

动态引用存储——集合&&精确的集合定义——泛型
 Java集合又称容器,可以动态的将对象的引用存储在容器中。(灵活可扩展)
Java集合又称容器,可以动态的将对象的引用存储在容器中。(灵活可扩展)
1,集合宏观理解
1.1,为什么引入集合?
对于面向对象的语言来说,操作对象的功能不可或缺。
为了方便对对象进行操作和处理,就必须要对对象进行暂时的存储。【数据最终存在数据库里】
使用数组来存储对象的最大问题就是数组长度的固定性。(不灵活,难扩展)
Java中的集合,可以动态的将对象的引用存储在容器中。(灵活可扩展)
1.2,为什么数组长度是固定的?为什么集合是动态的?
数组在数据结构中被定义为线性结构,其内存空间是连续的。所以数组在初始化时必须指定长度。
【如果不指定,系统没法分配内存】
而集合,,,
百度了一下:参考一下这篇文章
- ArrayList的底层使用数组结构,当集合需要扩容的时候,将老数组中的元素拷贝到一份新的数组中。
- LinkedList底层使用双向链表,双向链表这种数据结构大致分为三个部分,数据域存储数据的,然后一个pre,一个next分别指向前一个和后一个节点的引用。链表的扩容就比较容易实现了,直接加一个节点就完事了。
....
集合实现动态的方式大致可以分为两种,
其一在数组的基础上做一些处理,
其二采用更加适合动态存储的数据结构,比如说双向链表。
1.3,集合的体系结构
放图,
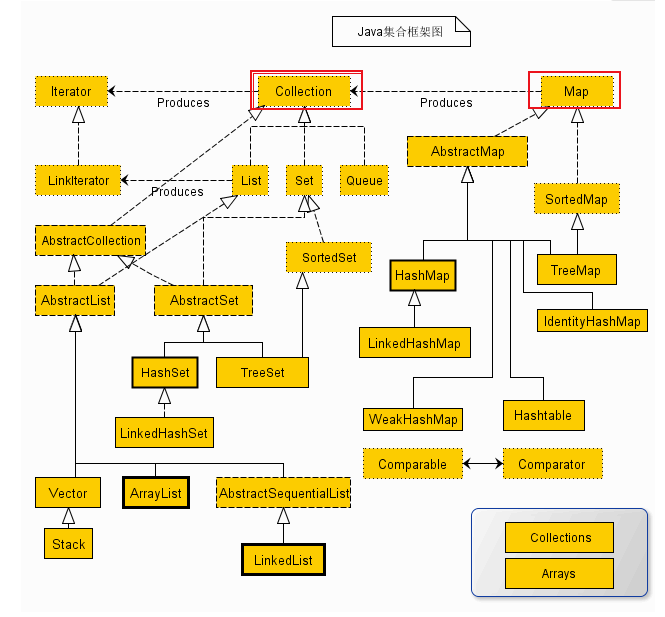
关于Collection和Map
Java集合类主要由Collection和Map派生而出。Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性;Map是一个映射接口,即key-value键值对。
Collection
- List 有序可重复
- ArrayList
- LinkedList
- Vector
- Stack
- Set 无序不重复【集合】
- HashSet
- LinkedSet
- TreeSet
Map
- HashMap
- TreeMap
- HashTable
- ConcurrentHashMap
2,集合API
Collection接口方法
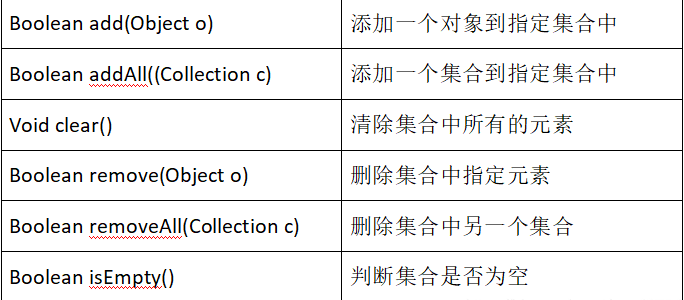
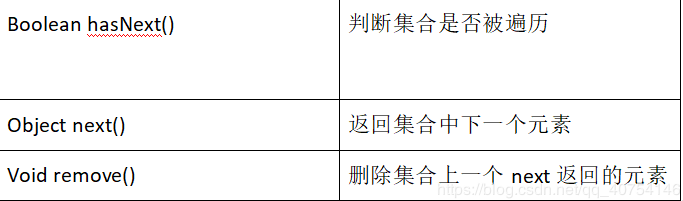
Iterator接口(迭代器:主要用于遍历)
1.ArrayList
import java.util.ArrayList;
import java.util.Iterator;
public class Main
{
public static void main(String []args)
{
ArrayList list = new ArrayList();
list.add("A");//将指定的元素追加到此列表的尾部
list.add(1,"B");//插入列表的指定位置
list.add("C");
list.add("D");
list.add("E");
//for遍历
System.out.println("for遍历");
for(Object element:list)
{
System.out.println(element);
}
System.out.println("------------------");
//用迭代器遍历
//获取迭代器
System.out.println("迭代器遍历");
Iterator iterator = list.iterator();
//如果仍有元素可以迭代,则返回 true。
while(iterator.hasNext())
{
System.out.println(iterator.next());// 返回迭代的下一个元素。
}
System.out.println("------------------");
//删除元素remove
System.out.println("删除前:");
for(Object element:list)
{
System.out.println(element);
}
list.remove(0);
list.remove(2);
System.out.println("------------------");
System.out.println("删除后:");
for(Object element:list)
{
System.out.println(element);
}
}
}
2.LinkedList
import java.util.LinkedList;
import java.util.Iterator;
public class Main
{
public static void main(String []args)
{
LinkedList li= new LinkedList();
li.addFirst("C");
li.addLast("D");
li.addFirst("B");
li.addLast("E");
li.addFirst("A");
li.addLast("F");
System.out.println( "直接输出");
System.out.println(li);
System.out.println("--------------------");
System.out.println( "用for输出");
for(Object str:li)
{System.out.println(str);}
System.out.println("--------------------");
System.out.println( "用迭代器输出");
Iterator iterator= li.iterator();
while(iterator.hasNext())
{System.out.println(iterator.next());}
System.out.println("--------------------");
System.out.println("访问");
System.out.println("peekFirst:"+li.peekFirst());//getFirst,getLast
System.out.println("peekLast:"+li.peekLast());
System.out.println("删除");
System.out.println(li.removeFirst());//pollFirst,pollLast
System.out.println(li.removeLast());
System.out.println("--------------------");
System.out.println("用for输出");
for(Object str:li)
{System.out.println(str);}
System.out.println("--------------------");
}
}
3.HashSet
