

阿里音乐流行趋势预测大赛,赛后总结
一、赛题介绍
1、赛题数据:
已知x个歌曲艺人在阿里音乐上的用户记录数据(2015年03月01日-2015年08月30日)
- 用户行为表:一行记录某个用户某日对某首歌曲的操作,包括:播放,下载,收藏

- 歌曲艺人表:一行记录某个艺人在某日发行某首歌曲的基本信息,其中包括该收歌曲的专辑收录时间,初始播放量,歌唱语言以及歌唱者的性别组成

预测这x个艺人在之后的2个月(2015年09月01日-2015年10月30日),共60天内每日的播放量。
选手提交表:一行记录某个艺人某日的播放量

2、赛制介绍
比赛共分为初赛,复赛2个环节,各给1个月时间,每日定点提交一次结果,线上评分。
每个环节的最后7天时间会切换数据,重新评分排名,以此分数作为该环节的最后得分。
- 初赛离线下载建模:50个艺人和565,2231条用户记录,切换数据后为100个艺人和1588,4087条用户记录。
- 复赛在线上数据平台上建模:100个艺人,切换数据后为1000个艺人和18,3981,9438条用户记录。
二、分析思路
1、分析评分指标
提交结果的最终评分是按照F值计算的,从计算公式来看F是由每个艺人的评分相加得到的,每个艺人的得分是由归一化方差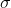 (sigma)和
(sigma)和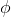 (phi)相乘得到的。
(phi)相乘得到的。
(sigma)和(phi)相乘得到的。其中是当前艺人的每日实际播放量相加开根号得到的,每个艺人的参数有且只有一个固定值,它的大小取决于每个艺人的60天播放量总和值,当某个艺人的总播放量较大时,就大,F也就变大了,由此可知:60天总播放量越大的艺人,预测越准,评分会越高,这是个快速提分的方法。
是当前艺人的每日实际播放量相加开根号得到的,每个艺人的参数有且只有一个固定值,它的大小取决于每个艺人的60天播放量总和值,当某个艺人的总播放量较大时,就大,F也就变大了,由此可知:60天总播放量越大的艺人,预测越准,评分会越高,这是个快速提分的方法。从公式来看参数是由某艺人提交的每日播放量与实际播放量的差值除以实际播放量,对该值平方后取60天的平均值,开根号得到的。这个参数反应了提交结果S与实际播放量T之间的差距。