
简介
本文主要介绍MapReduce V2的基本原理, 也是笔者在学习MR的学习笔记整理。
本文首先大概介绍下MRV2的客户端跟服务器交互的两个协议, 然后着重介绍MRV2的核心模块MRAppMaster(简称MRAM), 最后再介绍一些杂项知识点。
【广告】 如果你喜欢本博客,请点此查看本博客所有文章:http://www.cnblogs.com/xuanku/p/index.html
MR客户端
MR客户端通过两个协议来控制MR任务:
- ApplicationClientProtocol: 这是YARN提供的机制, 任何类型的Job提交/管理都需要通过该协议来提交, Client跟RM交互;
- MRClientProtocol: 这是AM启动之后, Client跟AM打交道的协议, 用来查询和控制MR任务的运行状态
ApplicationClientProtocol
service ApplicationClientProtocolService {
// 获取一个新的应用
rpc getNewApplication (GetNewApplicationRequestProto) returns (GetNewApplicationResponseProto);
// 获取Application的运行报告
rpc getApplicationReport (GetApplicationReportRequestProto) returns (GetApplicationReportResponseProto);
// 提交一个应用
rpc submitApplication (SubmitApplicationRequestProto) returns (SubmitApplicationResponseProto);
// 强制杀死一个应用
rpc forceKillApplication (KillApplicationRequestProto) returns (KillApplicationResponseProto);
// 获取集群所有metrics
rpc getClusterMetrics (GetClusterMetricsRequestProto) returns (GetClusterMetricsResponseProto);
// 列出集群所有Application
rpc getApplications (GetApplicationsRequestProto) returns (GetApplicationsResponseProto);
// 获取集群中所有节点
rpc getClusterNodes (GetClusterNodesRequestProto) returns (GetClusterNodesResponseProto);
rpc getQueueInfo (GetQueueInfoRequestProto) returns (GetQueueInfoResponseProto);
rpc getQueueUserAcls (GetQueueUserAclsInfoRequestProto) returns (GetQueueUserAclsInfoResponseProto);
rpc getDelegationToken(hadoop.common.GetDelegationTokenRequestProto) returns (hadoop.common.GetDelegationTokenResponseProto);
rpc renewDelegationToken(hadoop.common.RenewDelegationTokenRequestProto) returns (hadoop.common.RenewDelegationTokenResponseProto);
rpc cancelDelegationToken(hadoop.common.CancelDelegationTokenRequestProto) returns (hadoop.common.CancelDelegationTokenResponseProto);
rpc moveApplicationAcrossQueues(MoveApplicationAcrossQueuesRequestProto) returns (MoveApplicationAcrossQueuesResponseProto);
rpc getApplicationAttemptReport (GetApplicationAttemptReportRequestProto) returns (GetApplicationAttemptReportResponseProto);
