Swin Transformer
ViT将Transformer从NLP迁移到CV但是只做了基础的检测任务,在论文中提出对其他视觉任务的展望,Swin Transformer来告诉你在基础的视觉任务上只需要用Transformer就行了。这也让Swin Transformer成为了做这些CV基础任务的绕不开的baseline。
不过好狠,直接把所有任务做完了……一点余地都不留啊。
本文为李沐老师的Paper精读系列的Swin Transformer的笔记,建议直接看视频,更加详细。
Abstract
Transformer从NLP迁移到CV主要存在两个挑战:
- 尺度(scale):视觉目标的尺度不一,比如街景图片中行人和车的,在NLP中token相同,但在视觉token中相差很大。
- 数量规模:NLP中token为文章(text)中的单词,CV中若以基本的像素(pixel)为token规模太大(100 x 100 像素图片不考虑channel下就有1e4个token,更别说1080,2K这些了)。为了使用Transformer一般是使用
特征图,或图像分割成的patch(ViT)作为输入。
本文作者针对以上问题提出使用层级式(hierarchical)的移动窗口(shifted window)来学特征,好处是:
- Shifted window和ViT一样让图像序列大大减小。
- Shifted让相邻的窗口有了交互,从而让上下层之间有了
cross-window connection达到全局建模的能力。 - 多尺度(various scales),可以提供各个尺度的特征信息
- 自注意力在小窗口之内进行计算,复杂度随图像大小线性(Linear)增长而不是平方(quadratic)
- 多尺度特征的结构比较相似于CNN的卷积可以迁移到下游任务中,在分类,检测,分割等都已经到了SOTA(state-of-the-art)
- 在MLP结构的TransfoemerMLP-Mixer也有较好的结果
Introduction
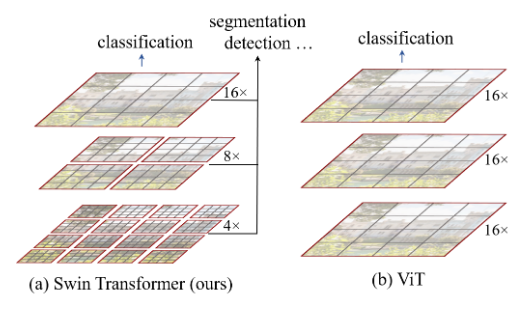
