentially malformed潜在畸形的) HTML. This function has numerous parameters/options and operates quite differently based on their values. It can create trees in R or using internal C-level nodes, both of which are useful in different contexts. It can perform conversion of the nodes into R objects using caller-specified handler functions and this can be used to map the XML document directly into R data structures, by-passing the conversion to an R-level tree which would then be processed recursively or with multiple descents to extract the information of interest.
由于我们在抓取网页的时候,并不需要所有的数据,且为了加快运行速度,我们在构建树的阶段,就通过处理函数只提取我们感兴趣的节点。
htmlTreeParse函数的具体源码我们在另一篇笔记中详细展开。
下面先来看下处理函数
例子1
#代码片段3h1 <- list("body" = function(x){NULL})parsed_fortunes <- htmlTreeParse(url, handlers = h1, asTree = TRUE)parsed_fortunes$children# $html# <html># <head># <title>Collected R wisdoms</title># </head># </html>
写成h1 <- list(body = function(x){NULL})是一样的
也就是遇到body标签的时候返回空,这样相当于删掉了body标签(包括其子标签)
XML节点会被传递给x
注意,R的函数的特点是最后一行语句作为返回值(这样就可以不必写return(xxx)啦)
例子2
h2 <- list(startElement = function(node, ...){name <- xmlName(node)if(name %in% c("div", "title")){NULL}else{node}},comment = function(node){NULL})parsed_fortunes <- htmlTreeParse(file = url, handlers = h2, asTree = TRUE)parsed_fortunes$children
$html<html><head/><body><address><a href="www.r-datacollectionbook.com"><i>The book homepage</i></a><a/></address></body></html>
其中:
?'%in%'
%in% is a more intuitive interface(更直观的形式) as a binary operator, which returns a logical vector indicating if there is a match or not for its left operand.
%in%的作用和match函数是一样的(在另一篇笔记中有介绍)
XML节点会被传递给x,node不过是个形参而已
函数的作用是将div, title节点删除,将注释删除
其中:xmlName是获取当前节点的名字,同类的函数还有:
xmlChildren当前节点的子节点(子节点们)
xmlAttrs当前节点的属性(返回name-value pairs的形式的字符串向量)
xmlValue当前节点的值(就是被标签包裹的内容啦)
(通过See Also)
此时
例子1.1
h1 <- list("body" = function(x){print('here is a body tag')NULL})parsed_fortunes <- htmlTreeParse(url, handlers = h1, asTree = TRUE)[1] "here is a body tag"
可以看到body函数在遇到名为body的标签的时候被调用
例子2.1
#测试startElement的用法
i <- 0h2 <- list(startElement = function(node, ...){i <<- i + 1print(paste("here is the ",i, "st tag,its name is",xmlName(node)))NULL}# comment = function(node){# print(paste("here is a comment,its name is",xmlName(node)))# NULL# })parsed_fortunes <- htmlTreeParse(file = url, handlers = h2, asTree = TRUE)[1] "here is the 1 st tag,its name is title"[1] "here is the 2 st tag,its name is head"[1] "here is the 3 st tag,its name is h1"[1] "here is the 4 st tag,its name is i"[1] "here is the 5 st tag,its name is p"[1] "here is the 6 st tag,its name is b"[1] "here is the 7 st tag,its name is p"[1] "here is the 8 st tag,its name is div"[1] "here is the 9 st tag,its name is h1"[1] "here is the 10 