差越小,预测越精准,(1-)越大,F就大。而当差过大超过了实际播放量T,此时>1,(1-)为负数,此时对该艺人评分为负,综合累加的F值会更小。由此可知,若预测中存在某个艺人结果极端不准的情况,会使评分F下降得更多,因此也要保证所有艺人的平均预测准确性。即尽量保持平稳的值,突发值很容易使结果变差。
是由某艺人提交的每日播放量与实际播放量的差值除以实际播放量,对该值平方后取60天的平均值,开根号得到的。这个参数反应了提交结果S与实际播放量T之间的差距。差越小,预测越精准,(1-)越大,F就大。而当差过大超过了实际播放量T,此时>1,(1-)为负数,此时对该艺人评分为负,综合累加的F值会更小。由此可知,若预测中存在某个艺人结果极端不准的情况,会使评分F下降得更多,因此也要保证所有艺人的平均预测准确性。即尽量保持平稳的值,突发值很容易使结果变差。
2、初探规律
根据题目要求,可以确定这是一个回归预测类题目,已知前6个月歌曲艺人及其用户记录,预测后两个月每日的艺人播放量值。
建模的流程是:
预处理-->提取特征并筛选-->模型(多个自变量预测一个连续因变量值)-->预测-->评估
初探数据规律,是为了提取重要特征作为后续建模的备选样本变量。
开脑洞,研究数据:
- 首先可以看出用户记录表中的用户每日播放,下载和收藏歌曲量是预测未来60天每个艺人播放量的重要依据,可以将其作为重要特征。
- 其次,在不考虑突变和周期规律的情况下,该时间序列是具有短期自相关性的,即相邻的时间序列值具有连续性。很显然要预测9、10月的每日播放量,从已知的8月30日开始倒推,离待预测时间越近的几个月的信息与待预测值相关性较大,可以作为主要预测依据。
- 用户记录表中每条记录gmt_create记录是可以将每日用户的播放行为精确到每小时,将用户行为按小时划分也许会获得在时间上的高分低谷特征规律以辅助预测未来60天的播放量的周期规律
- 在歌曲艺人表中,查看数据会发现有部分歌曲的发行时间记录publish_time是在2015年3月以后到2016年的,而截止2015年3月1日前的初始播放量数据song_init_plays确为较大的值,官方解释说是艺人有些歌曲是在之后发行专辑的,因此发行记录比较晚,而歌曲已经有初始播放量了。专辑发行的炒作,很大可能会导致在publish_time出现播放量小范围的突增现象,有助于推测未来数据的突增日期及其播放量。
