Why Deep
Why hidden Layer?
神经网络所需要的工作笼统的说就是拟合一条曲线,简单的情况如下。
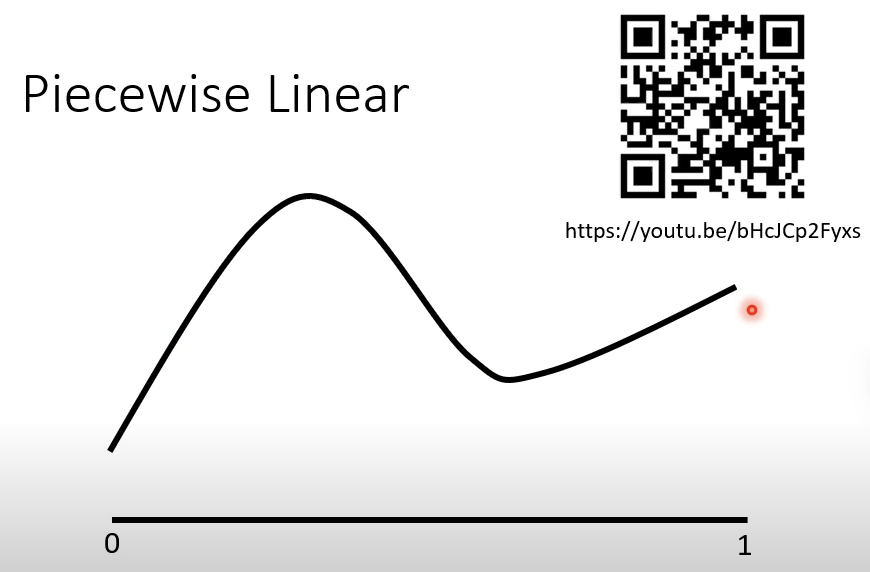
通过采样几个点然后连起来可以得到一个初步拟合的结果,当采样的点足够多,所连的点足够细,那么拟合相像的程度就越高。
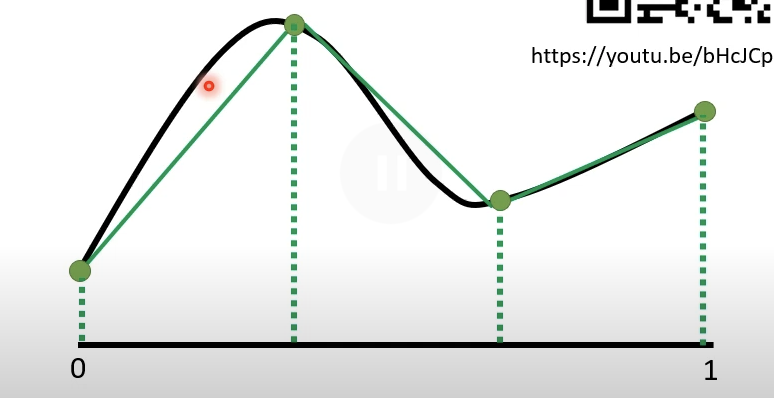
上图可以通过一系列的初步的阶梯函数和常数项的组合来合成:
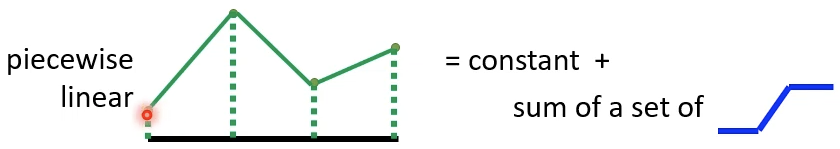
常数项将所有函数向上偏移到需要拟合的函数的最低点

加上第1个阶梯函数得到左边的绿色线段

接着加上第2,3……个函数得到中间,右边的绿色线段。
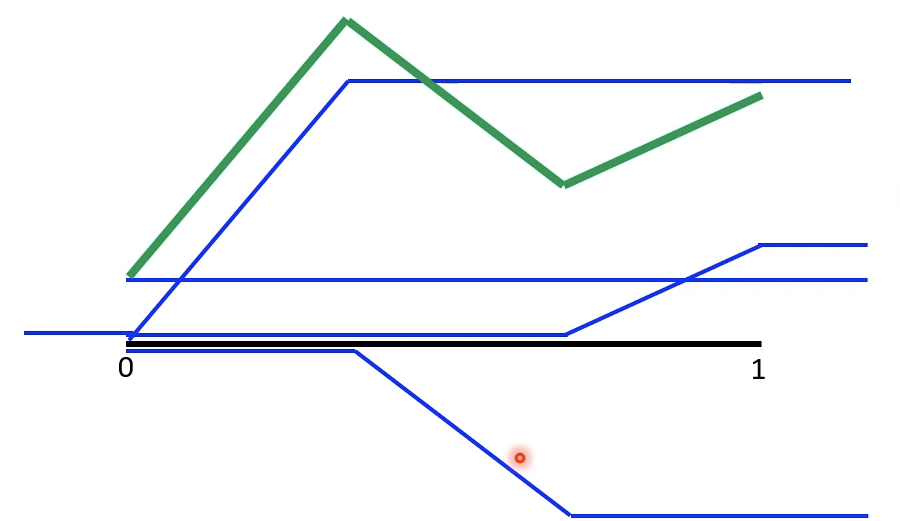
