

MySQL中的索引
1.2.1.B+树索引
InnoDB中的索引自然也是按照B+树来组织的,前面我们说过B+树的叶子节点用来放数据的,但是放什么数据呢?索引自然是要放的,因为B+树的作用本来就是就是为了快速检索数据而提出的一种数据结构,不放索引放什么呢?但是数据库中的表,数据才是我们真正需要的数据,索引只是辅助数据,甚至于一个表可以没有自定义索引。InnoDB中的数据到底是如何组织的?
1.2.1.1.聚集索引/聚簇索引
InnoDB中使用了聚集索引,就是将表的主键用来构造一棵B+树,并且将整张表的行记录数据存放在该B+树的叶子节点中。也就是所谓的索引即数据,数据即索引。由于聚集索引是利用表的主键构建的,所以每张表只能拥有一个聚集索引。
聚集索引的叶子节点就是数据页。换句话说,数据页上存放的是完整的每行记录。因此聚集索引的一个优点就是:通过过聚集索引能获取完整的整行数据。另一个优点是:对于主键的排序查找和范围查找速度非常快。
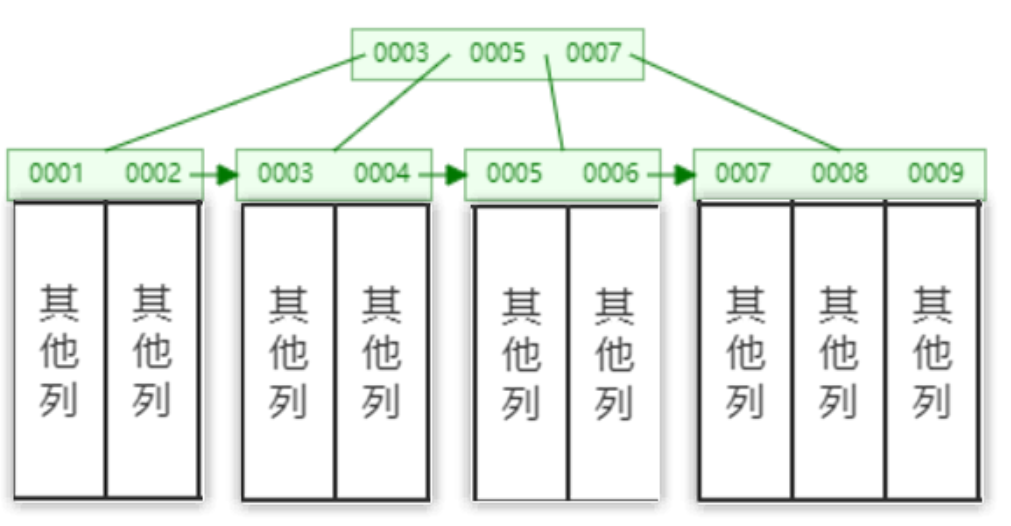
如果我们没有定义主键呢?MySQL会使用唯一性索引,没有唯一性索引,MySQL也会创建一个隐含列RowID来做主键,然后用这个主键来建立聚集索引。
1.2.1.2.辅助索引/二级索引
聚簇索引只能在搜索条件是主键值时才能发挥作用,因为B+树中的数据都是按照主键进行排序的。
如果我们想以别的列作为搜索条件怎么办?我们一般会建立多个索引,这些索引被称为辅助索引/二级索引。
(每建立一个索引,就有一颗B+树
对于辅助索引(Secondary Index,也称二级索引、非聚集索引),叶子节点并不包含行记录的全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了一个书签( bookmark)。该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对应的行数据。因此InnoDB存储引擎的辅助索引的书签就是相应行数据的聚集索引键。
比如辅助索引index(node),那么叶子节点中包含的数据就包括了(note和主键)。
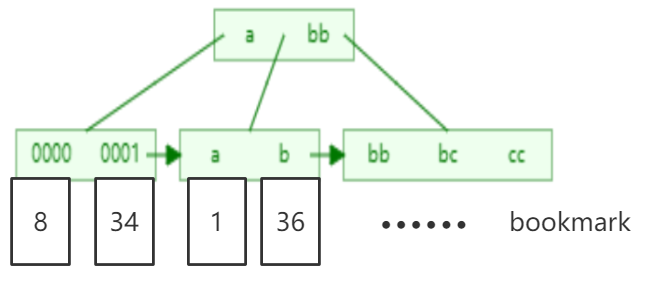
1.2.1.3.回表