ViT在分割是采用了固定下采样patch(16x),而Swin Transformer则采用了多尺度的方法。ViT的token自始至终不变,处理low resolution。
在视觉任务中尤其是下层任务,多尺度至关重要:
- 目标检测: FPN(Feature Pyramid Network)
- 物体分割: U-Net
计算复杂度方面,ViT采用的是固定倍率下采样,为平方复杂度(原来分块\(\frac{HW}{P^2}\),当H,W均扩大到N倍,则分的块数量变为\(N^2\frac{HW}{P^2}\))
Swin Transformer则在每个红色窗口内算自注意,只要窗口大小固定那么计算复杂度就固定。复杂度详细推导详见Swin Transformer 时间复杂度的分析
Shifted Window
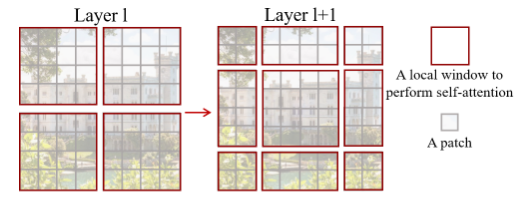
在Swin Transformer中灰色的patch是基本的计算单元(token)自注意力在这里面计算,红色方格中的patch可以互相交互。但这样不同的token只能在红色方格中互动,无法提取全局信息。
此时将红色方格shift一下,使同一patch可以和原来不同红色方格的patch互动,从而实现了cross-window connection
Conclusion
最有意义的是:Swin Transformer最大的贡献是shifted window操作,极大的节省了显存空间。
但ViT没有改Transformer的Encoder,可以直接将文本和图片的toke一起扔给Transformer,这样也能工作。
Swin Transformer如果可以将shifted window应用到NLP上则模型大一统的工作就比较圆满了。
Method
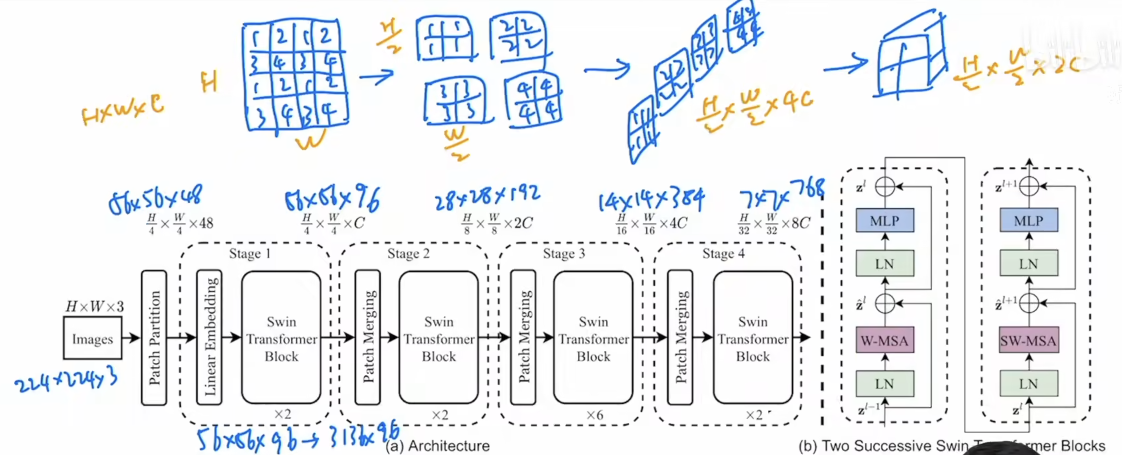
前向传播过程
从一张224 x 224 x 3的图片输入来说明前向传播过程
Patch Partition
Swin Transformer使用patch为4x4大小,每个patch特征维度为48维
输入224 x 224 x3