rpc getApplicationAttempts (GetApplicationAttemptsRequestProto) returns (GetApplicationAttemptsResponseProto);
rpc getContainerReport (GetContainerReportRequestProto) returns (GetContainerReportResponseProto);
rpc getContainers (GetContainersRequestProto) returns (GetContainersResponseProto);
rpc submitReservation (ReservationSubmissionRequestProto) returns (ReservationSubmissionResponseProto);
rpc updateReservation (ReservationUpdateRequestProto) returns (ReservationUpdateResponseProto);
rpc deleteReservation (ReservationDeleteRequestProto) returns (ReservationDeleteResponseProto);
rpc getNodeToLabels (GetNodesToLabelsRequestProto) returns (GetNodesToLabelsResponseProto);
rpc getClusterNodeLabels (GetClusterNodeLabelsRequestProto) returns (GetClusterNodeLabelsResponseProto);
}
MRClientProtocol
service MRClientProtocolService {
// 获取作业运行报告
rpc getJobReport (GetJobReportRequestProto) returns (GetJobReportResponseProto);
// 获取任务运行报告
rpc getTaskReport (GetTaskReportRequestProto) returns (GetTaskReportResponseProto);
// 获取任务实例运行报告
rpc getTaskAttemptReport (GetTaskAttemptReportRequestProto) returns (GetTaskAttemptReportResponseProto);
// 获取Counter统计信息
rpc getCounters (GetCountersRequestProto) returns (GetCountersResponseProto);
// 获取所有已经完成的任务
rpc getTaskAttemptCompletionEvents (GetTaskAttemptCompletionEventsRequestProto) returns (GetTaskAttemptCompletionEventsResponseProto);
// 获取所有任务运行报告
rpc getTaskReports (GetTaskReportsRequestProto) returns (GetTaskReportsResponseProto);
// 获取作业诊断信息
rpc getDiagnostics (GetDiagnosticsRequestProto) returns (GetDiagnosticsResponseProto);
rpc getDelegationToken (hadoop.common.GetDelegationTokenRequestProto) returns (hadoop.common.GetDelegationTokenResponseProto);
// 杀死作业
rpc killJob (KillJobRequestProto) returns (KillJobResponseProto);
// 杀死任务
rpc killTask (KillTaskRequestProto) returns (KillTaskResponseProto);
// 杀死任务实例
