域名备案&robots协议
这篇文章不谈技术,聊一聊笔者在网站建设一些需要注意的点。
1 域名备案
建设一个网站一定会需要域名,而域名又一定需要备案。备案分为两类,公司备案和个人备案:
个人备案
笔者之前在大二的时候在阿里云购买过一个域名,备案是一个周期较长的事情,希望即将准备备案的小伙伴们做好心理准备。相对于公司备案来说,个人备案更久更烦琐,原因就是域名很容易被不法分子利用,做些不正当的交易用途。
以阿里云备案为例,大部分都是在网上审批,这个只需要等就行了。唯一复杂需要线下进行操作的是:在幕布下拍照,截张图

大概是这么一张纸,上面有阿里云公司名称然后就是,互联网备案信息China,然后会有一个示例规范,拍好照再上传就OK了。幕布寄过来大概得一周,看人家忙不忙了。
然后就是网站功能审批的问题了,关于网站用作何用途等都要详细填写,后期阿里云客服会过来帮助确认修改。
相对于去相关部分备案,这种方式还是方便了不少,个人开发者可以考虑。
公司备案
公司备案比我预想的要简单,上传营业执照然后把相关的法人信息填写就好了。(因为公司注册是非常繁琐的,而且公司信息在工商局注册过,阿里云应该对接的不错,把信息填好了备案就下来了)
备案完成之后
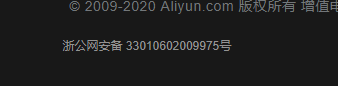
备案完成之后会有一个备案号,这个一定要给网站加上!!一定要加上!!一定要加上!!!重要的事情说三遍
因为有关部分会进行抽检,如果没有加上的话会带来一些不必要的麻烦,仔细看一看,各大主流网站上都有备案信息:

了解更多
2 robots.txt
这个玩意主要是为了规范爬虫,关于爬虫的新闻相信大家最近一段时间都听说了很多信息,公司因为非法爬虫被抓等等。技术是无罪的,但如何使用技术就取决于每个人的自觉性了。法律是一道红线,一旦碰了,就会有意想不到的大礼包等着你。
robots.txt 是一种遵照漫游器排除标准创建的纯文本文件,由一条或多条规则组成。每条规则可禁止(或允许)特定抓取工具抓取相应网站中的指定文件路径。
简单点来说,这个文件告诉我们哪些页面可以爬,哪些页面不能爬,只有遵守了这个规范,合理的爬,人家不在乎的(你要是开几十万个线程把人家服务器搞崩了也是要负责的)
举个例子:这种带有Disallow是不允许爬取的
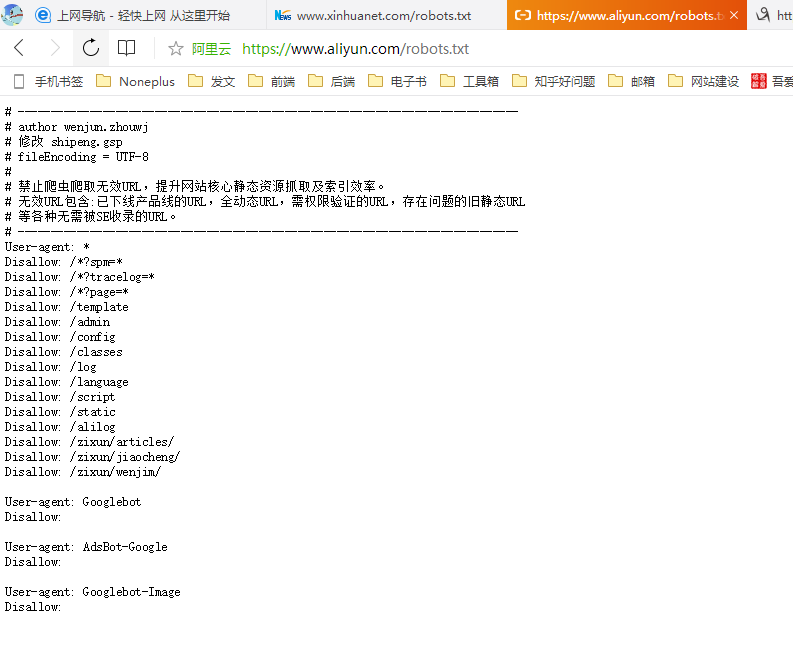
来看看博客园大大的robots协议,这个就随意了:爬虫这个东西是把双刃剑,爬多了对服务器有影响,爬一些权限信息涉及到数据隐私,但是合理的爬一爬可以增加网站流量。
这是一个度的问题,大家把水端平就好。