st tag,its name is i"[1] "here is the 11 st tag,its name is br"[1] "here is the 12 st tag,its name is emph"[1] "here is the 13 st tag,its name is p"[1] "here is the 14 st tag,its name is b"[1] "here is the 15 st tag,its name is a"[1] "here is the 16 st tag,its name is p"[1] "here is the 17 st tag,its name is div"[1] "here is the 18 st tag,its name is i"[1] "here is the 19 st tag,its name is a"[1] "here is the 20 st tag,its name is a"[1] "here is the 21 st tag,its name is address"[1] "here is the 22 st tag,its name is body"[1] "here is the 23 st tag,its name is html"
我们可以看到,遇到任意一个标签的时候,startElement就被调用了,真是人如其名啊,start元素~
而且,我们的标签被认作节点是以遇到其结束标签开始的。
(这里为了解决变量作用域的问题,用了超赋值运算符)
至于他是怎么被调用的,那肯定是在C/C++中写好了吧,如果是在java中,就应该是集合容器的遍历
例子3
getItalics = function() {i_container = character()list(i = function(node, ...) {i_container <<- c(i_container, xmlValue(node))}, returnI = function() i_container)}h3 <- getItalics()invisible(htmlTreeParse(url, handlers = h3))h3$returnI()[1] "'What we have is nice, but we need something very different'"[2] "'R is wonderful, but it cannot work magic'"[3] "The book homepage"
这里书上提到使用了闭包,关于闭包,请参见《R语言编程艺术》P147
也可以再参考下:《R Language Definition》
讲真,我觉得书上和官方的说法是有出入的
另外在R-help也提到了,是和官方一直的
另外这个号称esoteric R的链接中的两篇文章也可以一看:

呃,其实我自己还没看完呢,等我看完书再回头来看~
JS角度的闭包也可以作为参考
关键在于函数的命名
该处理函数的作用即取出标签i中的值
其中i_container <<- c(i_container, xmlValue(node))的意思是?
我们来看个例子:
> a = character()> b<-c(a,'2')> b[1] "2"> c<-c(b,'3')> c[1] "2" "3"> acharacter(0)> b[1] "2"
也就是说i_container <<- c(i_container, xmlValue(node))的作用是将i_container和节点值结合,这里的c(),就是在原来的基础上添加了。这样可以保持变量名不变,貌似比用下标对向量元素赋值快捷。
invisible是使得输出不可见
有木有觉得
, returnI = function() i_container)
这样的写法也很神奇?
这样的写法也很神奇?
源码文件:

实际上,就算我下载包的说明的pdf,也仅仅是便于检索,其目录书签帮助我们看到有哪些函数,并不能深入了解太多。
===================================================================
三、帮助文档的摘要补充
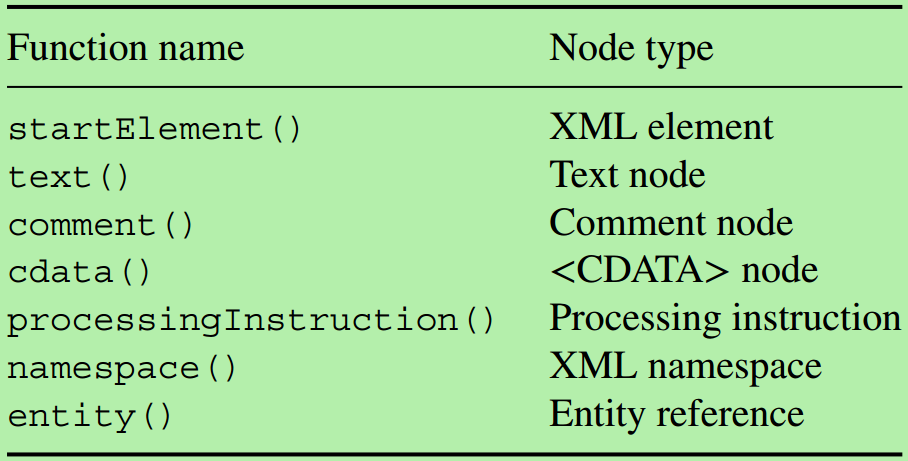
The handlers argument is used similarly to those specified in xmlEventParse. When an XML tag (element) is processed, we look for a function in this collection with the same name as the tag's name. If this is not found, we look for one named startElement. If this is not found, we use the default built in converter(变换器). The same works for comments, entity references, cdata, processing instructions, etc. The default entries should be named comment, startElement, externalEntity, processingInstruction, text, cdata and namespace. All but the last should take the XMLnode as their first argument. In the future, other information may be passed via ..., for example, the depth in the tree, etc. Specifically, the second argument will be the parent node into which they are being added, but this is not currently implemented, so should have a default value (NULL).