以上例子说明任何piecewise linear函数可以通过常数项加上一系列阶梯函数(neuron)组成,而piecewise linear函数可以逼近任何函数。
那怎么来表示这些阶梯函数呢?可以使用Sigmoid Function来近似取代。
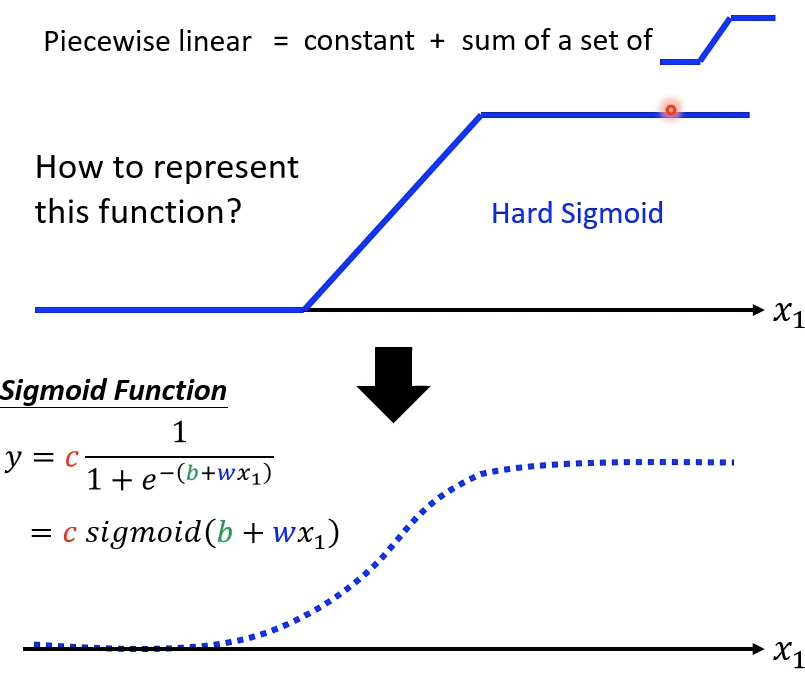
选取的Sigmoid Function通过设置不同的权重可以近似取代任何阶梯函数,最后加上常数项,就可以完成拟合的任务。
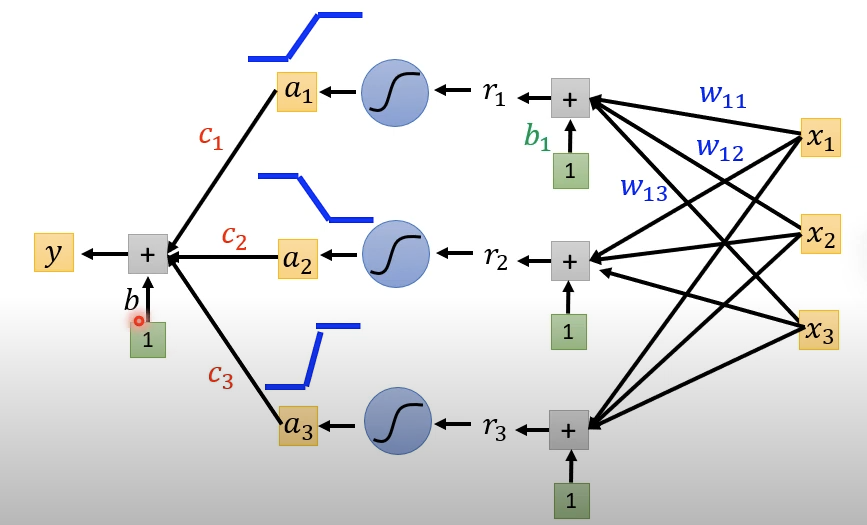
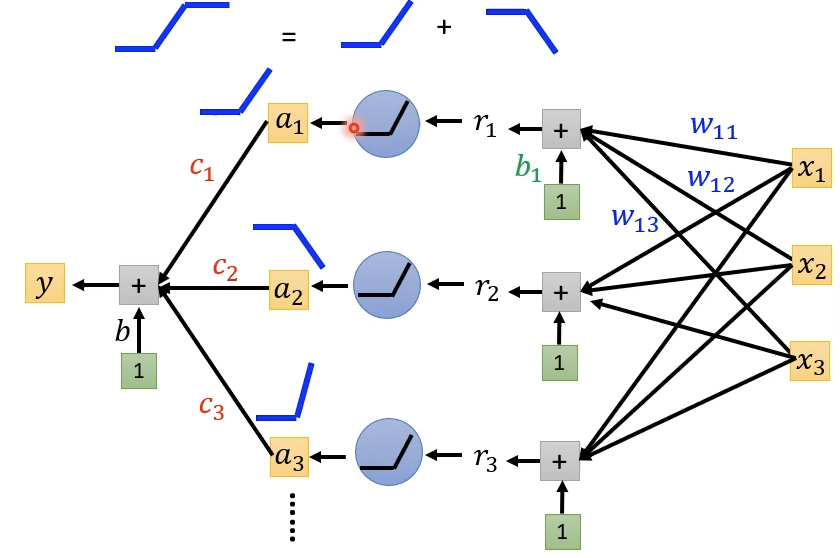
另一个可以平替Sigmoid Function的函数是ReLu
Why Deep?