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。当通过辅助索引来寻找数据时,InnoDB存储引擎会遍历辅助索引并通过叶级别的指针获得指向主键索引的主键,然后再通过主键索引(聚集索引)来找到一个完整的行记录。这个过程也被称为 回表 。也就是根据辅助索引的值查询一条完整的用户记录需要使用到2棵B+树----一次辅助索引,一次聚集索引。
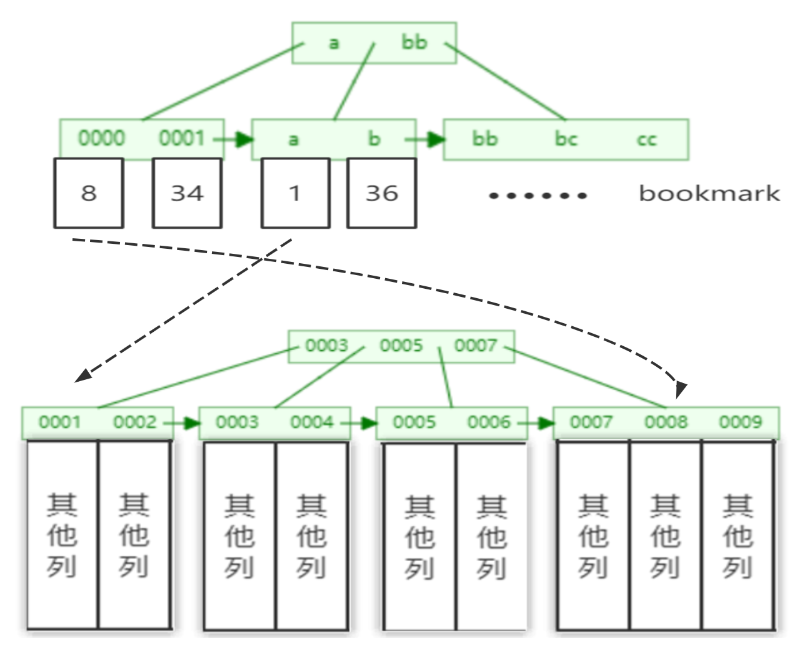
为什么我们还需要一次回表操作呢?直接把完整的用户记录放到辅助索引d的叶子节点不就好了么?如果把完整的用户记录放到叶子节点是可以不用回表,但是太占地方了,相当于每建立一棵B+树都需要把所有的用户记录再都拷贝一遍,这就有点太浪费存储空间了。而且每次对数据的变化要在所有包含数据的索引中全部都修改一次,性能也非常低下。
很明显,回表的记录越少,性能提升就越高,需要回表的记录越多,使用二级索引的性能就越低,甚至让某些查询宁愿使用全表扫描也不使用二级索引。
那什么时候采用全表扫描的方式,什么时候使用采用二级索引 + 回表的方式去执行查询呢?这个就是查询优化器做的工作,查询优化器会事先对表中的记录计算一些统计数据,然后再利用这些统计数据根据查询的条件来计算一下需要回表的记录数,需要回表的记录数越多,就越倾向于使用全表扫描,反之倾向于使用二级索引 + 回表的方式。
1.2.1.4.联合索引/复合索引
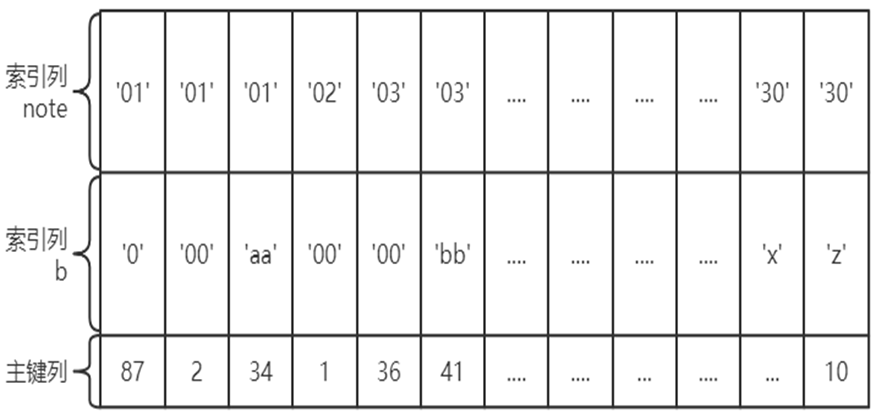
前面我们对索引的描述,隐含了一个条件,那就是构建索引的字段只有一个,但实践工作中构建索引的完全可以是多个字段。所以,将表上的多个列组合起来进行索引我们称之为联合索引或者复合索引,比如index(a,b)就是将a,b两个列组合起来构成一个索引。
千万要注意一点,建立联合索引只会建立1棵B+树,多个列分别建立索引会分别以每个列则建立B+树,有几个列就有几个B+树,比如,index(note)、index(b),就分别对note,b两个列各构建了一个索引。
而如果是index(note,b)在索引构建上,包含了两个意思:
1、先把各个记录按照note列进行排序。
2、在记录的note列相同的情况下,采用b列进行排序
从原理可知,为什么有最佳左前缀法则,就是这个道理
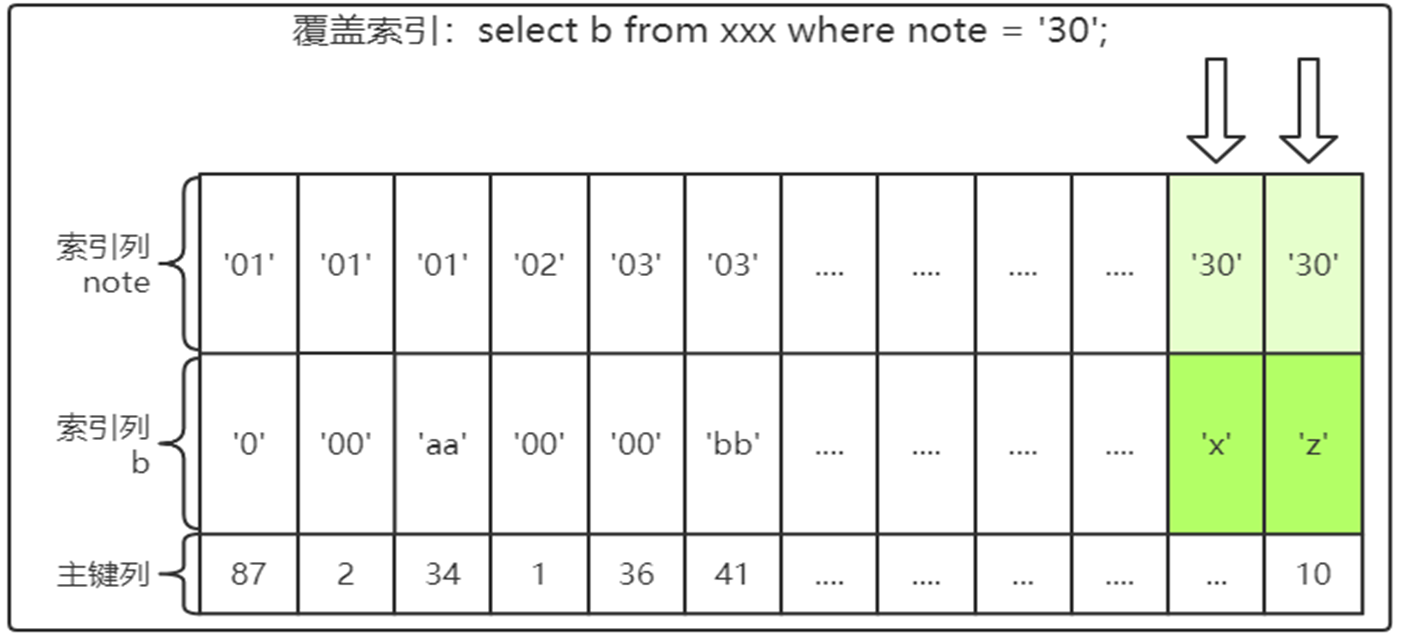
1.2.1.5.覆盖索引
既然多个列可以组合起来构建为联合索引,那么辅助索引自然也可以由多个列组成。
InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集索引中的记录(回表)。使用覆盖索引的一个好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。所以记住,覆盖索引并不是索引类型的一种。
1.2.2.哈希索引
InnoDB存储引擎除了我们前面所说的各种索引,还有一种自适应哈希索引,我们知道B+树的查找次数,取决于B+树的高度,在生产环境中,B+树的高度一般为3、4层,故需要3、4次的IO查询。
所以在InnoDB存储引擎内部自己去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自己创建一个hash索引,称之为自适应哈希索引( Adaptive Hash Index,AHI),创建以后,如果下次又查询到这个索引,那么直接通过hash算法推导出记录的地址,直接一次就能查到数据,比重复去B+tree索引中查询三四次节点的效率高了不少。
InnoDB存储引擎使用的哈希函数采用除法散列方式,其冲突机制采用链表方式。注意,对于自适应哈希索引仅是数据库自身创建并使用的,我们并不能对其进行干预。
show engine innodb status

哈希索引只能用来搜索等值的查询,如 SELECT* FROM table WHERE index co=xxx。而对于其他查找类型,如范围查找,是不能使用哈希索引的,
因此这里出现了non-hash searches/s的情况。通过 hash searches: non- hash searches可以大概了解使用哈希索引后的效率。
innodb_adaptive_hash_index来考虑是禁用或启动此特性,默认AHI为开启状态。
1.2.3.全文索引
什么是全文检索(Full-Text Search)?它是将存储于数据库中的整本书或整篇文章中的任意内容信息查找出来的技术。它可以根据需要获得全文中有关章、节、段、句、词等信息,也可以进行各种统计和分析。我们比较熟知的Elasticsearch、Solr等就是全文检索引擎,底层都是基于Apache Lucene的。
举个例子,现在我们要保存唐宋诗词,数据库中我们们会怎么设计?诗词表我们可能的设计如下:
| 朝代 | 作者 | 诗词年代 | 标题 | 诗词全文 |
|---|---|---|---|---|