- 整理数据会发现,在用户前记录表(6个月)中的歌曲总数小于在歌曲艺人表中的歌曲个数,如初赛未换数据前用户记录表有1,0278首歌曲,而歌曲艺人表中有1,0842首歌曲。这是因为有些艺人的某些歌曲太过老旧,用户点播率较低。而歌曲和用户记录数据是随机抽样得到的,因此产生这种情况。
- 歌曲语言数据Language和性别Gender是做过脱敏处理的类型数据,官方给出Gender分别代表着女性,男性和乐队。语言估计有汉语,粤语,英语等等。这两个记录值需要画图分析它与预测播放量有什么关系,也许可以分类不同类型的艺人时间序列趋势走向。
实验结果发现:
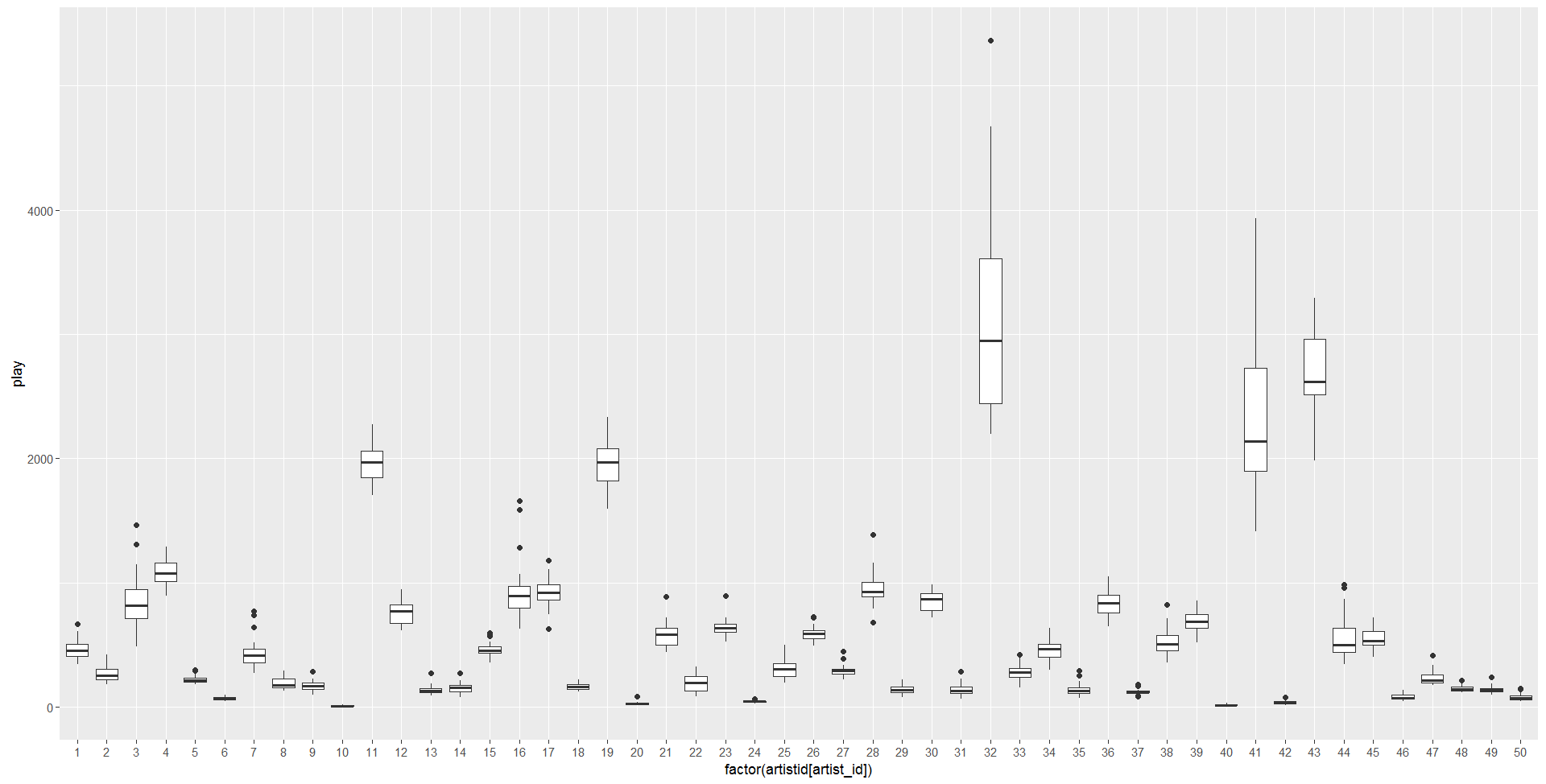
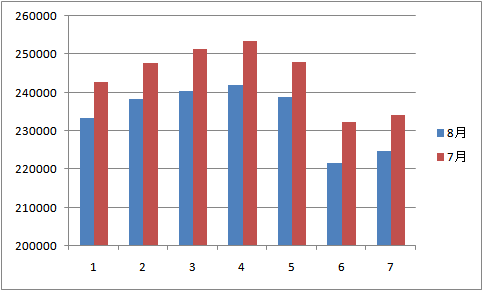
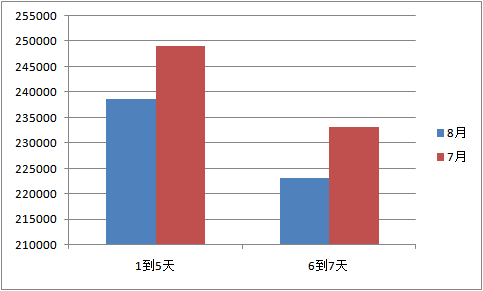
1、用距离预测时间最近的时间段作为预测值是比较理想的方法,因此在初赛时尝试画出50艺人在8月内的播放量取值箱形图。如下,可以看到每个艺人各自8月每日播放量数值,可以从图中区分高播放量的艺人和一般播放量的艺人。根据评分指标,若能将播放量越大的艺人预测越准,评分会提升。因此很明显要对高播放量的艺人序列多加关注,同时应该进一步研究艺人序列的分类方法。
2、 如下画出按性别和语言分类的8月艺人播放量取值箱形图,以及对应类别艺人数据量的柱状图,由于有些艺人的不同歌曲语言不同,因此这里的语言类别是按照艺人最常用的歌曲语言做分类。从图中粗略判断性别为3的艺人播放量最低,语言1,4,11的艺人的每日播放量较高。
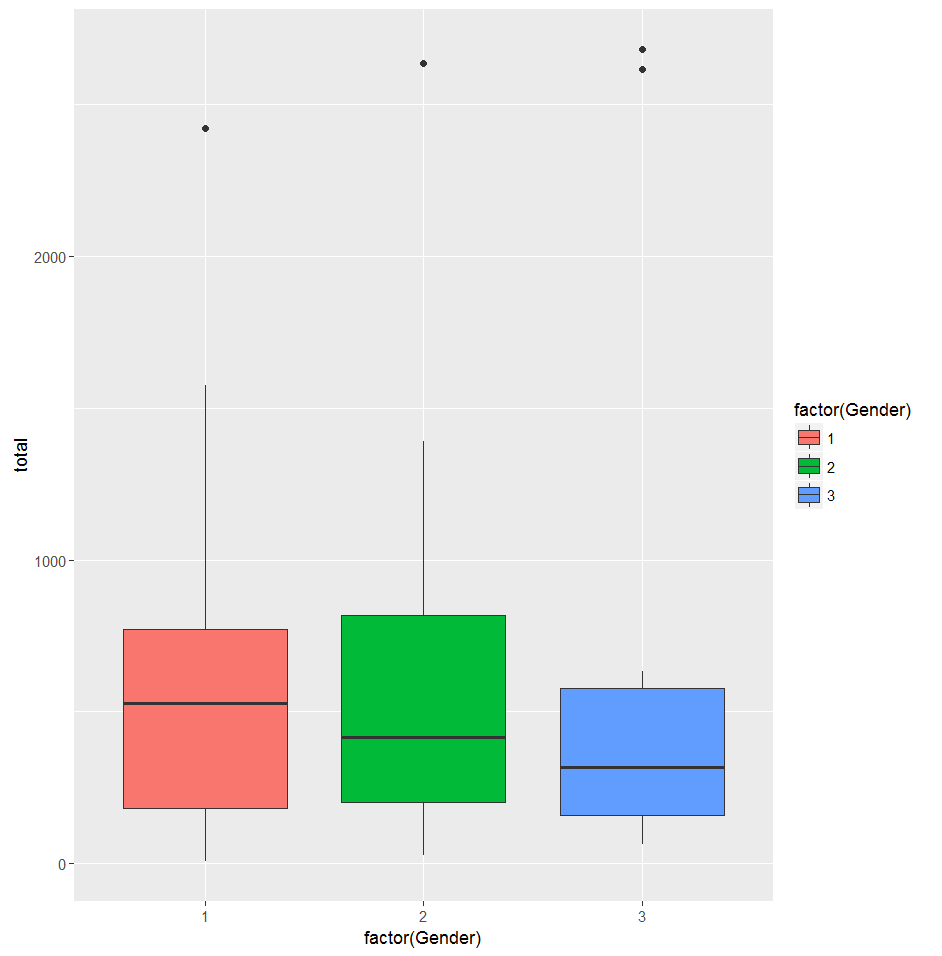
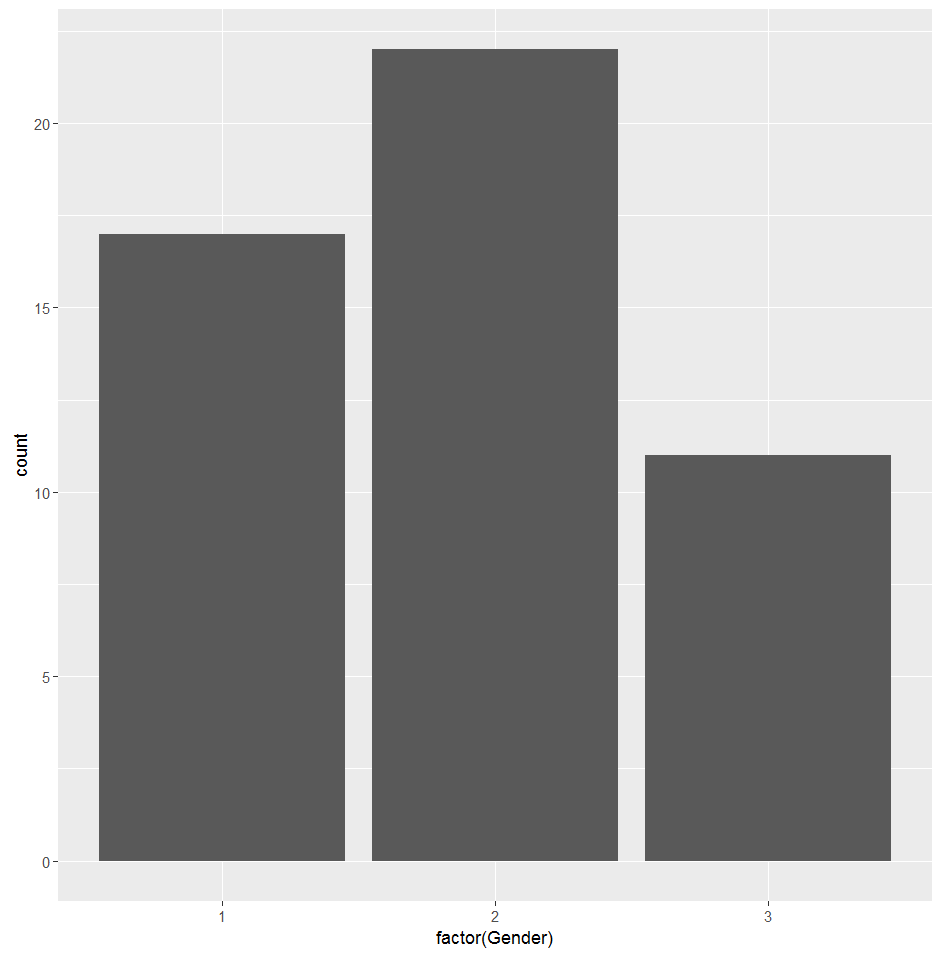
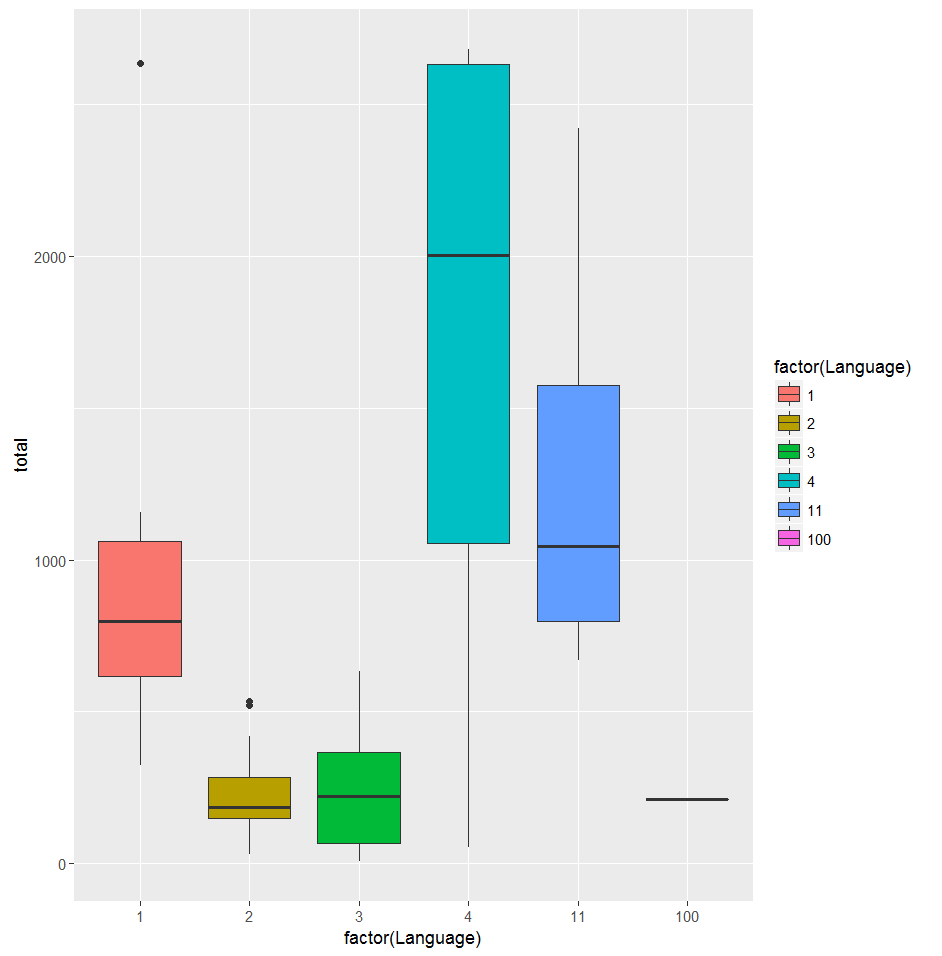
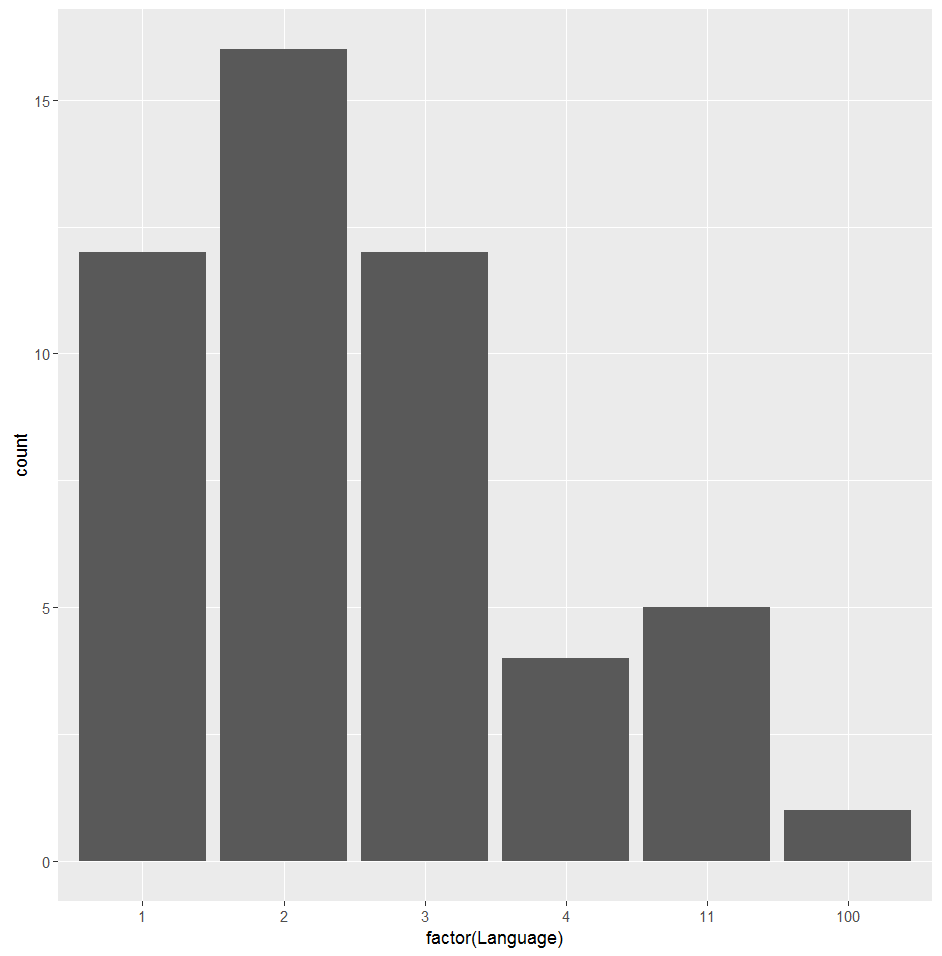
如下是按照8月30日的每个艺人的播放量值,以语言分类为横坐标,颜色值区分艺人性别,发现性别为3的艺人播放量并不一定最低,而语言为1,4,11的艺人播放量满足8月播放量相对较高,或者其高低播放量差距较大的数据规律。于是可以尝试按语言将艺人分类,初赛时尝试将Language=1,4,11定义高播放量密集区,对这21个艺人做细致研究,剩余29个艺人直接用0830作为预测值。在这21艺人中挑选出重点研究艺人,其满足要不是数值比较高,要不是分布比较稳定的时间序列规律,最后筛选了13个艺人高播放量艺人研究预测。