rpc killTaskAttempt (KillTaskAttemptRequestProto) returns (KillTaskAttemptResponseProto);
// 让一个任务实例运行失败
rpc failTaskAttempt (FailTaskAttemptRequestProto) returns (FailTaskAttemptResponseProto);
rpc renewDelegationToken(hadoop.common.RenewDelegationTokenRequestProto) returns (hadoop.common.RenewDelegationTokenResponseProto);
rpc cancelDelegationToken(hadoop.common.CancelDelegationTokenRequestProto) returns (hadoop.common.CancelDelegationTokenResponseProto);
}
代码调用过程
- CLI.main -> CLI.run: 客户端入口, 从main函数开始看
- Job.submit: 提交任务, 异步提交任务
- JobSubmitter.submitJobInternal: 提交任务核心控制函数, 准备配置, 软件包, 校验权限等
- ClientProtocol.submitJob: 最终提交任务的实现交给了该接口, ClientProtocol是一个interface, 目前有两个实现: LocalJobRunner和YARNRunner, 我们主要关心你YARNRunner
- YARNRunner.submitJob: 没做啥事儿, 直接调用其成员resMgrDelegate.submitApplication函数
- ResourceMgrDelegate.submitApplication
- YarnClientImpl.submitApplication: 最终落到该类做的具体提交的工作
MRAppMaster
子模块概述
MRAppMaster是MR的核心模块, 其基础架构如下图:
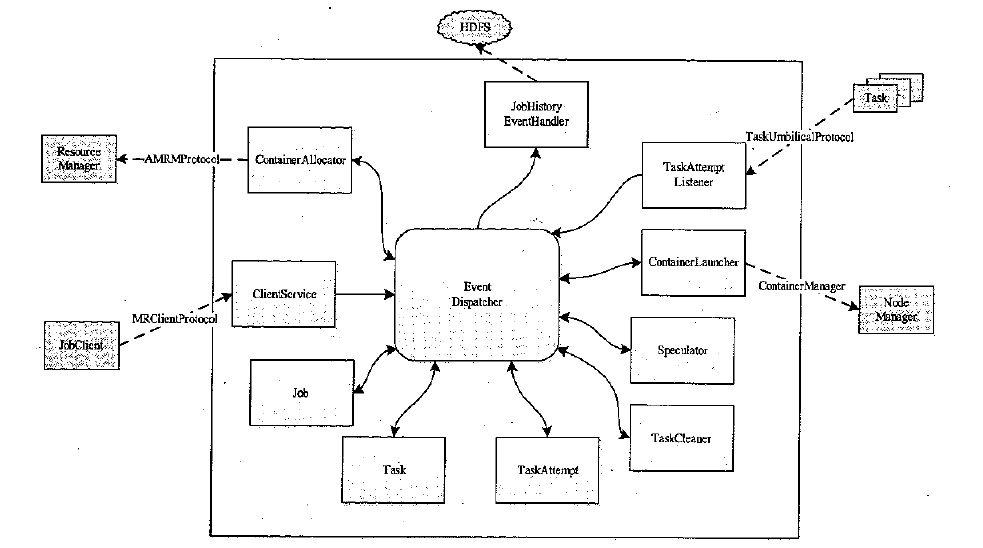
该图中各个子模块的解释如下:
-
ContainerAllocator:
该模块是用来跟RM打交道的模块, 用来给MR任务申请资源, RM通过心跳将已经分配好的Container返回给AM。请求资源包含:
- Priority. 作业优先级
- Host. 期望资源所在的Host
- capability. 资源大小
- containers. 资源数量
- relax_locality. 松弛本地性
-
ClientService
通过MRClientProtocol跟客户端打交道, 用来客户端查看作业运行状态, 控制作业运行过程(比如调整优先级, 杀死任务)等。
-
Job: 一个客户端的提交的作业。
-
Task: 一个Job会包含多个Task
-
TaskAttempt: 一个Task会包含多个TaskAttempt
-
TaskCleaner: 守护进程, 用来清理垃圾数据
-
Speculator: 完成推测执行, 找出拖后腿的Task并重新执行
-
ContainerLauncher: 跟NM打交道创建Container
-
TaskAttemptListener: 管理各个TaskAttempt, 定期收心跳, 如果超时, 就认为挂了
-
JobHistoryEventHandler: 记录任务执行日志(该日志也存在hdfs上), 当AM所在Container挂了之后, 会重新生成另外一个AM, 并从该日志中恢复运行状态避免计算浪费
作业基本概念执行图如下:
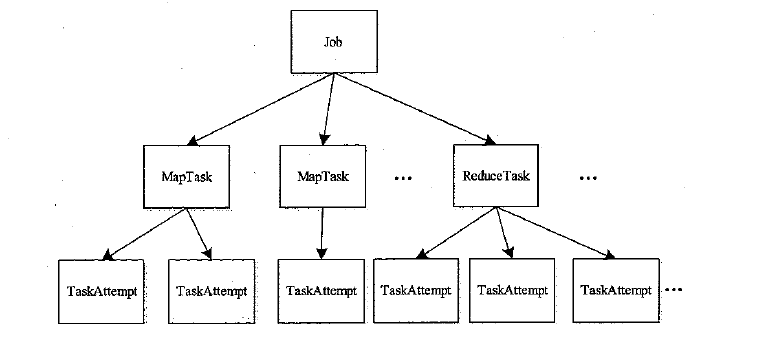
MRAM工作流程
MRAM提供了三种运行模式:
-
本地模式: 跟MRV1类似, 不再累述
-
Uber模式:
小任务适合的模式, 不再申请新的Container, 所有的Mapper和Reducer都在该Container中运行
判断一个任务是否按照Uber模式运行的条件如下:
- map数量小于mapreduce.job.ubertask.maxmaps 默认是9
- reduce数量小于mapreduce.job.ubertask.maxreduces 默认是1
- 输入文件小于mapreduce.job.ubertask.maxbytes 默认是一个block
- map+reduce所需要的资源量小于AM能申请资源的上限
-
