
机器学习之线性回归(单一变量)代码实现(python代码实现)
一、本案例主要利用python代码解决“采用实现线性回归(单一变量)来预测一辆食品卡车的利润的问题”,代码中涉及到机器学习中的线性回归理论知识,本文不着重介绍(详细可参考吴恩达的《机器学习》),主要介绍其代码实现过程(源代码参考吴恩达的《机器学习》的课后作业),也可参考我写的matlab代码实现编写的文档。
二、实验结果如图所示:
1)训练集的数据分布图:
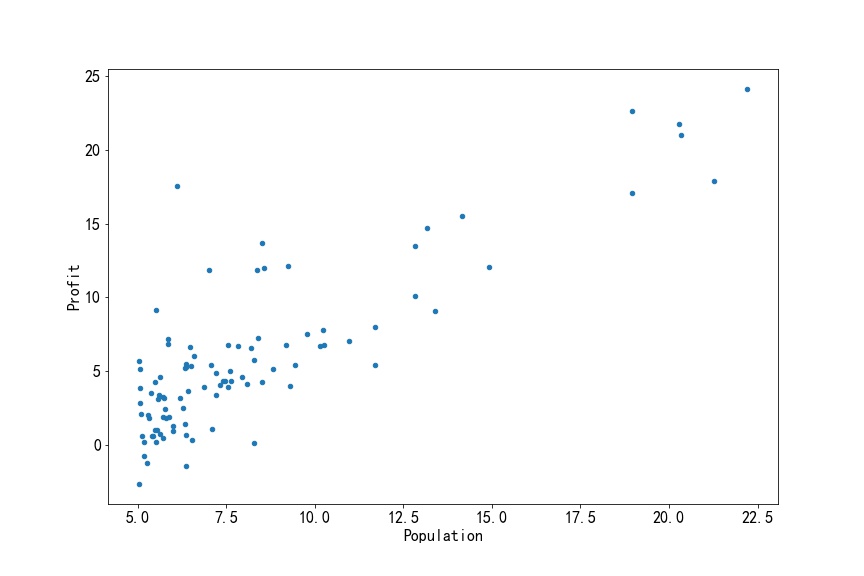
2)线性回归图
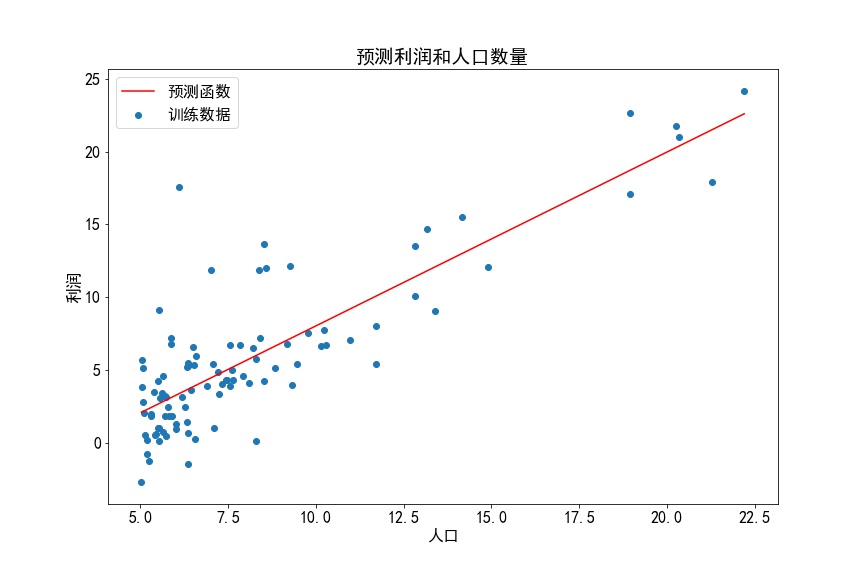
3)批量梯度下降函数计算代价成本值:
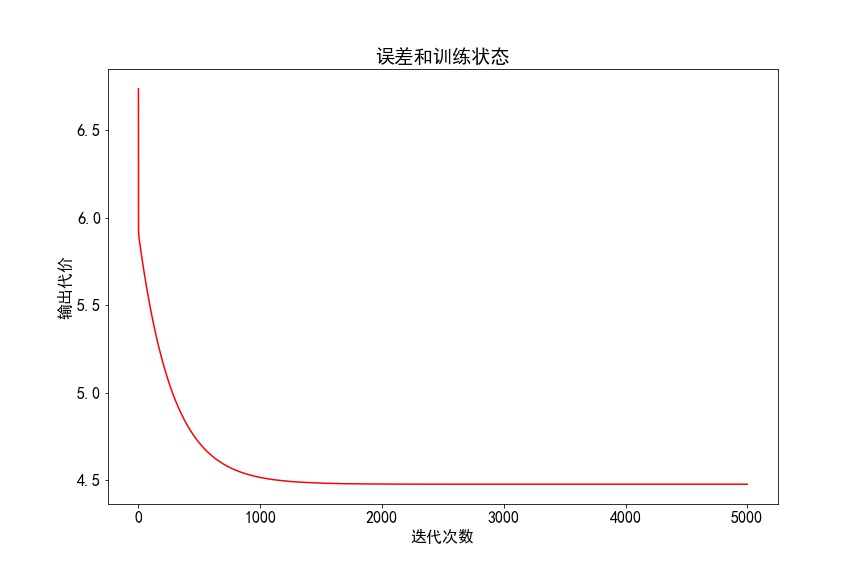
三、实现代码如下:ex1.py


1 # -*- coding: utf-8 -*- 2 """ 3 机器学习之单一变量线性回归 4 """ 5 #导入相关库 6 import pandas as pd 7 import matplotlib.pyplot as plt 8 import numpy as np 9 #设置字体的更多属性 10 font={ 11 'family':'SimHei', 12 'weight':'bold', 13 'size' : '16' 14 } 15 plt.rc('font',**font) 16 #解决坐标轴负轴的符号显示的问题 17 plt.rc('axes',unicode_minus=False) 18 #损耗函数算法代码,theta.T转置,矩阵计算 19 def computeCost(X,y,theta): 20 21 m=len(y) 22 inner = np.power(((X * theta.T) - y), 2) 23 return np.sum(inner) / (2 * m) 24 #批量梯度下降算法 25 # 该函数通过执行梯度下降算法次数来更新theta值,每次迭代次数跟学习率有关 26 # 函数参数说明: 27 # X :代表特征/输入变量 28 # y:代表目标变量/输出变量 29 # theta:线性回归模型的两个系数值(h(x)=theta(1)+theta(2)*x) 30 # alpha:学习率 31 # iters:迭代次数 32 def gradientDescent(X, y, theta, alpha, iters): 33 temp = np.matrix(np.zeros(theta.shape)) 34 parameters = int(theta.ravel().shape[1]) 35 cost = np.zeros(iters) 36 37 for i in range(iters): 38 error = (X * theta.T) - y 39 40 for j in range(parameters): 41 term = np.multiply(error, X[:,j]) 42 temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term)) 43 44 theta = temp 45 cost[i] = computeCost(X, y, theta) 46 47 return theta, cost 48 if __name__ == '__main__': 49 #读取训练数据集中的数据 50 #%文件ex1data1.txt包含了我们的线性回归问题的数据集。 51 #第一列是城市的人口(单位100000),第二列是城市里的一辆食品卡车的利润。 