
Python爬虫之urllib模块2
Python爬虫之urllib模块2
本文来自网友投稿
作者:PG-55,一个待毕业待就业的二流大学生。
看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于BeautifulSoup和lxml在后续的教程都会有。这里我记录的是我学习和思考的一个过程,我不是编程高手,非常感谢玄魂老师能给我这个机会,在公众号发布这种入门文章。
上一课我们成功的下载了页面的第一篇文章,这一课我们的目标是怎么把第一页的所有文章都下载下来。还是先继续我们上一节课的内容。我们这次爬取的网页还是http://tuilixue.com/zhentantuilizhishi/list_4_1.html
上一次课我们说了怎么去获取第一条的文章链接,现在我们再来爬取本页后面剩下的链接。我们先来看看上次我们爬取链接用的代码。

获取后面的链接我们能不能如法炮制呢,我们先来试试。我们把代码写成下面那样
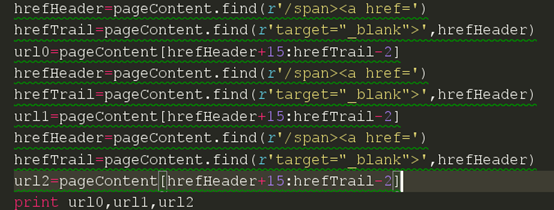
然后我们现在来试试
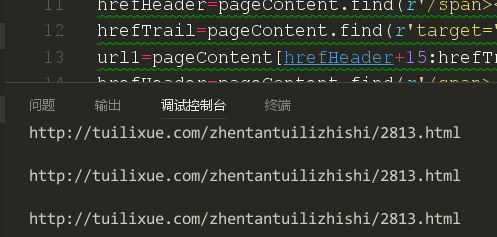
结果我们发现我们试图获取的三条链接都是一样的,可以看出,这还是本页的第一篇文章的链接。证明我们这种方法是不可行的。我们回想一下上一节课我们讲的定位链接使用函数

就是这个find函数,我们看看帮助,我们发现了我们可以自定义开始寻找的下标和寻找结束的下标。我们从html里面发现我们想要爬取的链接相隔都不是很远,都处在同一个div下面。于是我们来试试,从第一条链接后面开始寻找第二条链接。
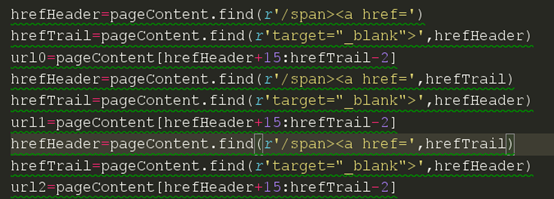
这里我们要注意后面两条代码,我们选择了开始的下标是从上一条链接的尾部开始的。现在我们来试试是否可以获取正确的链接。
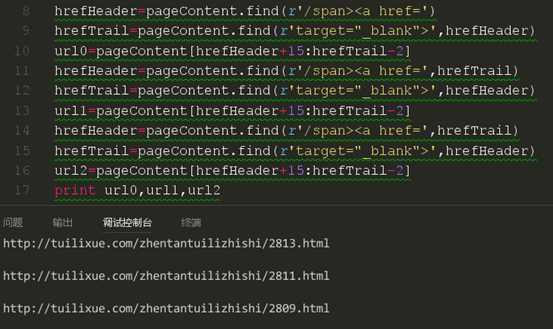
现在我们获取到了三条不同的链接,我们再通过对比html来看看我是否获取的是正确的链接。

从结果来看,我们的代码成功的获取了本页的前几篇文章的链接。关于怎么获取剩下的链接我们应该有头绪了。当然,这里一页只有10篇文章,也就是只有10个链接,我们可以把我们的获取链接的代码复制10次,可是如果一页有20篇,30篇,50甚至是100篇呢,难道我们也要将代码复制那么多的次数,肯定不能,也不科学。很多同学现在已经知道要用循环来做了,但是这个要怎么循环,从哪里循环呢?我们再来看看我们上面的代码,我们发现除了第一条链接获取的代码不一样,后面两条链接获取的代码都是一样的,这时我们就知道我们应该从第二条链接获取代码进行循环了。
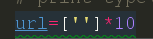
这里我们要先定义一个列表对获取的链接进行存储,因为是10篇文章,所以这里定义的就是一个10个元素的空的字符串列表。下面是我们循环的代码块。

