


ELK+Filebeat+Kafka+ZooKeeper构建大数据日志分析平台
1、平台架构图如下:
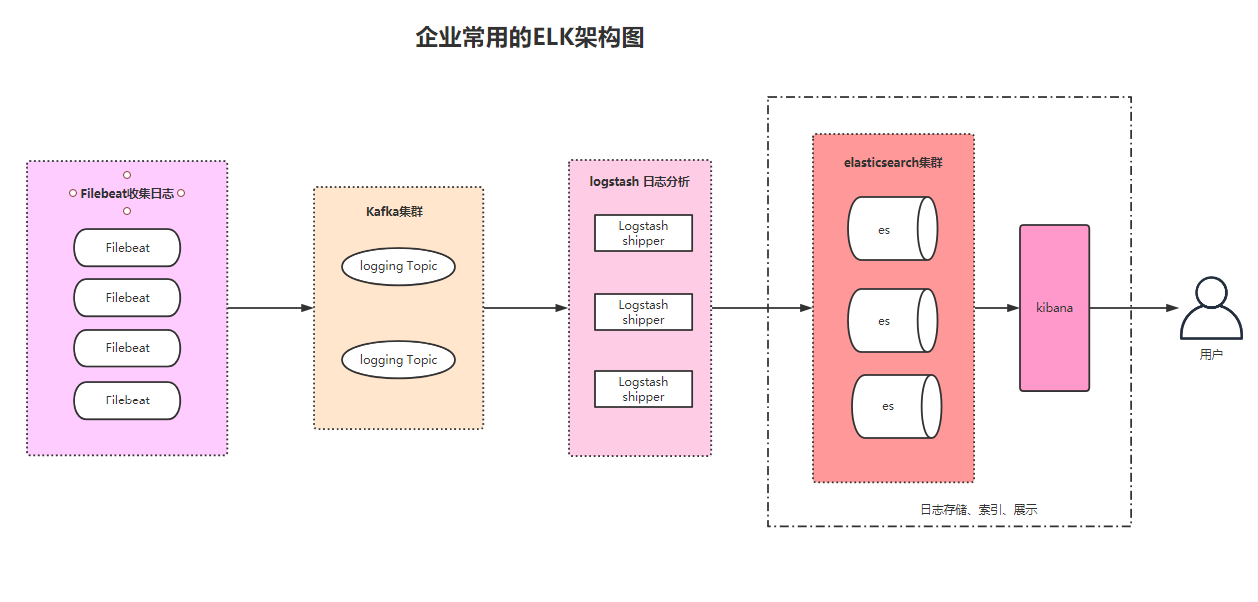
2、准备搭建环境,具体使用服务器架构如下:
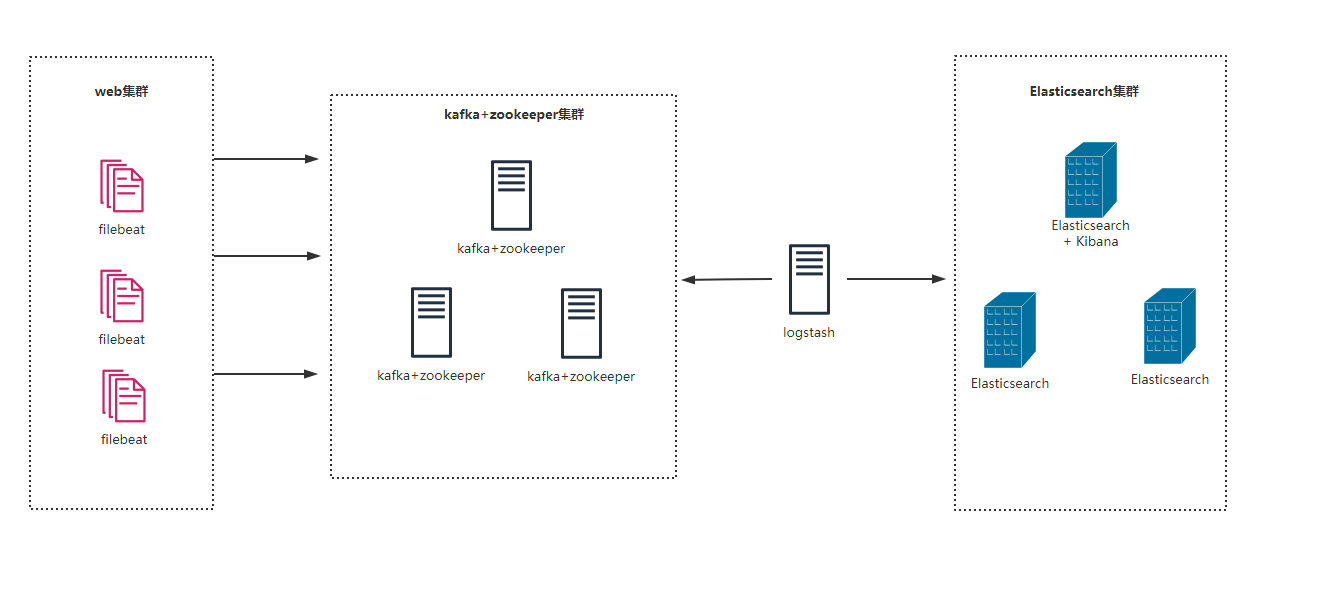
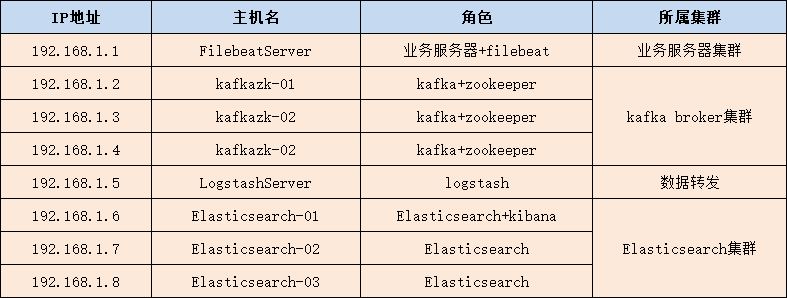
kafka和zookeeper集群最少需要3台服务器,logstash需要1台,Elasticsearch集群最少需要3台服务器,filebeat需要1台,最少需要8台服务器。具体服务器列表如下:
1、部署elasticsearch集群
关闭防火墙和sellinux
#停用防火墙 systemctl stop firewalld.service #禁止开机启动 systemctl disable firewalld.service
由于elasticsearch需要java 11 版本,首选官网下载jdk并安装:
rpm -ivh jdk-11.0.8_linux-x64_bin.rpm [root@localhost local]# java -version java version "11.0.8" 2020-07-14 LTS Java(TM) SE Runtime Environment 18.9 (build 11.0.8+10-LTS) Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.8+10-LTS, mixed mode)然后
官网下载elasticsearch安装包,本次使用的版本是7.8.1,下载地址:
我们把elasticsearch安装到/usr/local目录下
tar -zxvf elasticsearch-7.8.1-linux-x86_64.tar.gz -C /usr/local/ mv elasticsearch-7.8.1/ elasticsearch
下面是elasticsearch解压目录的内容

由于elasticsearch可以接收用户输入的脚本并执行,为了系统安全考虑,需要创建一个单独用户用来运行elasticsearch,这里我们就创建elasticsearch用户,操作如下:
useradd elasticsearch 然后将elasticsearch的安装目录都授权给elasticsearch用户 chown -R elasticsearch:elasticsearch /usr/local/elasticsearch
2、操作系统调优
操作系统调优以及JVM调优主要针对安装elasticsearch的机器,对于操作系统,需要调整几个内核参数,将下面的内容添加到/etc/systctl.conf 文件中:
#配置系统最大的打开文件描述符数,建议改为655360或更高 fs.file-max=655360 #影响JAVA线程的数量,用于限制一个进程可以拥有VMA(虚拟内存区域)的大小,系统默认65530,建议改成262144或更高 vm.max_map_count=262144
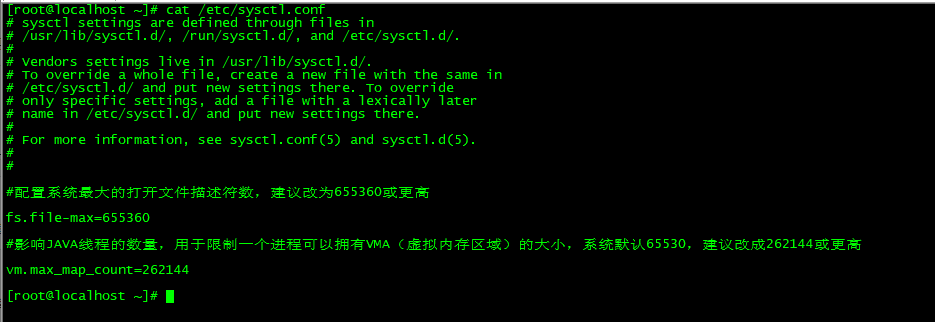
使修改的参数生效。 [root@localhost ~]# sysctl -p fs.file-max = 655360 vm.max_map_count = 262144
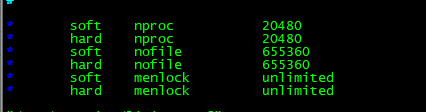
另外,还需要调整进程最大打开文件描述符(nofile),最大用户进程数(nproc)和最大锁定内存地址空间(memlock),添加内容到/etc/security/limits.conf
* soft nproc 20480 * hard nproc 20480 * soft nofile 655360 * hard nofile 655360 * soft menlock unlimited * hard menlock unlimited
centos 7系统还需要修改/etc/systemd/system.conf ,分别修改以下内容。
DefaultLimitNOFILE=65536 DefaultLimitNPROC=32000 DefaultLimitMEMLOCK=infinity
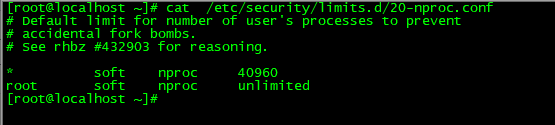
最后还需要修改/etc/security/limits.d/20-nproc.conf (centos 7.x系统),修改如下:
使上面的修改过的配置生效,只需要退出登录,重新登录即可,可以使用ulimit -a 查看。最好重启下系统
3、JVM调优
-Xms512m
-Xmx512m