当一个标签被处理时,在函数集里1先找和标签同名的函数,2找startElement,最后才找默认的函数
当一个注释等被处理时,也是一样。那么也就是说,比如处理注释的时候,先找叫comment的函数呗,
所以,handler中的函数命名(列表的组件名)是需要讲规律的
这些函数的第一个参数必须接受node(即所谓的take吧)。
嗯,这一段讲的很好~,把handler函数怎么编写讲清楚了。
再看个文档里面的一段
children
A list of the XML nodes at the top of the document. Each of these is of class XMLNode. These are made up of 4 fields.
name The name of the element.attributes For regular elements, a named list of XML attributes converted from the <tag x="1" y="abc">children List of sub-nodes.value Used only for text entries.Some nodes specializations of XMLNode, such as XMLComment, XMLProcessingInstruction, XMLEntityRef are used.
If the value of the argument getDTD is TRUE and the document refers to a DTD via a top-level DOCTYPE element, the DTD and its information will be available in the dtd field. The second element is a list containing the external and internal DTDs. Each of these contains 2 lists - one for element definitions and another for entities. See parseDTD.
If a list of functions is given via handlers, this list is returned. Typically, these handler functions share state via a closure and the resulting updated data structures which contain the extracted and processed values from the XML document can be retrieved via a function in this handler list.
If asTree is TRUE, then the converted tree is returned. What form this takes depends on what the handler functions have done to process the XML tree.
有意思的问答:How to write trycatch in R
========================================================================
四、样例
我们先看一下test.xml的内容:
<?xml version="1.0" ?><!DOCTYPE foo [<!ENTITY % bar "for R and S"><!ENTITY % foo "for Omegahat"><!ENTITY testEnt "test entity bar"><!ENTITY logo SYSTEM "images/logo.gif" NDATA gif><!ENTITY % extEnt SYSTEM "http://www.omegahat.net"> <!-- include the contents of the README file in the same directory as this one. --><!ELEMENT x (#PCDATA) ><!ELEMENT y (x)* >]><!-- A comment --><foo x="1"><element attrib1="my value" />&testEnt;<?R sum(rnorm(100)) ?><a><!-- A comment --><b>%extEnt;</b></a><![CDATA[This is escaped datacontaining < and &.]]>Note that this caused a segmentation fault if replaceEntities wasnot TRUE.That is,<code>xmlTreeParse("test.xml", replaceEntities = TRUE)</code>works, but<code>xmlTreeParse("test.xml")</code>does not if this is called before the one above.This is now fixed and was caused bytreating an xmlNodePtr in the C codethat had type XML_ELEMENT_DECLand so was in fact an xmlElementPtr.Aaah, C and casting!</foo>
fileName <- system.file("exampleData", "test.xml", package="XML")# parse the document and return it in its standard format.xmlTreeParse(fileName)# parse the document, discarding comments.xmlTreeParse(fileName, handlers=list("comment"=function(x,...){NULL}), asTree = TRUE)
# print the entitiesinvisible(xmlTreeParse(fileName,handlers=list(entity=function(x) {cat("In entity",x$name, x$value,"\n")x}), asTree = TRUE))
什么是entry?好吧,检索了下笔记,当初自学XML的时候没学到....但愿本书后续章节会讲解~
其取名和值的方式好直接~所以我试验了,其实上面的处理函数中xmlName(node)直接改为node$name也是OK的。
# Parse some XML text.# Read the text from the filexmlText <- paste(readLines(fileName), "\n", collapse="")print(xmlText)xmlTreeParse(xmlText, asText=TRUE)# with version 1.4.2 we can pass the contents of an XML# stream without pasting them.xmlTreeParse(readLines(fileName), asText=TRUE)
这个也没什么可说的
# Read a MathML document and convert each node# so that the primary class is# <name of tag>MathML# so that we can use method dispatching when processing# it rather than conditional statements on the tag name.# See plotMathML() in examples/.fileName <- system.file("exampleData", "mathml.xml",package="XML")m <- xmlTreeParse(fileName,handlers=list(startElement = function(node){cname <- paste(xmlName(node),"MathML", sep="",collapse="")class(node) <- c(cname, class(node));node}))
# In this example, we extract _just_ the names of the# variables in the mtcars.xml file.# The names are the contents of the <variable>tags.- # We discard all other tags by returning NULL
# from the startElement handler.## We cumulate the names of variables in a charactervector named `vars'.# We define this within a closure and define the# variable function within that closure so that it# will be invoked when the parser encounters a <variable>tag.# This is called with 2 arguments: the XMLNode object (containingits children) and- # the list of attributes.