这里结束一下我们为什么不是从0开始进行赋值,大家注意到没有,我们是从第二条文章链接看是循环的,那么第一条的文章链接在哪呢?当然是存储在了列表的第一个位置,也就是下标为0的那个位置了,关于range后面的范围,大家知道是包下不包上的就行了,就是说在range(x,y)的循环中,循环是从x开始,到y-1结束的,不包括y本身。我们现在来运行一下我们的代码看看是否获取的是正确的链接。
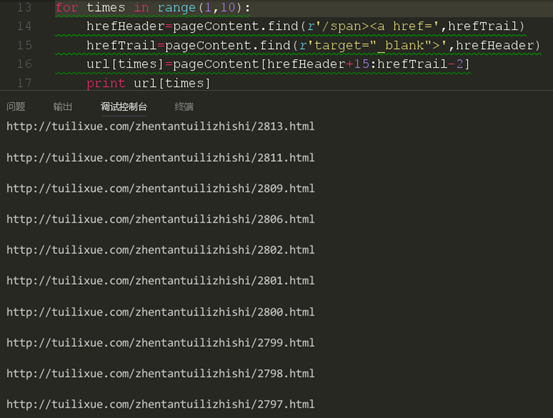
然后再次对比html

这时我们发现我们获取了链接是正确的,那么我们就要开始进行下载了。还是上一节课的代码,不过我们进行修改一些地方。因为上次只是单个链接,这次我们有一个链接列表,所以我们应该采取循环进行下载。我们要对下载重新写一个循环了。

我们现在来试试,这是上一节课我们成功下载的第一篇文章

我们现在删掉他。

现在我们看到文件夹里面是什么都没有的,我们现在开始下载。
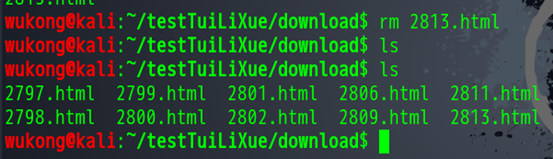
我们这就下载完了,我打开其中一个看看。还是注意地址栏上面的链接。
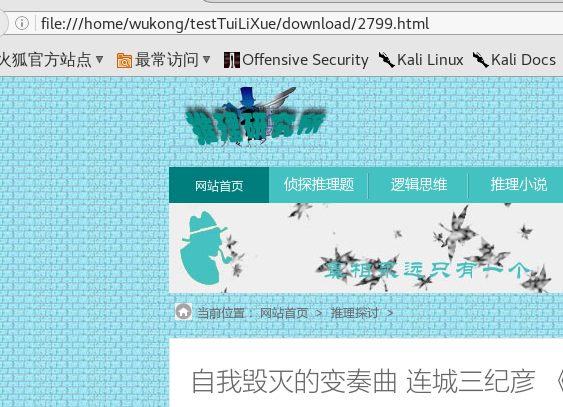

可以看出我们获取的文章是正确的。因为篇幅有限,我就不一个一个去打开截图了,大家自己可以根据自己实际环境敲一下代码。
类似的功能有很多值得改进的点,大家可以发表自己的观点,进行讨论。
作者:玄魂
出处:http://www.cnblogs.com/xuanhun/
原文链接:http://www.cnblogs.com/xuanhun/
更多内容,请访问我的个人站点 对编程,安全感兴趣的,加qq群:hacking-1群:303242737,hacking-2群:147098303,nw.js,electron交流群 313717550。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
关注我:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2014-04-16 NODE-WEBKIT教程(6)NATIVE UI API 之MENU(菜单)