LHY老师在之前的课程中提到过,可以使用一个Hidden Layer层来拟合任何函数。那么一个Fat Network就足够为什么还要Deep Network?
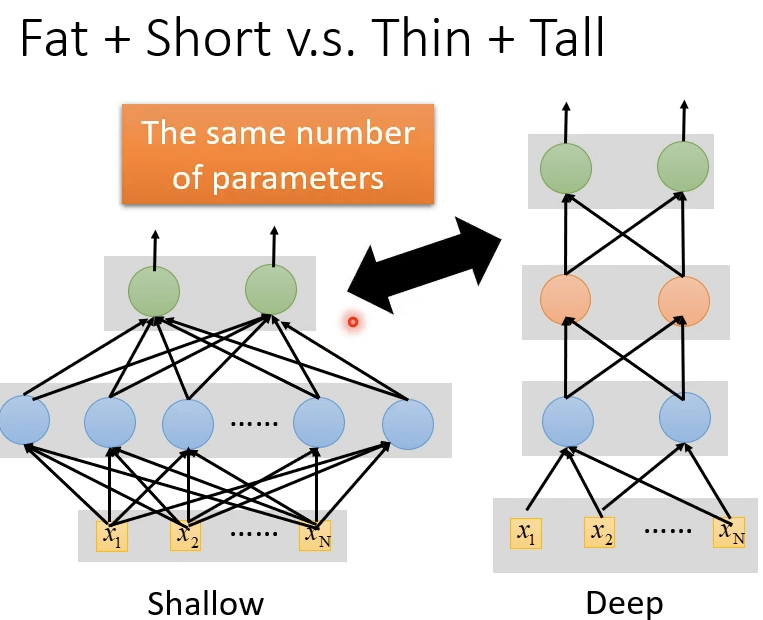
这时需要进行对比Fat和Deep的表现,一个直观的对比是参数量(parameter)对比,因为参数量对应于使用的neuron的多少。不同模式下使用相同数量的neuron,效果更好的说明有更大的优势。
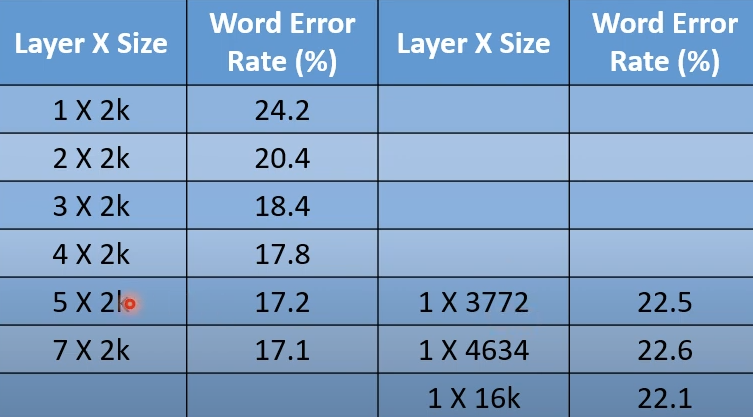
以上图(某篇论文的结果)为例,使用1层3772个neuron和5层每层2k个的参数量一致。但效果并不如Deep的结果。
最后得出结论结论,只使用一层hidden layer可以表示任何函数,但是使用deep的结构效果会更好。
Why Deep Better?