# We get the variable name via call to xmlValue().# Note that we define the closure function in the call and then# create an instance of it by calling it directly as# (function() {...})()# Note that we can get the names by parsing# in the usual manner and the entire document and then executing# xmlSApply(xmlRoot(doc)[[1]], function(x) xmlValue(x[[1]]))# which is simpler but is more costly in terms of memory.fileName <- system.file("exampleData", "mtcars.xml", package="XML")doc <- xmlTreeParse(fileName,handlers = (function() {vars <- character(0) ;list(variable=function(x, attrs) {vars <<- c(vars, xmlValue(x[[1]]));print(vars)},startElement=function(x,attr){NULL},names = function() {vars})})())[1] "mpg"[1] "mpg" "cyl"[1] "mpg" "cyl" "disp"[1] "mpg" "cyl" "disp" "hp"[1] "mpg" "cyl" "disp" "hp" "drat"[1] "mpg" "cyl" "disp" "hp" "drat" "wt"[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec"[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs"[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am"[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb"
其中mtcars.xml中的数据如下:
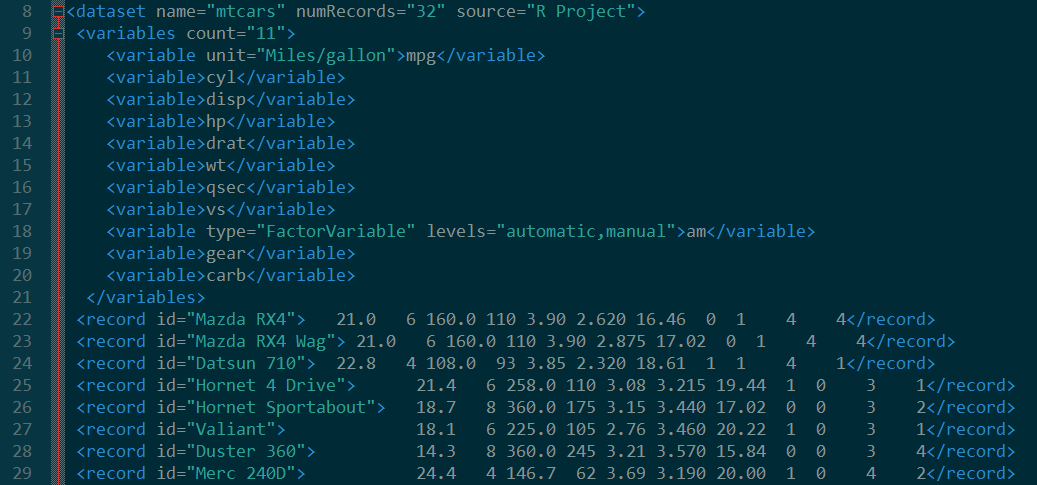
该函数是取出variable节点中的值,然后将其余节点都删除
注意这种匿名函数的写法
handlers = (function(){})()
# Here we just print the variable names to the console# with a special handler.doc <- xmlTreeParse(fileName, handlers = list(variable=function(x, attrs) {print(xmlValue(x[[1]])); TRUE}), asTree=TRUE)
其实我觉得哪里需要那几个多余的啊,直接这样效果是一样滴:
doc <- xmlTreeParse(fileName,handlers = list(variable=function(x, attrs) {print(xmlValue(x[[1]]))}))[1] "mpg"[1] "cyl"[1] "disp"[1] "hp"[1] "drat"[1] "wt"[1] "qsec"[1] "vs"[1] "am"[1] "gear"[1] "carb"