输出56 x 56 x 48
Linear Embedding
对原始值的特征应用线性层,将图像特征映射为特定值(超参数)C,Swin-T模型设置为96
输入56 x 56 x 48
输出56 x 56 x 96
Swin Transformer Block
Swin Transformer层输入时需要将张量拉直,从56 x 56 x 96拉为3136 x 96但并不影响输入输出维度
输入56 x 56 x 96
输出56 x 56 x 96
Patch Merging
为了提取多尺度特征,类似于CNN中卷积池化的操作,需要合并patch。合并的方法如上图所示:
很像CNN中的PixelShuffle的反操作。我们期望下采样为原图像的2倍。
具体方法是将原图像隔点采样到同一个patch,得到四个张量,张量大小H/2, W/2, C
再沿C的维度拼接,张量大小H/2, W/2, 4C
再使用1x1卷积,模仿CNN使通道数只改变为原来的2倍
输入56 x 56 x 96
输出28 x 28 x 192
之后的操作与Stage 2一致。
Shifted Window based Self-Attention
Self-attention in non-overlapped windows
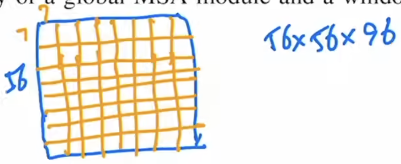
以Stage1的Swin Transformer Block的输入为例,大小56 x 56 x 96
把它切成一些不重叠的方格,每个方格就是所说的窗口(window),但窗口并不是最小计算单元token,每个window包含M x M个patch,设置M=7。即每个window有49个patch
而一个56 x 56的张量可以被分为64个window,我们会在这64个window中分别计算每个window的自注意力
这样也是的模型复杂度由平方复杂度变为线性,详见Swin Transformer 时间复杂度的分析
Shifted window partitioning in successive blocks