Deep advantages
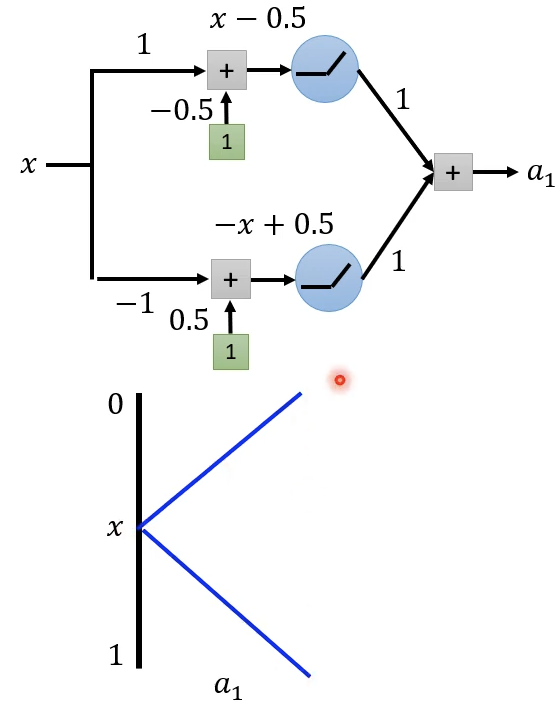
考虑上图,一个输入x经过两个neuron权重表达分别是x-0.5和-x+0.5,然后经过ReLu(x)=max(0, x),每个neuron贡献为1,得到输出\(a_1\)。画出\(x\),\(a_1\)的函数图像即为上图。此时是一个neuron的情况。
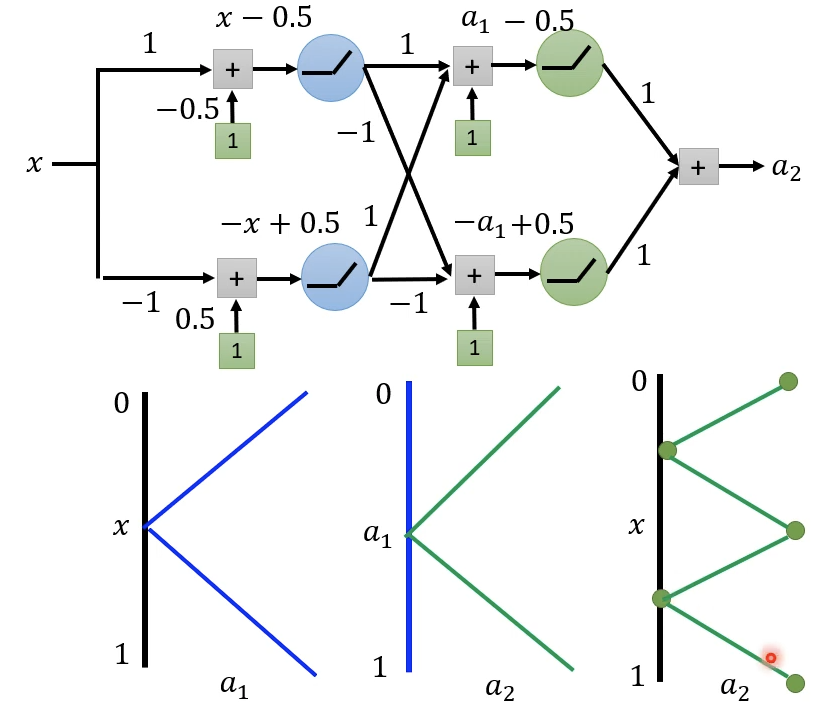
当使用Deep的结构,是将多个单层结构叠在一起。此时考虑多个的情况,对一层neuron的情况迁移到第二层,即对第一层输出\(a_1\)做和第一层输入\(x\)的运算。第二层输入\(a_1\)和输出\(a_2\)的函数关系和第一层一致。