# This should raise an error.
try(xmlTreeParse(system.file("exampleData", "TestInvalid.xml", package="XML"),validate=TRUE))
然而并没有发生错误
## Not run:
# Parse an XML document directly from a URL.# Requires Internet access.xmlTreeParse("http://www.omegahat.net/Scripts/Data/mtcars.xml", asText=TRUE)Error: XML content does not seem to be XML: 'http://www.omegahat.net/Scripts/Data/mtcars.xml'
是asText=TRUE参数再作怪~
counter = function() {counts = integer(0)list(startElement = function(node) {name = xmlName(node)if(name %in% names(counts))counts[name] <<- counts[name] + 1elsecounts[name] <<- 1},counts = function() counts)}h = counter()invisible(xmlParse(system.file("exampleData", "mtcars.xml", package="XML"),handlers = h))h$counts()variable variables record dataset22 2 64 2
这个处理函数的作用对不同节点进行计数
counts[name]这样的写法挺有意思的
getLinks = function() {links = character()list(a = function(node, ...) {links <<- c(links, xmlGetAttr(node, "href"))node},links = function()links)}h1 = getLinks()invisible(htmlTreeParse(system.file("examples", "index.html", package = "XML"),handlers = h1))h1$links()[1] "XML_0.97-0.tar.gz"[2] "XML_0.97-0.zip"[3] "XML_0.97-0.tar.gz"[4] "XML_0.97-0.zip"[5] "Overview.html"[6] "manual.pdf"[7] "Tour.pdf"[8] "description.pdf"[9] "WritingXML.html"[10] "FAQ.html"[11] "Changes"[12] "http://cm.bell-labs.com/stat/duncan"[13] "mailto:duncan@wald.ucdavis.edu"
获取属性href的值
紧接其上:
h2 = getLinks()htmlTreeParse(system.file("examples", "index.html", package = "XML"),handlers = h2, useInternalNodes = TRUE)all(h1$links() == h2$links())[1] TRUE
# Using flat treestt = xmlHashTree()f = system.file("exampleData", "mtcars.xml", package="XML")xmlTreeParse(f, handlers = list(.startElement = tt[[".addNode"]]))####输出了处理函数本身,加了asTree = TRUE貌似也没效果啊tt #这个是我自己加的命令<variable/>xmlRoot(tt)<variable/>
tt[[".addNode"]]是取到了xmlHashTree中的.addNode函数,可以直接通过这个命令查看
那么.addNode字面意思是添加节点,是怎么添加的呢?
先看xmlHashTree函数:
These (and related internal) functions allow us to represent trees as a simple, non-hierarchical collection of nodes along with corresponding tables that identify the parent and child relationships.
这些函数,可以让用一个简单的非层次结构的节点集合来表示树,通过tables区分字父节点
(我观察函数名,怎么感觉是用哈希结构来存储树呢),再往后查找。
The function .addNode is used to insert a new node into the tree.
再看xmlRoot函数:
xmlRoot(x, skip = TRUE, ...)
These are a collection of methods for providing easy access to the top-level XMLNode object resulting from parsing an XML document
x
the object whose root/top-level XML node is to be returned.