Non-Uber模式: 即最常见的模式, 本文重点讲解Non-Uber模式, 下文默认也都是将Non-Uber模式的任务。
要了解一个系统, 一个快捷的方式就是了解该系统所处的各种状态以及转换条件。
下面我们来看看MRAM将一个Task分成的四个状态(在后面两节还会详解):
- pending: 刚启动但尚未跟RM发送资源需求
- sheduled: 已经向RM发送资源请求, 但是尚未分配到资源
- assigned: 已经分配到了资源, 并且正在运行
- completed: 任务运行完毕
可能有同学会觉得奇怪, 为什么要多一个pending状态, 让所有需求到RM中排队就好了嘛。其实这个状态主要是为Reduce任务执行的, 因为Reduce任务是否执行是需要看Map任务执行状态的, 所以一开始并不需要资源, MR会根据Map任务执行状态来判断Reduce任务的启动时间。
对于MapTask, 运行状态为: sheduled->assigned->completed; 对于Reducer, 运行状态为: pending->assigned->assigned->completed。
那么MRAM是怎么判断ReduceTask的启动时机的呢:
- mapreduce.job.reduce.slowstart.compeletedmaps: 当MapTask的完成比例达到该值之后才会为ReduceTask申请资源, 默认值为0.05
- yarn.app.mapreduce.am.job.reduce.rampup.limit: 在所有MapTask完成之前, 最多能启动的ReduceTask的比例, 默认是0.5
- yarn.app.mapreduce.am.job.reduce.preeption.limit: 在MapTask需要资源但是暂时获取不到, 能从已经开始运行的ReduceTask中抢到的Reduce Task的比例, 默认是0.5
可能又有同学要问, 为什么要提前启动Reduce任务呢, 等所有MapTask都完成之后再启动ReduceTask就好了嘛, 反正Reduce任务也需要等所有MapTask对应的数据都计算完毕, 确认ReduceTask的数据输入之后才敢开始计算。
要提前启动ReduceTask最主要的原因是在ReduceTask真正开始执行之前需要做两步提前的工作:
- 从MapTask的机器拖数据
- 在ReduceTask本地做shuffle排序
这两步操作都挺耗时的, 所以我们需要提前启动ReduceTask避免中间shuffle这段时间过长。
那么这里又有一个问题了, ReduceTask是如何问MapTask要数据的, 在MRV1中, 每台机器都有个Shuffle HTTP Server, 保证不管MapTask不管在哪台机器上都能获取到数据。
所以在NM上设计了一个插件机制, 可以提供一个接口将自己系统所需要的服务插件放到NM, NM启动的时候会帮忙启动任务, 这个Shuffle HTTP Server就是这样的一个插件, NM启动的时候会启动该服务。
那么又有一个问题了: 为什么不直接在MapTask的框架之上启动一个HTTP Server? 我猜可能有如下几个原因:
- 一台实体机上启动多个HTTP Server浪费资源, 还要做一些动态端口的事情, 又复杂了?
- 在MapTask机器上启动服务会浪费启动时间, 启动的HTTP Server浪费MapTask有限资源
Job介绍
下面我们来大概介绍一下Job的各个状态:
- NEW: 初始化的状态
- INITED: MapTask和ReduceTask已经被创建完毕, 只是还没运行
- SETUP: 作业的任务开始被调度
- RUNNING: 作业的部分任务已经得到资源, 开始被执行
- COMMITING: 作业运行之后的结果会先放到临时目录, 当所有任务都执行成功之后, 才会移到最终目录
- SUCCEEDED: 作业运行成功
这几个状态是正常情况下一个作业运行的状态过程, 下面来看看一些没有正常结束的作业的状态:
-
FAIL_WAIT & FAIL_ABORT & FAILED
当一个任务运行失败的时候, 会先进入FAIL_WAIT等待, 期望在这段时间之内杀死正在运行的任务; 然后会进入注销状态(FAIL_ABORT), 在注销完毕之后会进入FAILED状态
在SETUP阶段, 可能因为磁盘故障导致文件创建失败, 从而进入FAIL系列状态;
在RUNNING阶段, 可能因为失败的MapTask/ReduceTask比例超过配置(mapreduce.map/reduce.failures.maxpercent), 从而进入FAIL系列状态;