但我们关心的不是单层neuron的输入输出情况,而是多层。此时\(x\)从0到0.5,就已经走了\(a_1\)从0到1的过程。\(x\)从0到1,\(a_1\)已经经过两个周期。
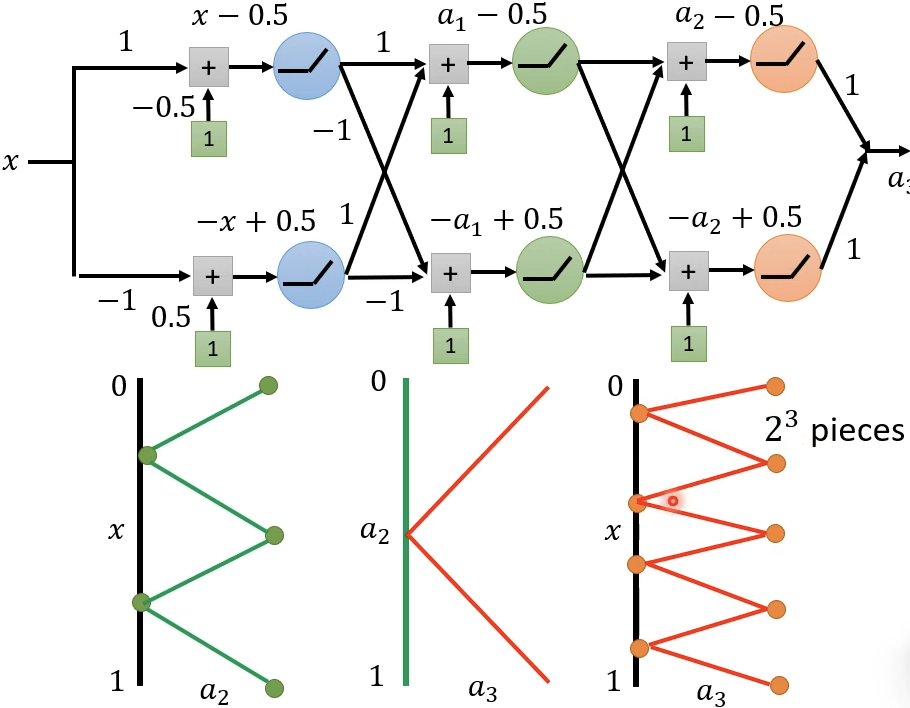
继续叠加层数,叠到K层可以得到\(2^K\)个pieces。
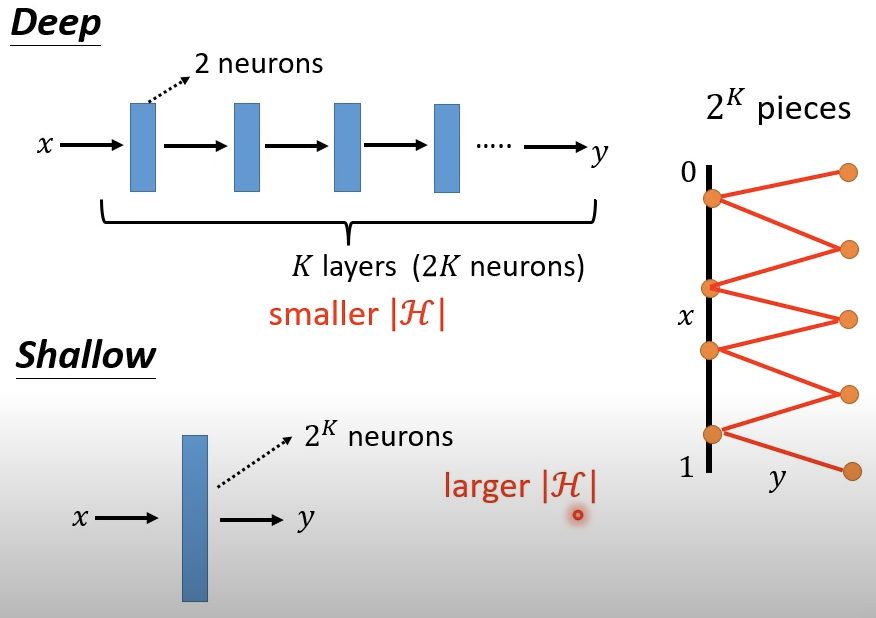
但使用Fat-Shallow结构获得同样的pieces,需要\(2^K\)个neuron。
Conclusion
Deepnetworks 在复杂切有规律的任务(Image, Speech, etc.)会优于Shallownetworks。Deep相较于Shallow是指数级的优化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号