也就是说,返回传入对象的根节点或者顶层节点。我们可以查看tt对象的属性来验证
> class(tt)[1] "XMLHashTree" "XMLAbstractDocument"
但这个.addNode到底怎么添加的呢?貌似这段代码什么都没做,而根节点却跑到tt对象里面去了.....
这点我没搞明白。
那么我们这样理解吧,tt作为一个全局变量,其本身是等于xmlHashTree(),即tt = xmlHashTree()
那么tt[[".addNode"]]即xmlHashTree()调用.addNode函数,而.startElement会在每一个节点调用,所以tt其实每次等于返回值,最后一次.addNode函数的返回值是<variable/>,所以,tt是<variable/>
那为什么.addNode的返回值,会是xmlHashTree()的返回值呢
function (nodes = list(), parents = character(), children = list(),env = new.env(TRUE, parent = emptyenv())){.count = 0env$.children = .children = new.env(TRUE)env$.parents = .parents = new.env(TRUE)f = function(suggestion = "") {if (suggestion == "" || exists(suggestion, env, inherits = FALSE))as.character(.count + 1)else suggestion}assign(".nodeIdGenerator", f, env)addNode = function(node, parent = character(), ..., attrs = NULL,namespace = NULL, namespaceDefinitions = character(),.children = list(...), cdata = FALSE, suppressNamespaceWarning = getOption("suppressXMLNamespaceWarning",FALSE)) {if (is.character(node))node = xmlNode(node, attrs = attrs, namespace = namespace,namespaceDefinitions = namespaceDefinitions).kids = .children.children = .this$.childrennode = asXMLTreeNode(node, .this, className = "XMLHashTreeNode")id = node$idassign(id, node, env).count <<- .count + 1if (!inherits(parent, "XMLNode") && (!is.environment(parent) &&length(parent) == 0) || parent == "")return(node)if (inherits(parent, "XMLHashTreeNode"))parent = parent$idif (length(parent)) {assign(id, parent, envir = .parents)if (exists(parent, .children, inherits = FALSE))tmp = c(get(parent, .children), id)else tmp = idassign(parent, tmp, .children)}return(node)}env$.addNode <- addNode.tidy = function() {idx <- idx - 1length(nodeSet) <- idxlength(nodeNames) <- idxnames(nodeSet) <- nodeNames.nodes <<- nodeSetidx}.this = structure(env, class = oldClass("XMLHashTree")).this}
好吧,感觉我是找对了线,但是还是不是很通顺,用过还是和变量的环境有关。
暂时搁置下。
f = system.file("exampleData", "mtcars.xml", package="XML")doc = xmlTreeParse(f, useInternalNodes = TRUE)sapply(getNodeSet(doc, "//variable"), xmlValue)[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am"[10] "gear" "carb"
其实就是从doc中其成绩variable标签对象,即得到的是节点,然后将节点传递xmlValue給函数,取得节点的值。
# character set encoding for HTMLf = system.file("exampleData", "9003.html", package = "XML")# we specify the encodingd = htmlTreeParse(f, encoding = "UTF-8")# get a different result if we do not specify any encodingd.no = htmlTreeParse(f)# document with its encoding in the HEAD of the document.d.self = htmlTreeParse(system.file("exampleData", "9003-en.html",package = "XML"))# XXX want to do a test here to see the similarities between d and# d.self and differences between d.no
其中nodes1.xml
<x xmlns:xinclude="http://www.w3.org/2001/XInclude"><!-- Simple test of including a set of nodes from an XML document --><xinclude:include href="something.xml#xpointer(//p)" /></x>
其中nodes2.xml
