

简介
该篇blog只是存储系列科普文章中的第三篇,所有文章请参考:
在工程架构领域里,存储是一个非常重要的方向,这个方向从底至上,我分成了如下几个层次来介绍:
- 硬件层:讲解磁盘,SSD,SAS, NAS, RAID等硬件层的基本原理,以及其为操作系统提供的存储界面;
- 操作系统层:即文件系统,操作系统如何将各个硬件管理并对上提供更高层次接口;
- 单机引擎层:常见存储系统对应单机引擎原理大概介绍,利用文件系统接口提供更高级别的存储系统接口;
- 分布式层:如何将多个单机引擎组合成一个分布式存储系统;
- 查询层:用户典型的查询语义表达以及解析;
本文主要介绍单机引擎层的一些知识。
单机存储引擎
单机存储引擎主要是指在单机内部提供一个存储介质的界面, 对于存储量不大的需求来说, 一般来说使用单机存储就够了, 顶多再多加一个副本作为备份存储, 类似Mysql的Master/Slave存储机制。
对于数据量比较大的系统而言, 就需要对数据做拆分并放不到不同的机器上, 单机存储引擎会是其基本组成组件。关于分布式存储如何组织我们会在下一篇文章中描述, 本文主要描述单机存储引擎相关技术。
基本技术点
对于单机存储引擎而言, 主要考虑点如下:
-
索引组织方式
索引组织方式比较简单, 主流就两种方式:
-
hash
-
要点:
hash本身就不用多做介绍了, hash对应的key就是存储主键, value是对应了该key对应数据的存储位置信息。不过hash算法本身也会有如下一些考虑, 回头笔者再另起文章介绍hash相关知识:
- hash函数选择
- hash冲突解决
- hash桶大小选择
-
好处:
- 随机查询效率很高
-
坏处:
- 存储总量受硬盘限制
- 无法顺序查找
-
-
B+树
-
要点:
B+树的组织和查找原理类似二分查找(类似的算法还有跳表), 将所有key按照顺序组织, 然后将其分成若干段, 每个段对应上一层节点, 余此类推直到根节点。其数据组织原理如下: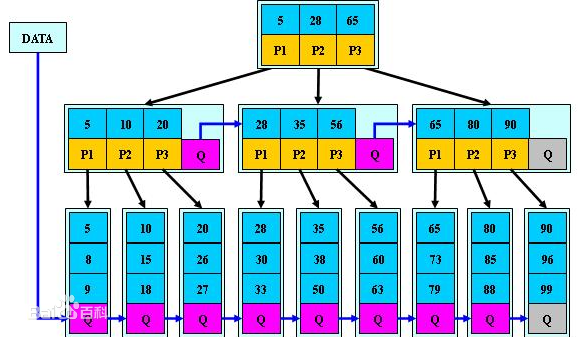
B+树算法本身主要考虑两个参数:
- 树的高度
- 子节点个数
-
好处
- 可以顺序查找
- 可以考虑有选择性的将部分数据存储在硬盘上, 从而增加单机存储总量
-
坏处
- 查询效率不如hash函数, 跟树的高度相关
- 随着数据更新, B+树有一定的维护成本
-
-
-
数据组织方式
数据组织方式又分成内存存储还是磁盘存储。
内存存储主要考虑内存管理和分配算法, 以及读写一致性对性能的影响, 这个会在讲实例引擎的时候详解。
磁盘存储首先考虑行存和列存, 主流存储引擎中两者都有, 下面对比一下两者的好处坏处。
-
行存:
- 要点:
将一行数据连续存储在磁盘上。典型代表是leveldb, Mysql的innodb。 - 好处
- 所有列数据组织在一起, 查找整行数据的时候会减少磁盘寻道次数
- 主键索引对应附加存储消耗会较少
- 坏处
- 难以增加, 删除, 修改列, 即修改schema代价很大
- 为主键以外的列建立索引代价较大
- 要点:
-
列存
- 要点
将同一列所有数据连续存储在磁盘上。典型代表是BigTable/HBase, Cassandra。 - 好处
- 有利于查询部分列, 尤其是单列查询, 减少IO消耗
- 有利于数据按列聚合函数计算, 如max, sum等操作
- 易于增加, 删除, 修改列
- 易于为单独列建立索引
- 一般来说, 有利于压缩算法
- 坏处
- 查询全行数据性能损耗较大
- 主索引所需要的附加存储消耗会变大
- 要点
其实像BigTable, HBase这样的存储引擎也并非存储的列存储引擎, 而是提供行列式存储界面, 然该用户自己组织哪些字段按行存, 哪些字段按列存。
上面大概介绍了一下单机存储引擎的数据组织, 在确定了基础数据组织方式之后, 单机存储引擎更重要的是在此之上考虑数据一致性, 读写性能, 容错容灾等事宜。
下面会以几个比较常见的例子来介绍这些点。
-
leveldb
LevelDB是一个Google提供的单机引擎库, 提供KV存储界面, 该库采用了LSM的存储机制, 适用于多写少读的使用场景。
下面我们描述一下LevelDB的原理, 因为其主要设计为写流量很大的场景, 所以我们来看其写入逻辑。
当需要写入一个<key,value>对的时候, 操作很简单, 只需要将key,value内容写入备份日志中, 先写日志是为了容灾, 然后就将key和value写入内存, 内存数据结构为skiplist(跳表, 跟B+树类似, 全局有序)。