在COMMITING阶段, 可能因为作业结果提交失败而进入FAIL系列状态
-
KILL_WAIT & KILL_ABORT & KILLED
同上, 当收到用户的杀死任务控制命令之后, 依次会处于KILL_WAIT, KILL_ABORT, KILLED三个状态。
-
ERROR: 各种异常都有可能导致作业处于该状态, 需要人工处理
-
REBOOT: 当作业重新启动的时候处于的状态。
Task介绍
其包含的几个状态解释如下:
- NEW: 新创建的任务
- SCHEDULED: 开始申请资源, 但是尚未分配到资源
- RUNNING: 申请到资源并开始执行
- SUCCEEDED: 执行成功
同上, 异常情况下会有如下状态:
- KILL_WAIT & KILLED: 同Job的状态解释
- FAILED: 每个Task运行实例有一定的重试次数上限(mapreduce.map/reduce.maxattempts), 默认为4
TaskAttempt介绍
同上, 来看看TaskAttempt的状态:
- NEW: 新创建的任务
- UNASSIGNED: 等待资源
- ASSIGNED: 资源获取到, 还没开始执行
- RUNNING: 实例启动成功, 开始执行
- COMMIT_PENDING: 运行结束, 提交数据中。一旦某个任务数据提交成功, 其他同一个Task的TaskAttempt将会被杀死
- SUCCESS_CONTAINER_CLEARNUP: 运行结束, 等待清理空间
- SUCCEEDED: 成功清理空间, 到此为止, 实例运行成功
一个实例可能从RUNNING转换为COMMIT_PENDING, 也可能转换为SUCCESS_CONTAINER_CLEARNUP。主要原因是AM有两条路径知道Container运行结束:
- TaskAttempt与AM之间的通信: 会转换为COMMIT_PENDING
- RM跟AM之间的通信: 会转换为SUCCESS_CONTAINER_CLEARNUP
转换为什么状态, 就看先从谁那里收到信息了。为什么要这么设计? 感觉不太合理。
异常状态如下:
- FAIL_CONTAINER_CLEANUP: 清理失败TaskAttemp所占空间的状态
- FAIL_TASK_CLEANUP: 清理完成的状态
- FAILED: 确认失败之后的状态
- KILL_CONTAINER_CLEARNUP: KILL系列同FAIL系列
- KILL_TASK_CLEANUP
- KILLED
资源申请与再分配
资源申请
首先, 复习一下之前讲过的申请资源的接口, 是一个5元组信息:
- Priority. 作业优先级
- Host. 期望资源所在的Host
- capability. 资源大小
- containers. 资源数量
- relax_locality. 松弛本地性
举例:
// 优先级是整数, 数字越低, 优先级越高
<10, "node1", "memory:1G, cpu:1", 3, true>
<10, "node2", "memory:2G, cpu:1", 1, false>
<2, "*", "memory:1G,cpu:1", 20, false>
ContainerAllocator工作流程如下:
-
将MapTask的资源需求发送给RM
-
如果ReduceTask到达了调度条件, 则将ReduceTask的资源需求发送给RM
-
发送MapTask资源申请的时候, 一般一个MapTask会对应一个Block(也不绝对, 请参考[3]), 假设一个block有3个副本, 会同时发送如下7中资源申请需求:
<20, "node1", "memory:1G,cpu:1", 1, true> <20, "node2", "memory:1G,cpu:1", 1, true> <20, "node3", "memory:1G,cpu:1", 1, true> <20, "rack1", "memory:1G,cpu:1", 1, true> <20, "rack2", "memory:1G,cpu:1", 1, true> <20, "rack3", "memory:1G,cpu:1", 1, true> <20, "*", "memory:1G,cpu:1", 1, true>一旦如上任何一个资源申请通过之后, 会取消其他资源申请。
为什么要这么设计? 来回发送和取消不是设计得更复杂了么, 直接将自己的需求发送给RM, 让RM帮忙做选择, 然后返回不就好了?