如图是Language=1,4,11的艺人对应的8月密度曲线,可以看出Language=4,11时密度曲线有2座波峰,而1的时候则以一波峰为主,右侧有大量尾巴。这些信息可以作为区分高播放量艺人和普通艺人的边界。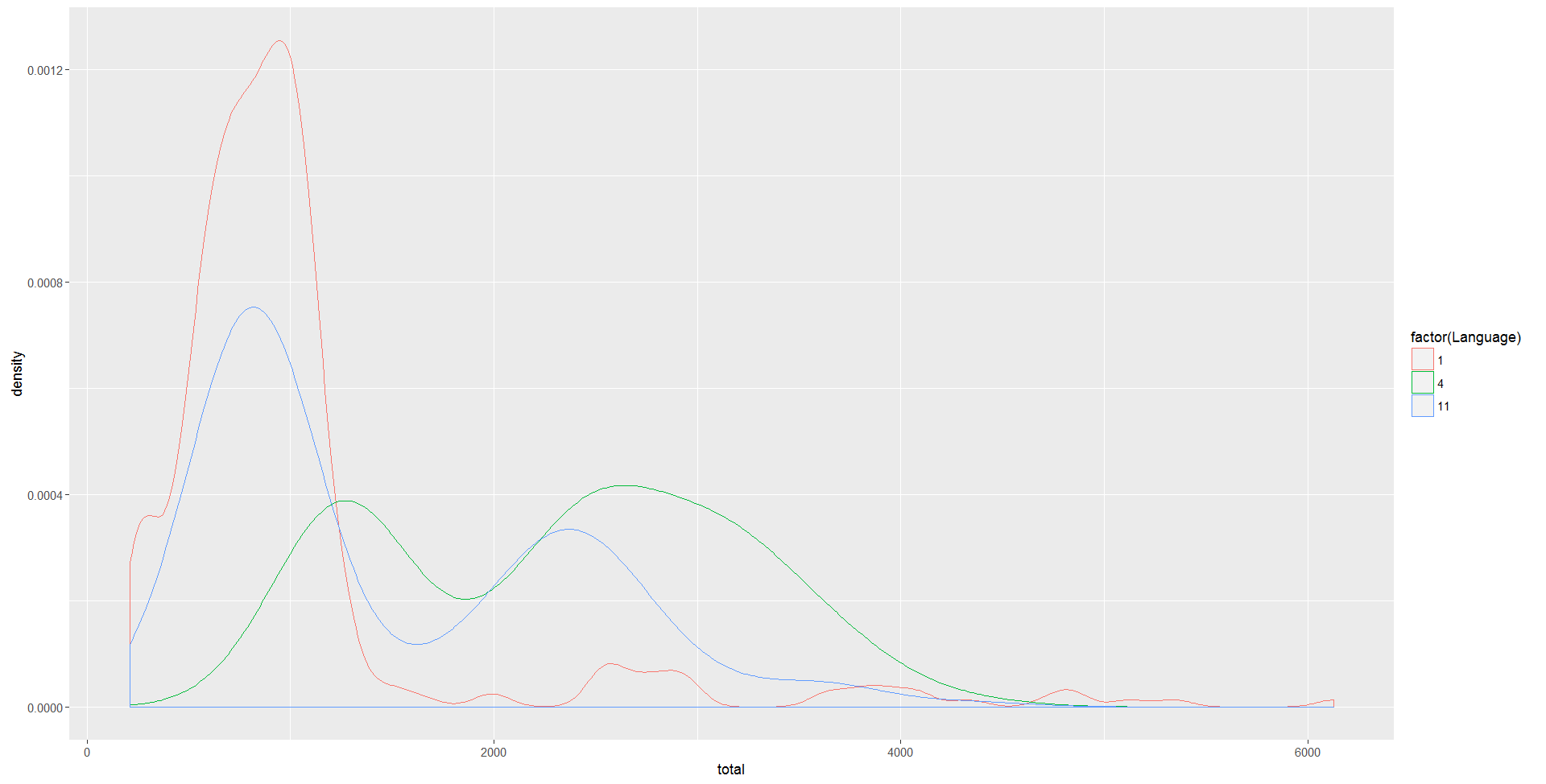
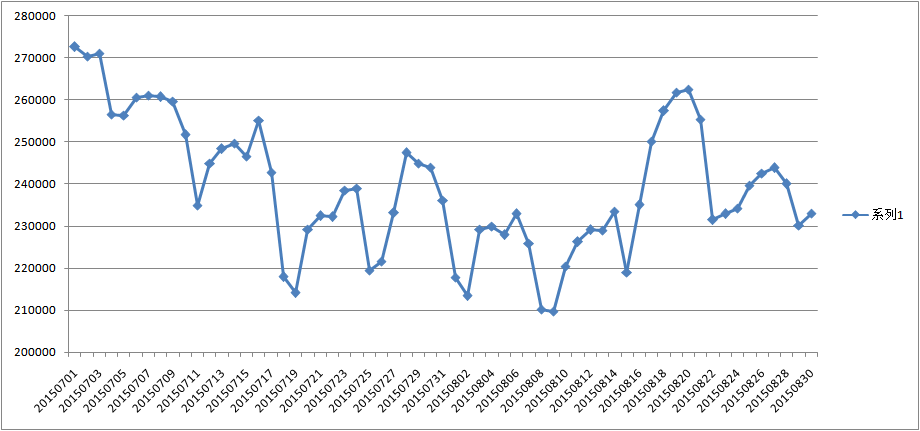
3、论坛和群里有人研究gmt_create每小时的用户记录,然而并未找到明显规律。但查看总体艺人的周播放量,确实存在着周期规律。以复赛时100艺人最高播放量为例,如下是其7、8月时序图,除了7月初(7月7日)前,之后基本是平稳的。(详细参看阿里音乐预测小结2——艺人周期规律)
按每周7天计算每月平均播放量如下,可以发现这个分布规律与工作节假日规律相关
根据之前群友提供的听歌年龄分布,用户在25到31岁所占比重最大,这类人大部分是上班族,因此每日听歌习惯就是和上班习惯挂钩,基本符合如下上班族规律:
- 周1,2好好工作精神饱满
- 周3、4疲劳成极写不进去
- 周5快要节假再恢复精神工作一点
- 周6、7逛街玩耍,休息Hi起来
根据上图,由于大部分人听歌是用来放松的,也就是说最疲劳的时候(周三)最需要放松,此时听歌人数剧增,而周6、7节假日相对放松活动选择很多,听歌人数反而不多。由此可以按照工作日和节假日来区分,很明显7、8月每个月都是节假日要比工作日低一些:
在复赛时,艺人种类较多,不同艺人的周期规律都会影响时间序列结果。因此可以按照周期规律作为艺人的分类依据。
4、观察publish_time在2015年3月到8月的内对应的艺人时间序列图像,确实在该日期点附近存在起伏或者突增。但是由于在2015年9、10月的publish_time记录较少,而这种突增现象不好度量,因此暂不考虑。根据publish_time可以发现有的艺人每年会更新,这类艺人比较活跃,时间序列起伏明显;有的艺人已经停更了,停更的艺人时间序列就平稳的。以此也可以作为艺人分类依据。