self-attention in non-overlapped window解决了模型可以训练的问题,但分开的windows无法进行通讯,此时将图片整体向右下角移动半个窗口:由Layer l转为Layer l+1。
若计算是层级式的即Layer l进行W-MSA,之后Layer l+1进行SW-MSA就起到了窗口间互相通信
Efficient batch compution for shifted configuration
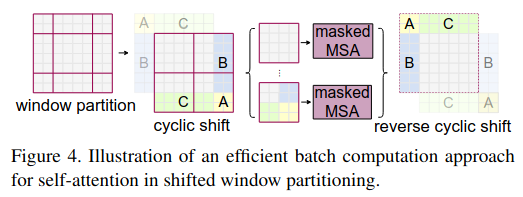
Shifted window的一个问题是从layer l到layer l+1的过程中window数量由\(\ulcorner\frac{h}{M}\urcorner\times \ulcorner\frac{w}{M}\urcorner\) 变为\(\ulcorner\frac{h}{M} + 1\urcorner\times \ulcorner\frac{w}{M} + 1\urcorner\)且大小不一。此时还要继续算window中的自注意力,为了解决大小不一的问题,一个简单的方法是直接0填充小的window至最大的window。不过这样的话计算量会是原来的2倍以上(因为0填充也需要运算)。
Swin Transformer的方法是循环移位,将窗口移到cyclic shift所示位置,这样就可以使运算量不变。但以cyclic shift左下角的window为例,C部分原来不应该与window其余部分运算的。例如:C部分原来是天空,此时循环移位后会与地面相连,按理来说是不应该与window中非C部分的patch一起计算。
但是按照cyclic shift的做法,会产生所说的不应该计算的情况。Swin Transformer的做法非常工程化,直接使用Masked操作将不应该计算的情况加一个很大的负数(和Transformer中的掩码操作差不多都是加了一个很大的负数),这样在之后的softmax中会设值为0。
举例来说
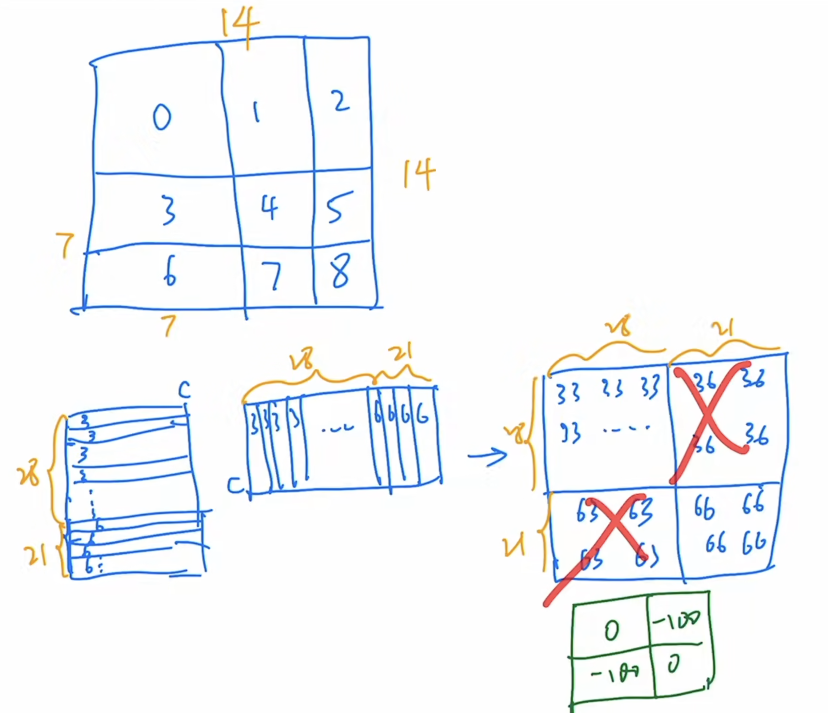