这一点笔者也感到困惑。
资源再分配
当RM给AM返回一个Container的时候, Container会通过如下流程选择一个Task来使用该Container:
-
首先判断该Container是否满足要求, 如果不满足, 则下次心跳告诉RM, RM好回收该Container
-
然后判断该Container所在Node是否在黑名单上, 如果在, 同上, 下次心跳告诉RM, RM好回收该Container
黑名单是指当一个节点上运行的任务实例超过一定数目, 就进入黑名单。有两个配置跟黑名单相关:
- yarn.app.mapreduce.am.job.node-blacklisting.enable 是否打开黑名单开关, 默认为True
- yarn.app.maxtaskfailure.per.tracker: 失败几次就进入黑名单, 默认为3
- yarn.app.mapreduce.am.job.node-blacklisting.ignore-threhold-percent: 黑名单机器最多比例, 默认为33, 该配置是为了防止有大量机器被加入黑名单导致作业无法完成或者效率太低
-
Container可用了, 然后开始分配给各个Task, 一共有三类Task: Failed MapTask, ReduceTask, MapTask。各个Task都有一个队列, Task队列优先级: Failed MapTask>ReduceTask>MapTask。前两者队列内调度方案就是FIFO, 后者调度方案是根据node-local, rack-local, no-local优先级来判断。
推测执行
推测执行原理很简单, 就是讲拖后腿的任务重新运行一遍, 期望新任务比老任务早结束。该算法的核心在于怎么判断是否要启动一个备份任务, 如果备份任务启动太多, 会浪费资源, 如果启动太少, 会影响整体执行。
目前判断是否应该启动备份任务还是比较简单的, 就是看其跟其他已经完成了的任务的平均执行速度相比较, 如果重新启动一个任务会比该任务按照当期速度执行下去还要早执行完的话, 就启动备份任务, 但是为了避免有大量的备份任务, 又有如下限制:
-
每个任务最多只能有一个备份任务
-
已经完成的任务必须大于一个比例, MINIMUM_COMPLETE_PROPORTION_TO_SPECULATE, 默认是5%
-
一个作业所有备份任务相加必须少于一个上限值, 该值是如下几个值取max:
- 常数10
- 0.01*totalTaskNumber
- 0.1*runningTaskNumber
数据处理引擎
数据处理引擎跟MRv1流程几乎一样, 只是做了一些小的优化:
-
MapTask. 用Netty代替Jetty作为ReduceTask获取数据的Server;
-
ReduceTask. MRv1从MapTask拷贝数据的时候会针对每份数据建立一个连接, 即使数据来自同一台机器。MRv2中将来自同一台机器的数据做了合并;
-
Shuffle和排序插件化:
Shuffle插件由一个NM上运行的插件和Reduce上运行的插件共同构成:
-
org.nodemanager.containermanager.AuxServices.AuxiliaryService
默认实现为: org.apache.hadoopmapred.ShuffleHandler
-
org.apache.hadoop.mapred.ShuffleConsumerPlugin
默认实现为: org.apache.hadoop.mapreduce.task.reduce.Shuffle
-
-
排序插件
该插件由一个在MapTask中运行的插件和ReduceTask中运行的插件共同构成:
-
org.apache.hadoop.mapred.MapOutputCollector
默认实现为: org.apache.hadoop.mapred.MapTask$MapOutputBuffer
-
org.apache.hadoop.mapred.ShuffleConsumerPlugin
默认实现为: org.apache.hadoop.mapreduce.task.reduce.Shuffle
-
参考
- Hadoop技术内幕: 深入解析YARN架构设计与实现原理. http://book.douban.com/subject/25774649/
- mapreduce描述. http://www.cloudera.com/content/cloudera/en/documentation/HadoopTutorial/CDH4/Hadoop-Tutorial/ht_usage.html
- mapreduce跨行读取数据. http://my.oschina.net/xiangchen/blog/99653
- mapreduce控制mapper数量. http://blog.csdn.net/kirayuan/article/details/8651603

 浙公网安备 33010602011771号
浙公网安备 33010602011771号