官网给出song_init_plays收录的音乐大小不准,播放量只是一个参考,是3月1号之前的统计,因此暂时不用。
3、基础模型
建模初期,主要是集中在预处理数据和基础模型的建立。
预处理-->提取特征并筛选-->模型(多个自变量预测一个连续因变量值)-->预测-->评估
3.1预处理
3σ准则:它是先假设一组检测数据只含有随机误差,对其进行计算处理得到标准偏差,按一定概率确定一个区间,认为凡超过这个区间的误差,就不属于随机误差而是粗大误差,含有该误差的数据应予以剔除。3σ原则为:
- 数值分布在(μ-σ,μ+σ)中的概率为0.6826
- 数值分布在(μ-2σ,μ+2σ)中的概率为0.9544
- 数值分布在(μ-3σ,μ+3σ)中的概率为0.9974
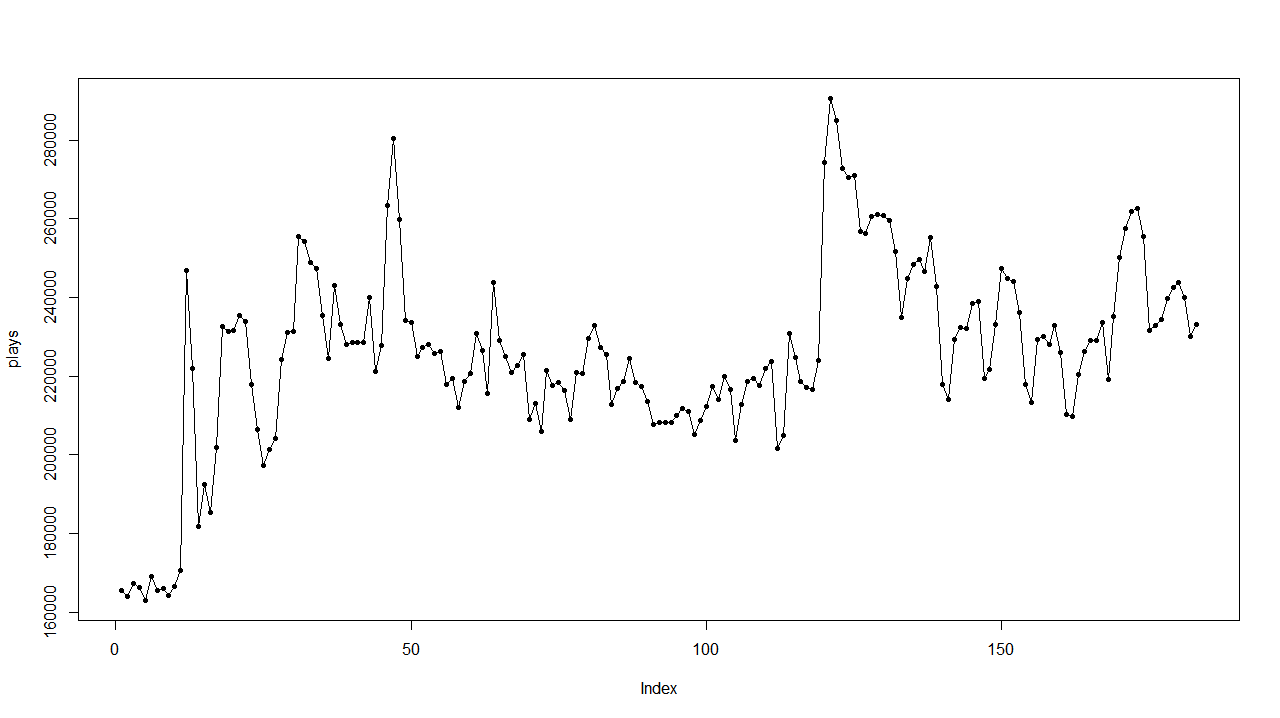
因为艺人和用户数据是随机抽样,且数据量较大,大部分艺人时间序列符合正态分布的密度曲线,下是部分艺人8月每日播放量的密度曲线。我们就按照2倍标准差(SD)的方法粗略的剔除数据。
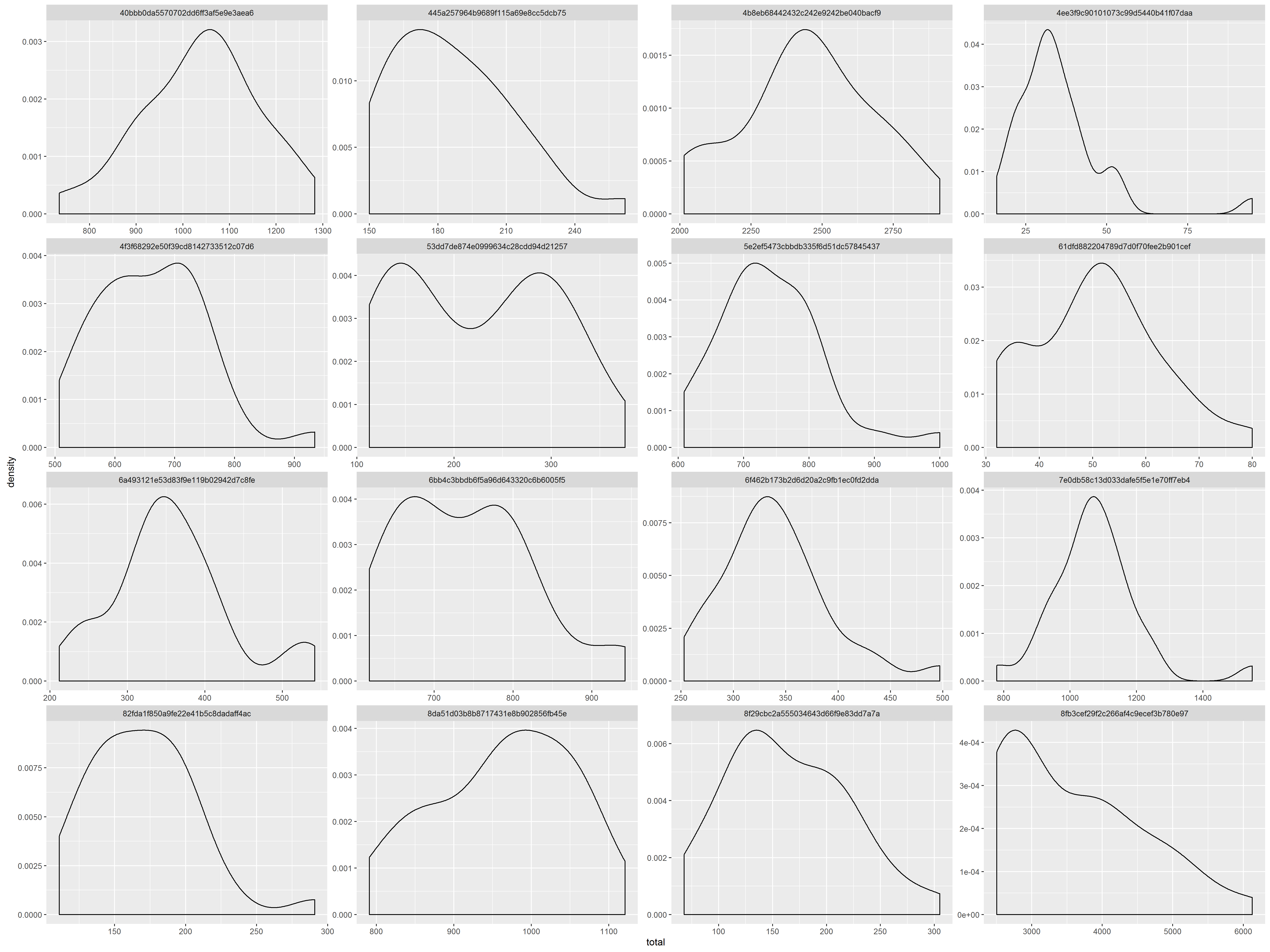
但这种预测结果也并不一定完全正确,因为前提假设需满足正态分布。观察如下的艺人播放量并不一定存在有异常数据,但是用2sd数据剔除异常后,在第0天附近的较低的播放量将会被剔除掉。
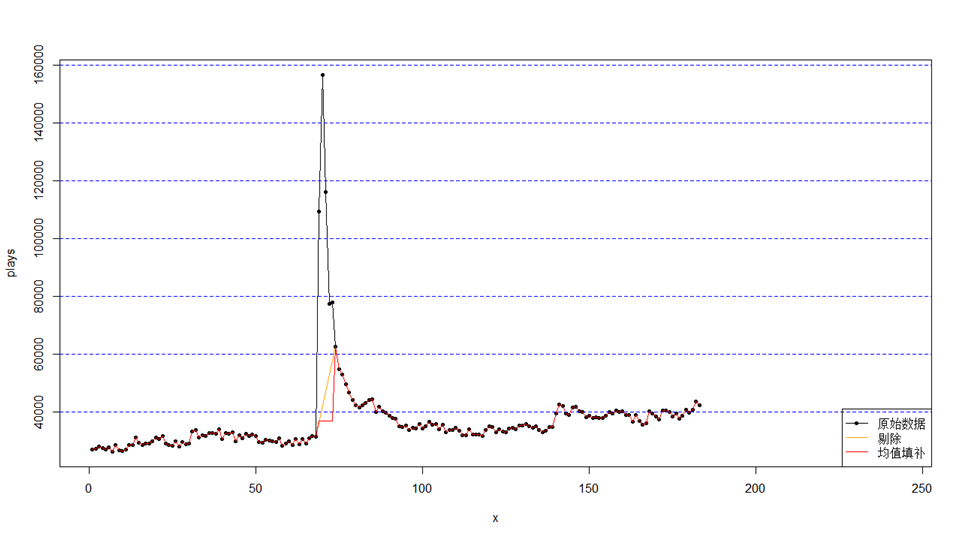
其次,若回归模型中以时间作为变量,剔除掉的空缺时间数据需要被填补,如下所示:
3.2建立基础模型
建模初期,根据规律:用距离预测时间较近的时间段作为预测值比较准确。
- 单点预测方法:以最后一天8月30日播放量,8月最后一周,8月下半月,8月,以及7月8月的中值和均值日播放量作为艺人的预测结果。
- 多点预测方法:线性回归模型,时间序列模型
3.3线上线下评估
除了每天10点的线上提交评分,线下测试评分可以辅助预测建模结果。根据评分指标,在线下以3月到6月数据为测试集,以7、8月艺人播放量作为结果集,计算线下评分。但根据实际测评结果,不同模型下线上线下测评结果有很多出入。
三、分类与预测
3.1分类
根据规律,可以按照用户,艺人分别进行分类
1)按用户分类
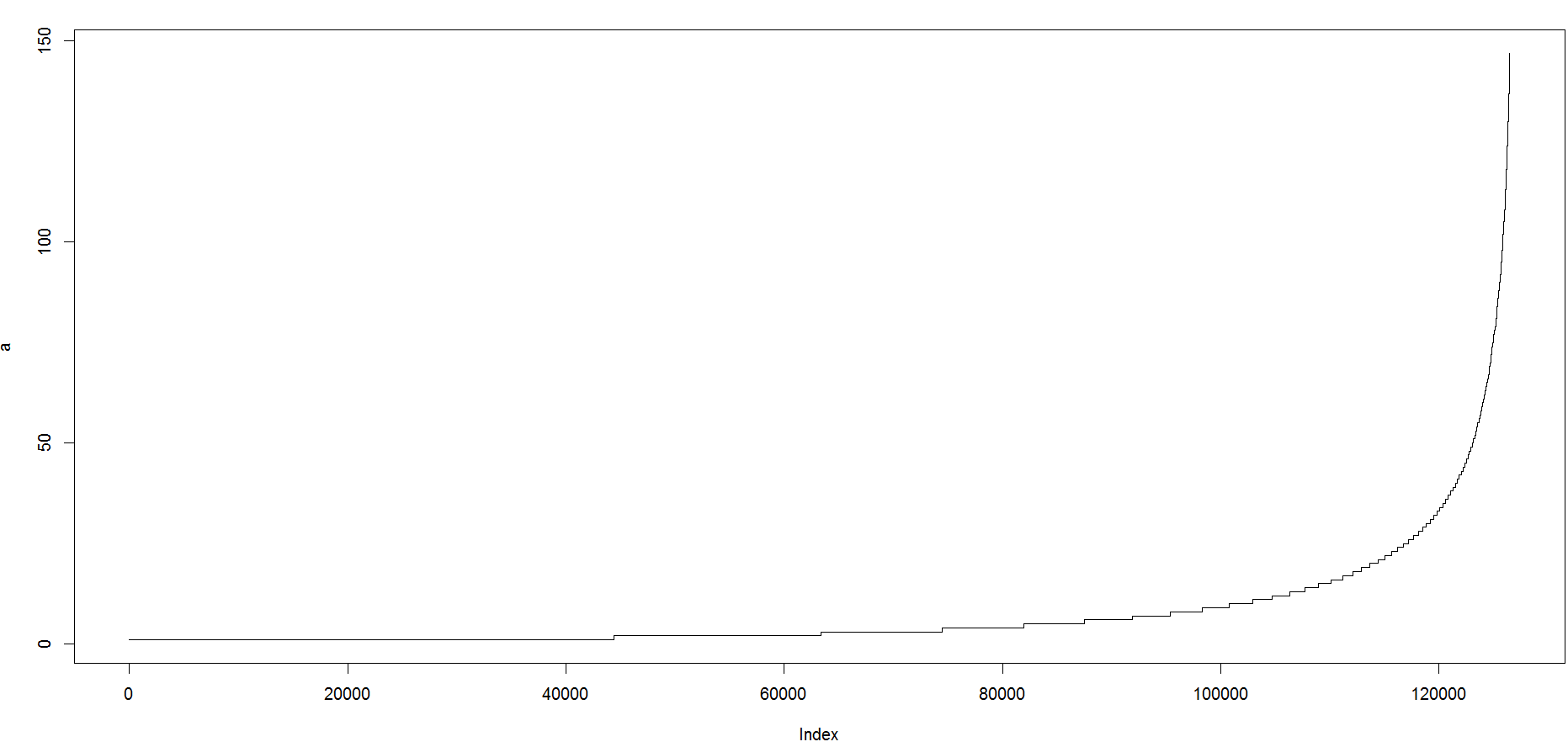