| 唐 | 李白 | 静夜思 | 床前明月光,疑是地上霜。 举头望明月,低头思故乡。 | |
| 宋 | 李清照 | 如梦令 | 常记溪亭日暮,沉醉不知归路,兴尽晚回舟,误入藕花深处。争渡,争渡,惊起一滩鸥鹭。 | |
| …. | …. | … | …. | ……. |
要根据朝代或者作者寻找诗,都很简单,比如“select 诗词全文 from 诗词表 where作者=‘李白’”,如果数据很多,查询速度很慢,怎么办?我们可以在对应的查询字段上建立索引加速查询。
但是如果我们现在有个需求:要求找到包含“望”字的诗词怎么办?用
“select 诗词全文 from 诗词表 where诗词全文 like‘%望%’”,这个意味着要扫描库中的诗词全文字段,逐条比对,找出所有包含关键词“望”字的记录,。基本上,数据库中一般的SQL优化手段都是用不上的。数量少,大概性能还能接受,如果数据量稍微大点,就完全无法接受了,更何况在互联网这种海量数据的情况下呢?怎么解决这个问题呢,用倒排索引。
倒排索引就是,将文档中包含的关键字全部提取处理,然后再将关键字和文档之间的对应关系保存起来,最后再对关键字本身做索引排序。用户在检索某一个关键字是,先对关键字的索引进行查找,再通过关键字与文档的对应关系找到所在文档。
于是我们可以这么保存
| 序号 | 关键字 | 蜀道难 | 静夜思 | 春台望 | 鹤冲天 |
|---|---|---|---|---|---|
| 1 | 望 | 有 | 有 | 有 | 有 |
如果查哪个诗词中包含上,怎么办,上述的表格可以继续填入新的记录
| 序号 | 关键字 | 蜀道难 | 静夜思 | 春台望 | 鹤冲天 |
|---|---|---|---|---|---|
| 1 | 望 | 有 | 有 | 有 | 有 |
| 2 | 上 | 有 | 有 |
从InnoDB 1.2.x版本开始,InnoDB存储引擎开始支持全文检索,对应的MySQL版本是5.6.x系列。不过MySQL从设计之初就是关系型数据库,存储引擎虽然支持全文检索,整体架构上对全文检索支持并不好而且限制很多,比如每张表只能有一个全文检索的索引,不支持没有单词界定符( delimiter)的语言,如中文、日语、韩语等。
所以MySQL中的全文索引功能比较弱鸡,了解即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构