<x xmlns:xinclude="http://www.w3.org/2001/XInclude"><!-- Simple test of including a set of nodes from an XML document --><xinclude:include href="doesnt_exist.xml#xpointer(//p)"><xinclude:fallback>Some <i>fallback text</i></xinclude:fallback></xinclude:include></x>
# includef = system.file("exampleData", "nodes1.xml", package = "XML")xmlRoot(xmlTreeParse(f, xinclude = FALSE))<x xmlns:xinclude="http://www.w3.org/2001/XInclude"><!--Simple test of including a set of nodes from an XML document--><xinclude:include href="something.xml#xpointer(//p)"/></x>xmlRoot(xmlTreeParse(f, xinclude = TRUE))<x xmlns:xinclude="http://www.w3.org/2001/XInclude"><!--Simple test of including a set of nodes from an XML document--><p ID="author">something</p><p>really</p><p>simple</p></x>f = system.file("exampleData", "nodes2.xml", package = "XML")xmlRoot(xmlTreeParse(f, xinclude = TRUE))failed to load external entity "D:/RSets/R-3.3.2/library/XML/exampleData/doesnt_exist.xml"<x xmlns:xinclude="http://www.w3.org/2001/XInclude"><!--Simple test of including a set of nodes from an XML document-->Some<i>fallback text</i></x>
xinclude
a logical value indicating whether to process nodes of the form <xi:include xmlns:xi="http://www.w3.org/2001/XInclude"> to insert content from other parts of (potentially different) documents. TRUE means resolve the external references; FALSE means leave the node as is. Of course, one can process these nodes oneself after document has been parse using handler functions or working on the DOM. Please note that the syntax for inclusion using XPointer is not the same as XPath and the results can be a little unexpected and confusing. See the libxml2 documentation for more details.
我们来看看所谓的resolve(分解)
<xinclude:include href="something.xml#xpointer(//p)"/>
即something.xml下的标签p,而something.xml文件如下
<doc><p ID="author">something</p><p>really</p><foo>bar</foo><p>simple</p></doc>
而在nodes2.xml的例子中
<xinclude:include href="doesnt_exist.xml#xpointer(//p)"><xinclude:fallback>
Some <i>fallback text</i></xinclude:fallback></xinclude:include>
是因为并没有一个叫做doesnt_exist.xml的文件,而第二个标签没有href
# Errors
try(xmlTreeParse("<doc><a> & < <?pi > </doc>"))xmlParseEntityRef: no nameStartTag: invalid element nameParsePI: PI pi never end ...Premature end of data in tag a line 1Premature end of data in tag doc line 1Error : 1: xmlParseEntityRef: no name2: StartTag: invalid element name3: ParsePI: PI pi never end ...4: Premature end of data in tag a line 15: Premature end of data in tag doc line 1
# catch the error by type.
tryCatch(xmlTreeParse("<doc><a> & < <?pi > </doc>"),"XMLParserErrorList" = function(e) {cat("Errors in XML document\n", e$message, "\n")})xmlParseEntityRef: no nameStartTag: invalid element nameParsePI: PI pi never end ...Premature end of data in tag a line 1Premature end of data in tag doc line 1Error : in XML document1: xmlParseEntityRef: no name2: StartTag: invalid element name3: ParsePI: PI pi never end ...4: Premature end of data in tag a line 15: Premature end of data in tag doc line 1
通过XMLParserErrorList函数,捕获参数e,即为是否有报错的标志,e$message提取到的是错误信息,即:1 2 3 4 5这些条.....