- 参考2015年公交线路预测冠军袁光浩PPT中的分类方法,以初赛播放量最高艺人为例,画出该艺人的用户183的播放量图像,如下是将用户总小到大取前126499个(99.5%)用户的图像:横轴是用户按播放量从小到大的编号,纵轴是用户总播放量。(详细参看阿里音乐预测小结1——用户分类与建模)
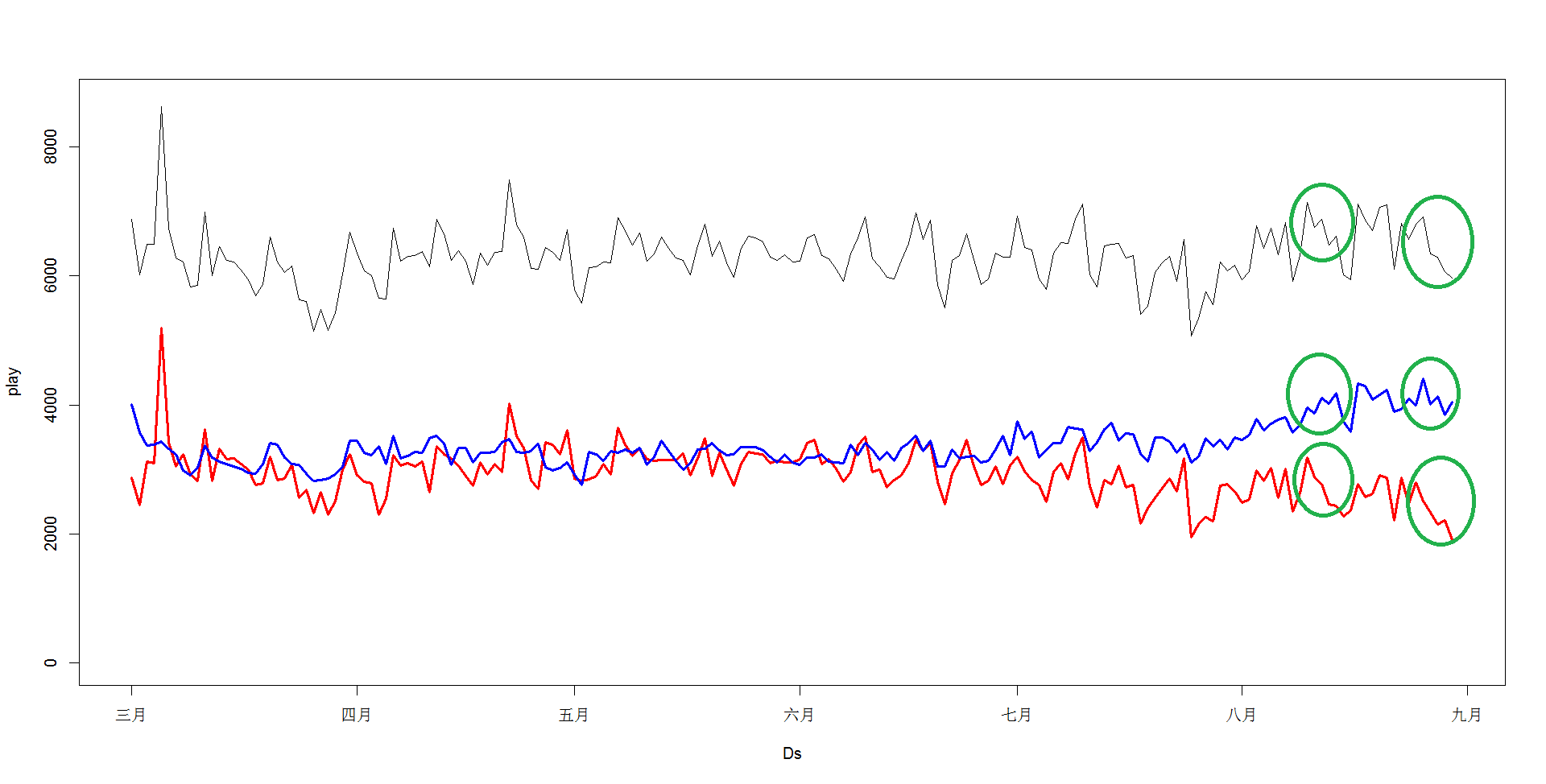
可以看到用户两级分化,一部分用户的播放量特别的小,不到50;另一部分特点的大,超过150。由此考虑对艺人的用户分类为粉丝用户和随机用户2类。设n=35,此时总用户人数是12,7135,一般用户a有12,0375,粉丝用户b有6760个,而此时一般用户a总播放量61,7199;粉丝用户b总播放量为53,6210,2类用户的播放量值恰巧接近总播放量的一半。这说明一般用户和粉丝用户对艺人的播放量的取值贡献都很重要。如图是艺人每日的播放量(黑线),一般用户a(蓝线)和粉丝用户b(红线)的播放量,其中绿色圈圈明显看到两类用户将原先混杂在一起的总播放量序列时间规律区别开来。从图中可以看出不同的用户点播趋势是不同的:一般用户上升,粉丝用户下降。
进一步分析,根据公式:
艺人当日播放量=艺人当日用户数*当日用户平均点播量
分别研究艺人每日用户平均播放量和每日点播用户数
- 每日平均点播量
如图:粉丝用户(红线)每日平均播放量有二次曲线的下降趋势,这可以解释总播放量那张图粉丝用户是下降的;一般用户(蓝线)相比于粉丝用户每日平均播放量基本是一个平稳的正态序列。
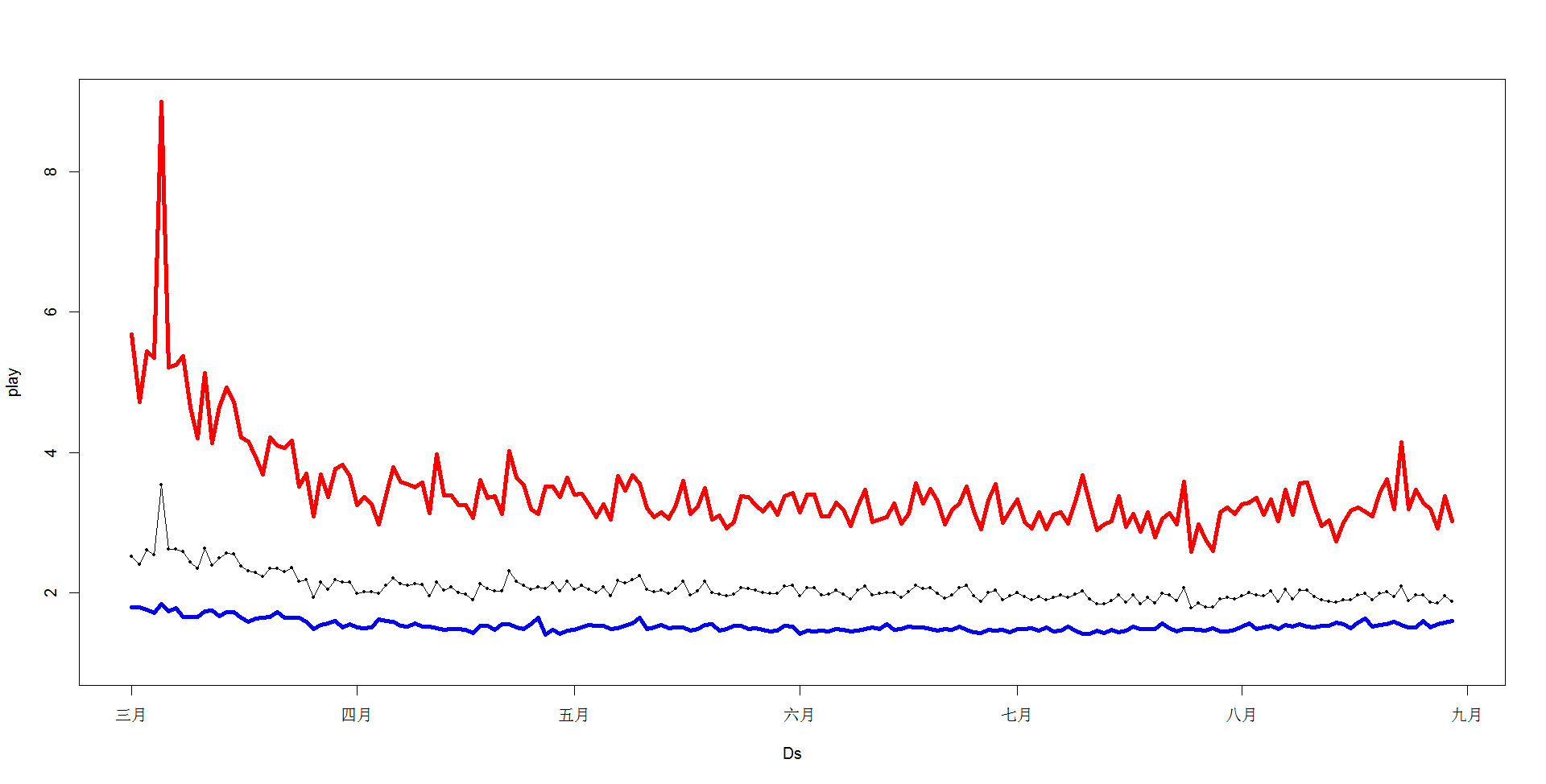
- 每日用户人数
如图,所有序列都呈现出较强的周期性(一周7天的特征),一般用户(蓝线)每日用户数呈上升趋势,这可以解释总播放量那张图一般用户是上升的;粉丝用户(红线)每日用户人数先增多后减少;但相比于一般用户,人数趋于平稳序列(极差大概是500)。
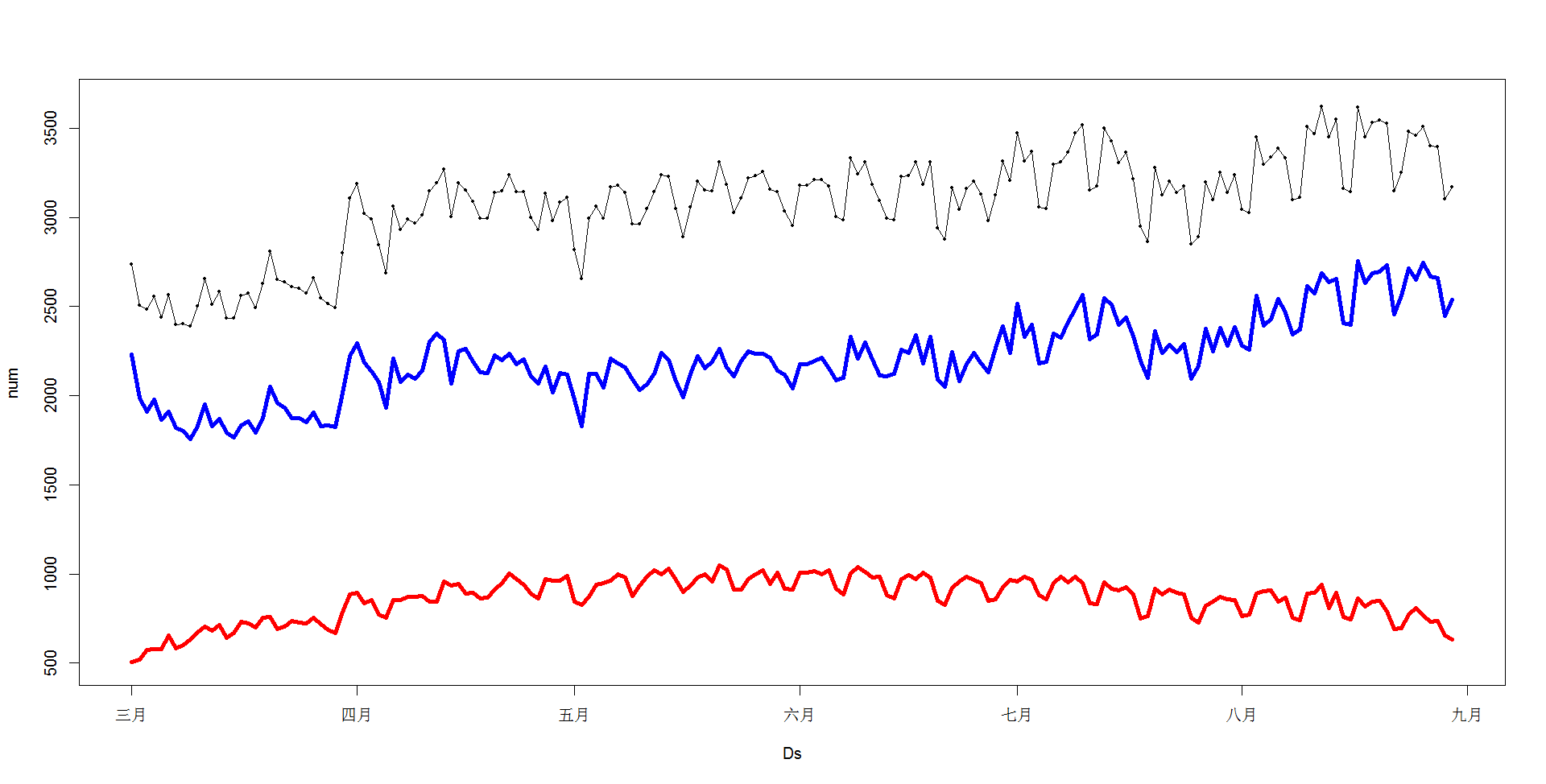
从以上规律总结,可以将2类用户的每日播放量分解为每日平均用户点播量和每日用户人数的乘积,并且大致符合以下规律:
- 每日平均点播量(无周期)
1、粉丝用户序列b1:有趋势2、一般用户序列a1:平稳
- 每日用户人数(有周期,7天)
1、粉丝用户序列b2:平稳2、一般用户序列a2:有趋势
由此挖掘出一个规律是:
1、粉丝用户的每日平均播放量(b1)和一般用户的每日用户人数(a2),把2个时序分开做线性回归,a1和b2用均值代替(平稳序列),再代入公式:该play=a1*a2+b1*b2
2、周期,从每日用户人数中获取。
但由于时间限制以及当时知识能力限制,并未再深入研究,后续看了比赛答辩PPT后发现这是有可行性的方法,可以深入研究。
2)按艺人分类
在复赛中,我们是根据每个艺人8月播放量均值画出散点图,可以很清晰的发现分类分界线是15000,将其分为2类:高播放量艺人和低播放量艺人,同时以8月均值作为60天每天的实际播放量,用评分公式计算完全预测准确时F值为64296.57135,其中高播放量艺人F总和为31413.58217,低播放量艺人F为32882.98918,恰巧是总F值的一半,说明这2类艺人的评分都不可忽略。
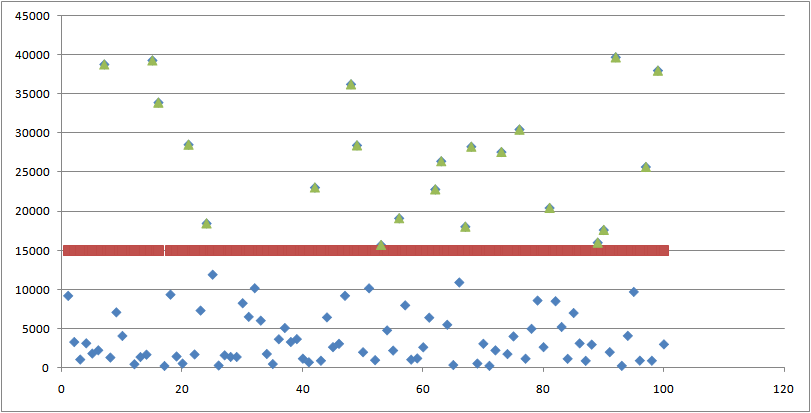
这种分类过于粗略,学习了top5答辩模型后发现,需要做更加细致的分类处理,才会有好的结果。
3.2建模
初赛是在线下,因此可以利用模型软件尝试较多种模型,建模方法有:
- 规则
- 单独时间序列
- 单独线性回归
- 线性回归+(残差)时间序列AR模型
从最后评分结果来看,这种由前183天去预测后2个月(共60天)的问题,简单的用时间序列方法,由于预测时间跨度太长,结果总是收敛成一条直线,效果并不理想。
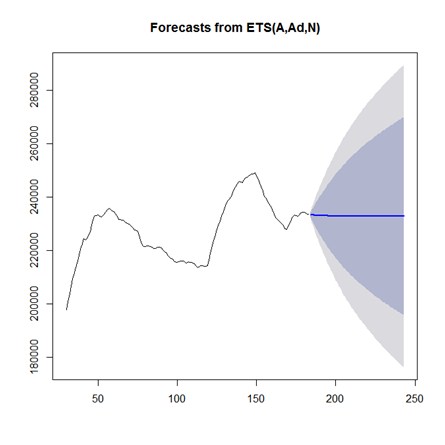
多元线性回归(橘线)在一些周期性规律强烈,趋势较为平稳的时序下是不错的选择,如下图所示,其中自变量由连续变量天数,每周第几天,每月第几天,每季第几天,特殊天数等时间规律的虚拟变量组成。
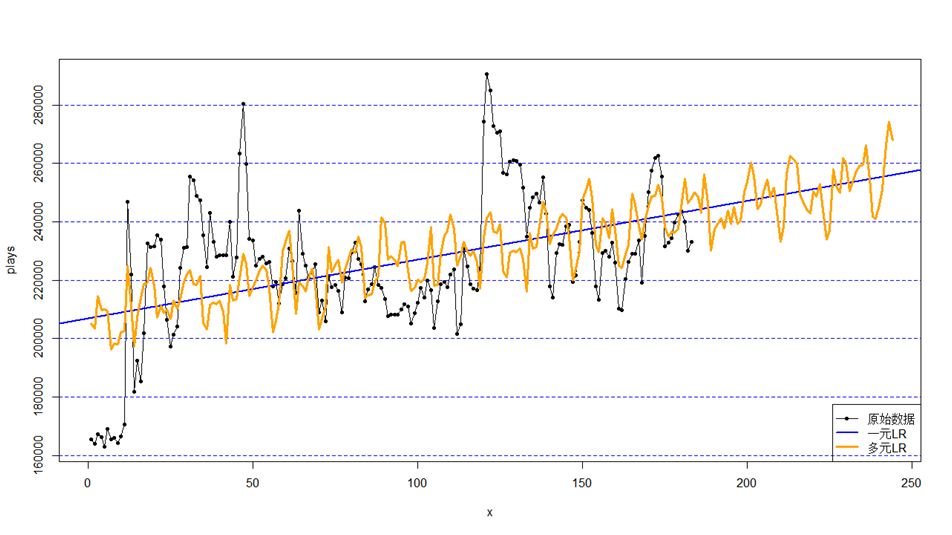
并且在线下可以结合AR时序模型修正回归模型(蓝线),如图所示:

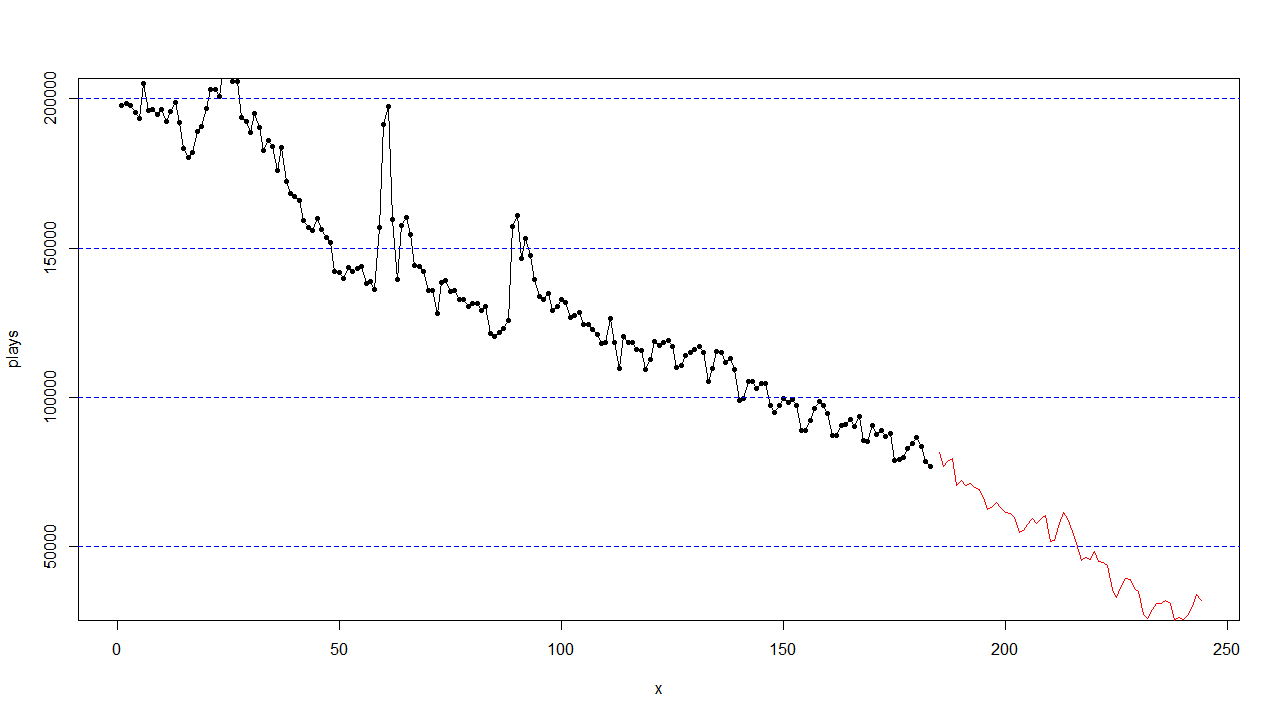
但线性回归并不适用于所有艺人序列,如图所示,这些预测结果偏差过大。


线上评分结果证实,就算如下所示的预测结果也会降分,估计该趋势最后在某一处是趋于平稳了,因此不能单纯对所有艺人使用此模型拟合,仍需要对艺人序列做更细致的划分类别
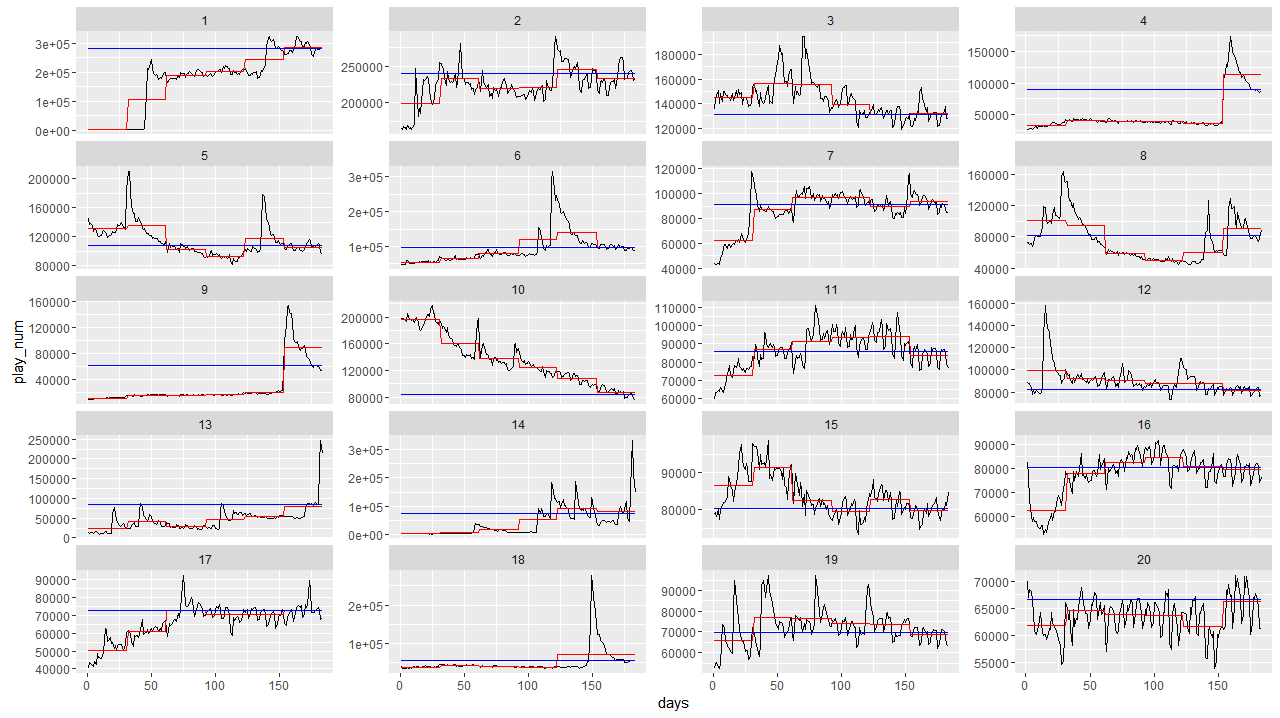
