Normalization
Why Normalization
当error surface比较崎岖时,模型比较难以训练。比如: 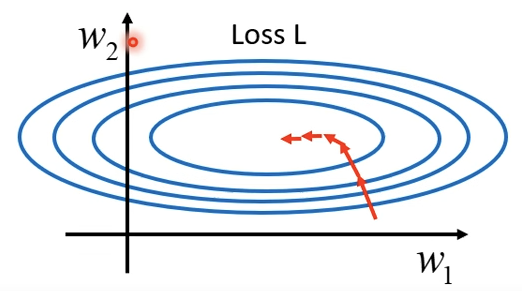
error surface是一个碗状的,两个参数\(w_1,w_2\)的斜率变化差别很大,\(w_1\)斜率比较小,\(w_2\)比较大。
此时使用固定的learning rate并不合适。需要使用诸多技巧,比如Adaptive Learning Rate
为什么两个参数的斜率会差很多呢?
我们的训练过程是由特征(features)结合不同的权重\(w_1,w_2\)后加上常数项得到预测值,然后将预测值与实际标签做比较得到Loss。最优结果就是Loss值最小。
此时对参数值做出改变,假设\(w_2+\Delta w_2\),那么会放大所对应特征\(x_2\)的影响。对参数\(w_1\)改变,则会放大特征\(x_1\)的影响。此时\(x_2\)的值较大,那么参数改变相同的值对Loss的影响更大,也就使得\(w_2\)的梯度更为陡峭。
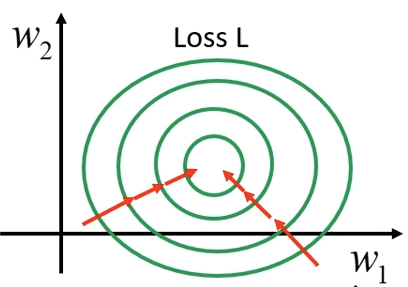
那么如果不同的feature有接近的范围,error surface会更加平坦,相应的结果应该也应该会更好。
Feature Normalization
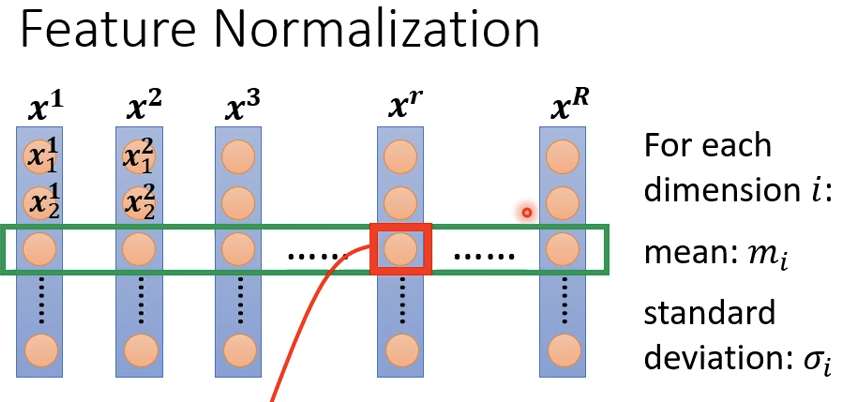
\(x^1\dots x^R\)是所有训练样本的特征向量,此时将不同\(x\)的同一维度取出(代表着不同样本中的相同特征),将其归一化。
对所有特征维度进行同样的归一化操作,就会将feature分布限制到均值为0,方差为1的分布。
Batch Normalization
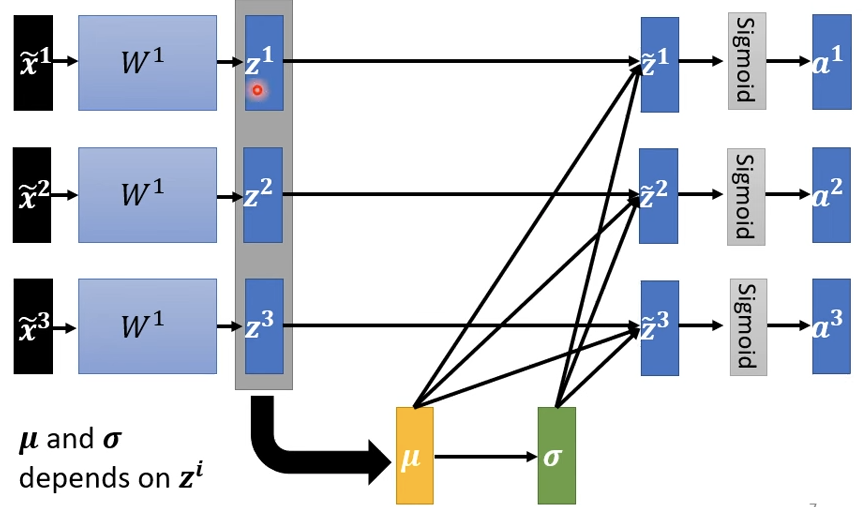
DL的大多数操作都是矩阵运算,但矩阵运算后得到的\(z^1,z^2,z^3\)并没有Normalization,可以将同样的操作用在矩阵输出上。
此时DL训练的是一个batch,那么上述操作就被成为Batch Normalization
Layer Normalization
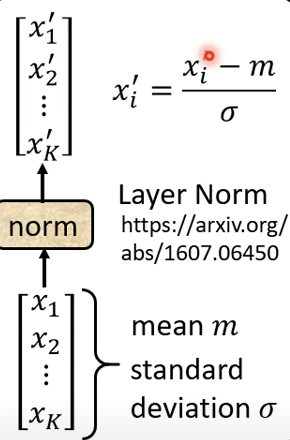
在Transformer中使用的是Layer Normalization,将样本特征向量视为整体,求相应的均值均值和方差,进行Normalization操作。
Why Layer Normalization
上面提到的Feature Normalization和Batch Normalization还是便于理解的,其目的是将不同的特征维度映射到相同分布范围上,从而使各个error surface不至于过于崎岖。
Layer Normalization的应用对象则主要是seq2seq的模型,因为我们不能保证输入的每个序列长度一致。
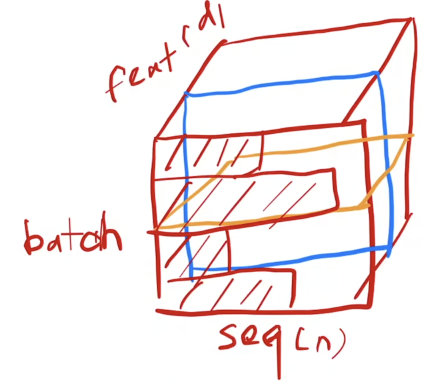
如果对seq2seq使用Batch Normalization(BN)
由于长度不一,为了计算均值方差一般会进行补0操作,此时由于长度问题,数据的抖动比较大。
在使用BN层的时候pytorch这类的工具会根据每个batch计算一个全局的均值方差,然后应用到测试中去。
此时假如进入一个超长的序列,对没有出现过的特征进行BN并没有什么意义。
使用Layer Norm则不会有这些问题,因为它的Normalization操作是针对样本自己来进行的。
当然Layer Norm还有其他解释,可以查阅相关资料发现从梯度等角度的解释。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号