但是这样肯定不够, 因为这样其实就变成一个内存存储引擎(比如Memcache)了, 而LevelDB是一个支持很大数据量的存储引擎, 大部分数据都存在硬盘上的。而如果数据一直存内存的话, 内存就无限制膨胀最终导致内存爆掉了。那么为了避免内存爆掉, LevelDB做的事情也很简单, 就是当内存涨到超过某个阈值之后, 就将其往硬盘上同步, 同步到磁盘的文件也是按key有序组织的, 后续这部分数据就在磁盘上的文件中查找。
同步到磁盘上是一个需要时间的过程, 那么这段时间如果在有写请求过来应该怎么处理呢, 也很简单, 新的写数据就写到一个新的内存块当中, 原来这块内存保证只读不写即可, 等数据完全同步到磁盘上之后, 这块内存其实就可以删掉了, 但是为了查询效率, 一般都是等到下次需要内存的时候才删掉这块内存。
那么又有问题了, 如果正在同步的这块内存块中的某个key又有一个新的写请求来更新这个key的内容或者删除, 那么内存中就有两份该key的值了,会不会造成读混乱呢? 不会,LevelDB实现也很简单, 就是保证读的时候的查询顺序即可, 先查询当前正在读写的内存块, 如果没有查询到结果才查询正在或者已经同步到磁盘上的这块内存块,因为正在读写的这块内存块中的值一定比只读不写的这块内存要新。但是这个对删除不work, 所以在LevelDB中删除并不是真正的删除, 只是相当于有一个特殊的值代表删除, 其落地也相当于是一个更新。
到目前为止, 内存块相关的逻辑就基本搞清楚了, 接下来细心的同学肯定会问了, 看起来每隔一段时间就会往硬盘上生成一个文件, 那么是不是每次查询很有可能都需要查询好多个文件, 如果是这样的话, 那么一方面是会有很多历史无效数据占据空间浪费空间, 另一方面更要命的是LevelDB的读取性能肯定非常低。所以LevelDB也采取了办法, 不是一直往磁盘上写文件就不管了, 而是定期将文件进行合并, 确保磁盘文件个数控制在一定范围之内。
那么合并是怎么个合并法呢, 在什么样的条件下合并, 谁跟谁合并呢? 首先来看看触发条件, 触发条件很简单, 就是文件个数超出某个阈值的时候就会触发合并; 谁跟谁合并呢, 首先在当前所有没合并的文件中挑一个出来做合并(挑选方式是round-robin), 然后跟之前所有已经之前合并过的文件进行再次合并, 已经合并过的文件再单独放一个目录, 每一个这样的目录就叫一层, 这也是LevelDB取名的由来。查询的时候先查询内存, 再查询第0层的所有文件(即没经过任何合并操作的文件), 如果没查到再查询合并过后的第1层的文件。如果第1层的文件经过多次合并过后太多了, 就会再建立第2层, 将第1层的文件跟第2层合并, 如此类推。
可以看到, 在查询第0层文件的时候, 可能同一个key会查询多个文件, 在查询后面层的时候, 每一层最多只需要查询一个文件即可。而LevelDB的查询性能并不算高效, 因为可能一次查询会涉及到多次文件的IO。而且本文还没有讲单个文件内部组织, 就确定某个key已经落到某个文件之后, 也都还需要多次IO才能将key的内容给读出来。
memcache
memcache内部就是一个hash<key, value>的结构, 首先会有一个hashmap来存储key以及value对应的指针。
而value对应的真正存储空间的管理, 最简单的方式就直接用内核提供的malloc和free函数来操作, 但是随着不同大小的空间块的增加和删除而导致不停增加内存碎片, 导致新空间可能无法申请, 且内存管理效率降低。
典型的内核用来降低内存碎片的算法就是伙伴算法, 这里我们不做详解, memcache并没有使用伙伴算法, 而是使用了一个类似伙伴算法但是更高效不过可能浪费空间更多的算法。
该算法原理如下, 首先确定一系列空间大小数字, 来代表基本申请和分配的单元格大小, 比如104字节, 136字节, 224字节...等。后续申请空间大小都按照这个size来分配, 避免内存碎片。
具体按照哪个size, 就看value值大小, 取大于value值的最小的那个值, 这样浪费的空间最少。
然后为了避免频繁从操作系统中申请空间, 每次都至少申请一个连续大小的空间(默认1M), 然后将其按照某个单元格大小切分, 下次如果再有相同大小单元格的需求, 先从已经分配的空间中看是否有剩余块, 如果有则直接用, 否则再重新申请一个1M的空间再分配。
根据这个算法引出如下几个概念:
- Page: 即刚才说的连续大小的空间(默认1M), 作为memcache问操作系统申请空间的基本单元;
- chunk: 即每个单元格
- slab: 即同样单元格大小的集合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号