因此转而研究艺人时间序列的规律,如图是按播放量从高到底排序前20名艺人时间序列,蓝线是以8月下半月的中值作为y值所画直线,红线是由每个月的均值组成的分段函数,经过观察,时序曲线大致分为
- 总体趋势上升性或下降至平稳型
- 无月季规律波动水平曲线
- 有周期规律波动水平曲线
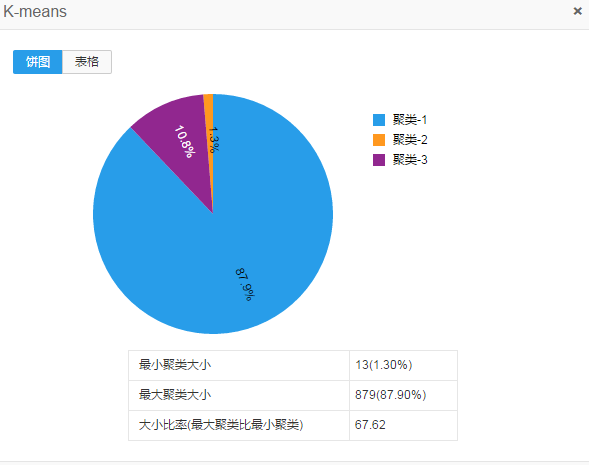
复赛曾尝试对时间序列用形状,分维数,加权周长等特征结合月季同比增长量和增长率对1000条艺人序列进行聚类,然而效果并不很好,大部分序列聚在一类里,并不能突出以上分类方法。
由于时间,平台,以及自身知识的制约,最终以规则模型居多,结合部分多元线性回归模型作为最好的提交结果。复赛得分:493919,排名84/500
四、总结
第一次打比赛,边学边比,队友也是在比赛中结交认识的。对我来说是一次挑战,但也确实获得了不少经验教训。尤其是在赛后群里的交流以及8月的精彩答辩,都让我获益匪浅。在这里总结3点经验:
1、化简思路,从最简单的做起,模型不是一蹴而成,是在基础模型上一步步精细化加工得到的。比如,比赛中最初有很多赛友用了复杂的模型预测60天每天的结果,然而效果却都没有单点规则取值好。这道题最经典的预测技巧是将60天的预测化简为单点的预测,这可以根据公式推导,除了规则方法,还可以进一步为此建立复杂模型,如第13名的赛友的滑窗方法http://blog.csdn.net/lujiandong1/article/details/51933158。
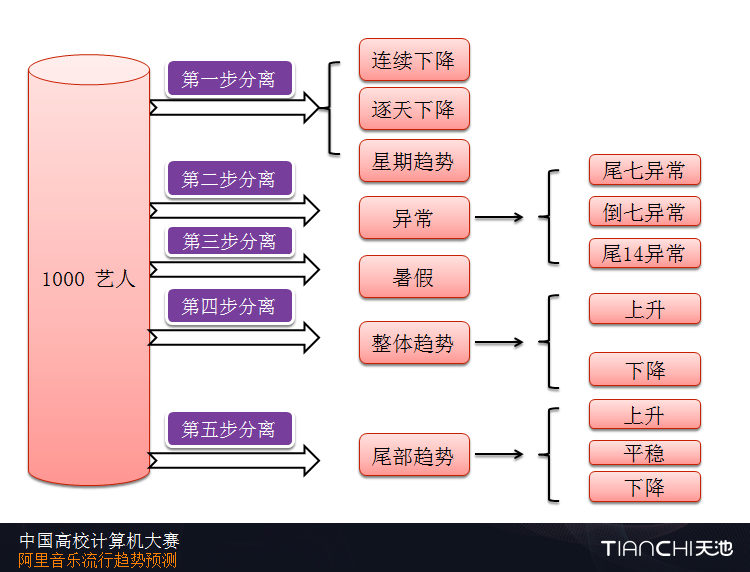
2、深入挖掘,必须细化分类,如图是季军答辩模型,由此可见,高手是对数据业务做了细致的分类后再一步步提高分数的。
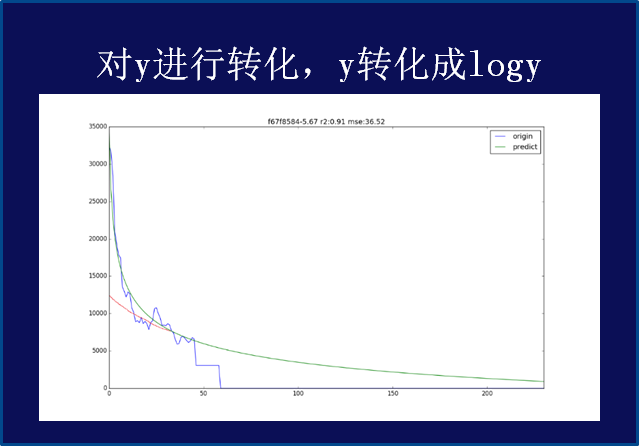
3、对于这种实际上不完全正态分布数据的一个处理技巧:大数处罚的方法:log变换
赛后有群友向我们科普、几乎任何模型,或者任何基于平均值的规则,都已经假设目标服从正态分布,如果目标不服从正态,做log转换会让它更接近正态,由此提分不少。
如下来自极客奖COM团队答辩PPT
除此,许多人对评估指标做了深入的数学推到研究,大家各显高招,尽管思路不同,其实只要坚持细钻下去,总会有结果的。而我们团队对于数据的认识还太过粗糙,应高去做进一步精细化思考。