# terminate on first error
try(xmlTreeParse("<doc><a> & < <?pi > </doc>", error = NULL))Error : xmlParseEntityRef: no name
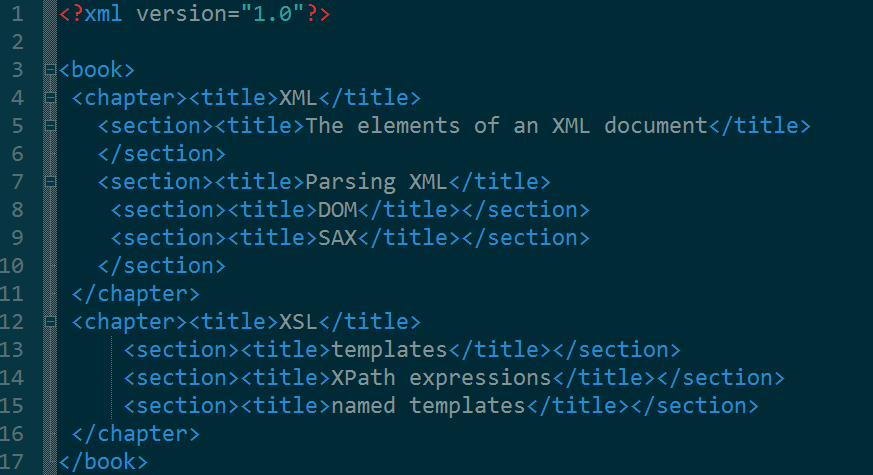
f = system.file("exampleData", "book.xml", package = "XML")doc.trim = xmlInternalTreeParse(f, trim = TRUE)doc = xmlInternalTreeParse(f, trim = FALSE)xmlSApply(xmlRoot(doc.trim), class)chapter chapter[1,] "XMLInternalElementNode" "XMLInternalElementNode"[2,] "XMLInternalNode" "XMLInternalNode"[3,] "XMLAbstractNode" "XMLAbstractNode"xmlSApply(xmlRoot(doc), class)text chapter[1,] "XMLInternalTextNode" "XMLInternalElementNode"[2,] "XMLInternalNode" "XMLInternalNode"[3,] "XMLAbstractNode" "XMLAbstractNode"text chapter[1,] "XMLInternalTextNode" "XMLInternalElementNode"[2,] "XMLInternalNode" "XMLInternalNode"[3,] "XMLAbstractNode" "XMLAbstractNode"text[1,] "XMLInternalTextNode"[2,] "XMLInternalNode"[3,] "XMLAbstractNode"
trim参数
whether to strip white space from the beginning and end of text strings.
是否清楚开始和结束文本字符之间的空格
book,xml中如下,而doc的输出和其一致
而doc.trim的输出是这样子的:啊,感觉其把原来紧凑的都給空格隔开啦
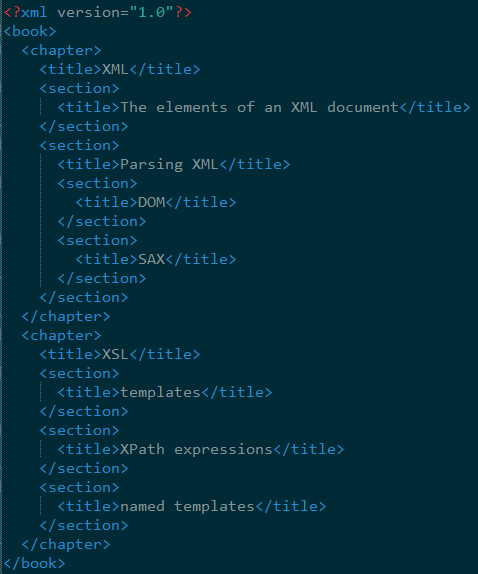
感觉是不是这个trim参数写反了啊?
反正我没看懂.............
# Storing nodes
f = system.file("exampleData", "book.xml", package = "XML")titles = list()xmlTreeParse(f, handlers = list(title = function(x)titles[[length(titles) + 1]] <<- x))$title #此为输出function (x)titles[[length(titles) + 1]] <<- xsapply(titles, xmlValue)[1] "XML"[2] "The elements of an XML document"[3] "Parsing XML"[4] "DOM"[5] "SAX"[6] "XSL"[7] "templates"[8] "XPath expressions"[9] "named templates"rm(titles)
这个写法有点意思
titles[[length(titles) + 1]] <<- x))
附件列表
苍茫大海,旅鼠它来!