52 #利润的负值表示损失 53 train_data=pd.read_csv('ex1data1.txt',names=['Population','Profit']) 54 55 #将训练集中的数据在图中显示 56 train_data.plot(kind='scatter', x='Population', y='Profit', figsize=(12,8)) 57 plt.show() 58 59 #我们在训练集中添加一列,以便我们可以使用向量化的解决方案来计算代价和梯度。 60 train_data.insert(0,'Ones',1) 61 X=train_data.iloc[:,[0,1]]#X是所有行,去掉最后一列 62 y=train_data.iloc[:,2]#y是所有行,最后一列 63 #代价函数是矩阵计算,所以需要将X,y,theta转变为矩阵 64 X = np.matrix(X.values) 65 y = np.matrix(y.values) 66 y=y.T#转置 67 theta = np.matrix(np.array([0,0])) 68 print(X.shape, theta.shape, y.shape) 69 #初始化一些附加变量 - 学习速率α和要执行的迭代次数。 70 iters = 5000#迭代次数设置为1500次 71 alpha = 0.01#学习率设置为0.01. 72 computeCost(X, y, theta) 73 g, cost = gradientDescent(X, y, theta, alpha, iters)#g是求出的最佳theat值,cost是所有迭代次数的代价函数求出的值 74 print('求出的最佳theat值:',g) 75 #将线性回归函数画出 76 x = np.linspace(train_data.Population.min(), train_data.Population.max(), 100) 77 f = g[0, 0] + (g[0, 1] * x) 78 79 fig, ax = plt.subplots(figsize=(12,8)) 80 ax.plot(x, f, 'r', label='预测函数') 81 ax.scatter(train_data.Population, train_data.Profit, label='训练数据') 82 ax.legend(loc=2) 83 ax.set_xlabel('人口') 84 ax.set_ylabel('利润') 85 ax.set_title('预测利润和人口数量') 86 plt.show() 87 # 预测人口规模为3.5万和7万的利润值 88 predict1 = g[0,0]*1+(g[0, 1] * 3.5) 89 print('当人口为35,000时,我们预测利润为',predict1*10000); 90 predict2 = g[0,0]*1+(g[0, 1] * 7) 91 print('当人口为70,000时,我们预测利润为',predict2*10000); 92 #由于梯度方程式函数也在每个训练迭代中输出一个代价的向量, 93 #所以我们也可以绘制。 请注意,代价总是降低 - 这是凸优化问题的一个例子。 94 fig, ax = plt.subplots(figsize=(12,8)) 95 ax.plot(np.arange(iters), cost, 'r') 96 ax.set_xlabel('迭代次数') 97 ax.set_ylabel('输出代价') 98 ax.set_title('误差和训练状态') 99 plt.show()
一无所有却不甘淡薄,于是拼命的去 猎取最丰盛的收获。