图片标号是原来window partition从左到右,从上到下顺序标号。对左下角的window进行自注意力后需要的情况是只含标号为3或6的块,而不是混合的块。
Swin Transformer的操作就是依据这种模式设计masked块。加到原矩阵上进行softmax操作。
这一段还是建议看视频的,毕竟有些繁琐。贴张作者在issue中可视化的mask来帮助看视频时理解吧。
from https://github.com/microsoft/Swin-Transformer/issues/52#issuecomment-1063551752

Relative position bias
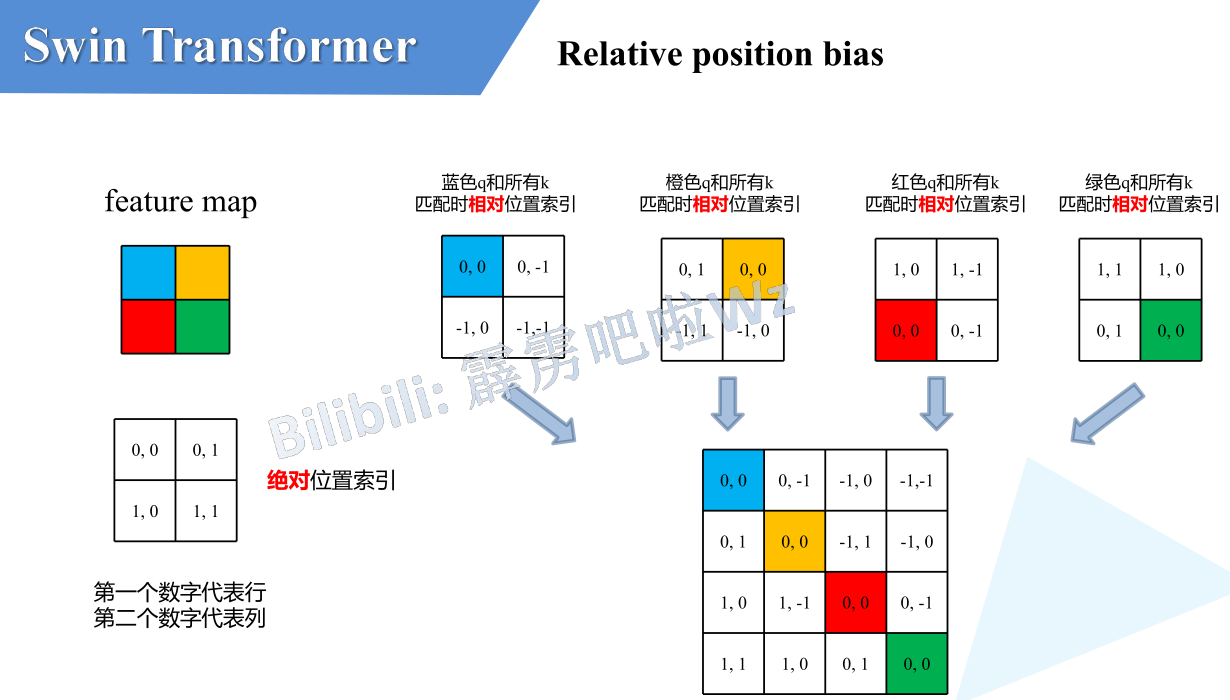
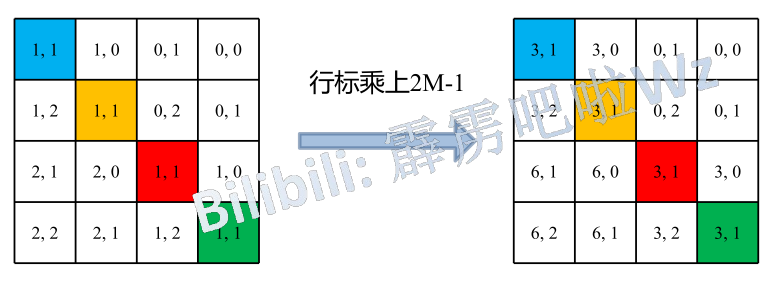
假设feature map的大小M=2,绝对位置索引如上所示。
对每一个染色的块(参考点),其他块均有一个相对该染色块(参考点)的二维距离。
将每个相对位置索引块展平合并成一个方阵(有可能是为了适应Transformer的\(QK^T\)运算形成的方阵)
此时的问题变为:怎么用不重复的值表示每一行中的数?(因为每一行的每个点相对于参考点都是独一无二的,且每个位置相对于参考点的二维距离均落在[-M+1, M-1]内)
一个直觉的办法是直接将二维坐标x, y相加,但是以[0,0]为参考点,[0, -1],[-1, 0]两个点的表示一样了,所以不可行。
作者的方法是:
行,列标均加上M-1
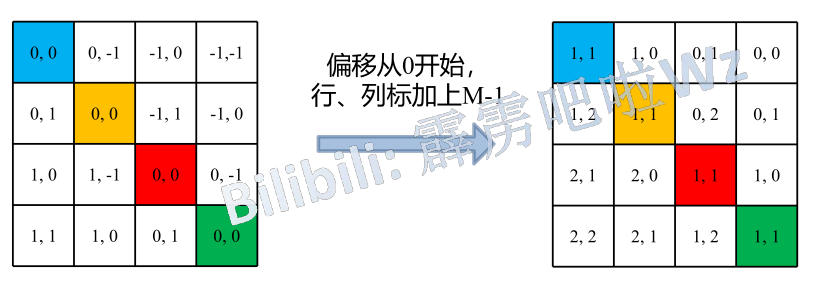
行标乘以2M-1
行,列标相加
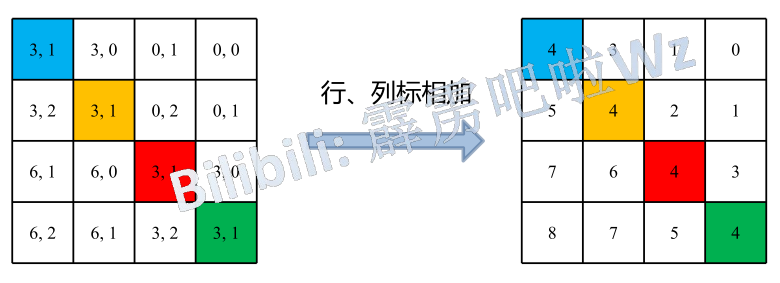
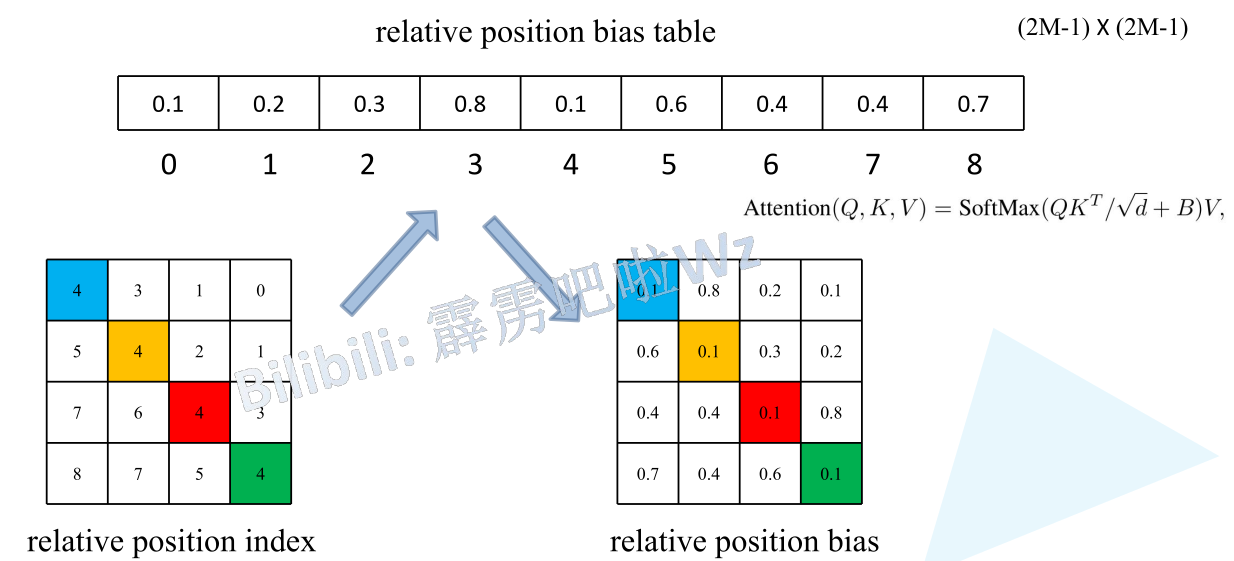
此时每一行中每一个数字都有了唯一的表示,且像论文中说的相对位置偏移\(\hat{B}\in\mathbb{R}^{(2M-1)\times(2M-1)}\)
可以用一个一维的数组表示相对位置偏移了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号