import java.util.Date;
import java.util.HashSet;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
Date currentDate = new Date();
HashSet hs= new HashSet();
//添加元素
hs.add(currentDate.toString());
hs.add(new String("2"));
hs.add("3");
hs.add("3");//不能包含重复元素,被自动覆盖
System.out.println("for 迭代输出");
for(Object element:hs)
{System.out.println(element); }
System.out.println("Iterator 迭代输出");
Iterator iterator=hs.iterator();
while(iterator.hasNext())
{
System.out.println(iterator.next());
}
//删除元素
hs.remove("2");
hs.remove(currentDate.toString());
System.out.println("删除元素后输出:");
for(Object element:hs)
{
System.out.println(element);
}
}
}
4.TreeSet
//TreeSet默认自动排序
import java.util.TreeSet;
import java.util.Iterator;
public class Main {
public static void main(String args[]) {
TreeSet tr = new TreeSet();
tr.add("B");
tr.add("A");
tr.add("D");
tr.add("E");
System.out.println("直接输出集合对象");
System.out.println(tr);
System.out.println("for遍历输出");
for (Object element : tr) {
System.out.println(element);
}
System.out.println("Iterator迭代输出");
Iterator iterator = tr.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
5.HashMap
import java.util.HashMap;
public class Main
{
public static void main(String []args)
{
HashMap hs = new HashMap<>();
//写入数据
System.out.println("写入数据...");
System.out.println("...");
hs.put(1,"华晨宇");
hs.put(2,"周杰伦");
hs.put(3,"刘若英");
hs.put(4,"许嵩");
//读取数据
System.out.println("读取数据...");
System.out.println("...");
System.out.println(hs.get(1));
System.out.println(hs.get(2));
System.out.println(hs.get(3));
System.out.println(hs.get(4));
//删除数据
System.out.println("...");
System.out.println("删除数据...");
hs.remove(1);
System.out.println(hs.get(1));
}
}
3,集合的原理
ArrayList
-
ArrayList基于数组实现,默认为数组初始化长度为10。
-
ArrayList扩容机制
元素个数超过了10个,ArrayList底层会新生成一个数组,长度为原数组的1.5倍+1,然后将原数组的内容复制到新数组当中,并且后续增加的内容都会放到新数组当中。当新数组无法容纳增加的元素时,重复该过程。
一旦数组超出长度,就开始扩容数组。扩容数组调用的方法 Arrays.copyOf(objArr, objArr.length + 1);
LinkedList
基于双向链表实现
HashMap
-
关于HashMap的存储结构
JDK1.8之前采用数组+链表的方式存储,之后采用数据+链表+红黑树存储。
红黑树的主要目的是使用链地址法处理hash冲突带来的链表过长的问题。
-
关于hash冲突
hash的思想就是通过散列算法(压缩映射)将任意长度的输入,变成固定长度的输出。
散列算法的问题:不同对象通过散列算法计算的hashCode相同。
4,集合相关面试题
1,说说常见的集合有哪些?
Map和Collection接口是所有集合框架的父接口:
- Collection接口的子接口包括:Set接口(无序不重复)和List接口(有序可重复)
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
- Map接口的实现类主要有:HashMap、TreeMap、Hashtable、ConcurrentHashMap
Map中HashMap是线程不安全的,HashTable虽然线程安全,但是锁的粒度比较大。通常使用ConcurrentHashMap代替。
2,ArrayList , LinkedList,Vector的区别
【实现方式】
-
ArrayList和Vector:基于数组实现
-
LinkedList:基于双向链表实现
【线程安全】
- Vector使用synchronized锁保证线程安全,效率较低
- ArrayList和Vector是线程不安全的
【效率问题】
- 基于数组实现的查询效率高,插入删除效率低
- 基于链表实现的插入删除效率高,查询效率低
【扩容问题】
- Vector 在数据满时(加载因子1)增长为原来的两倍(扩容增量:原容量的 2 倍)
- ArrayList 在数据量达到容量的一半时(加载因子 0.5)增长为原容量的 (0.5 倍 + 1) 个空间。
- LinkedList基于双向链表实现,不考虑扩容问题。
Array 和 ArrayList 有什么区别?什么时候该应 Array 而不是 ArrayList 呢?
- Array 可以包含基本类型和对象类型,ArrayList 只能包含对象类型。
- Array 大小是固定的,ArrayList 的大小是动态变化的。
3,HashMap,HashTable和ConcurrentHashMap区别
【线程安全问题】
HashMap是线程不安全的。
HashTable使用Synchronize锁保证线程安全;
ConcurrentHashMap使用分段锁保证线程安全。
【锁的粒度问题】
HashTable使用Synchronize锁保证线程安全,锁粒度过大,效率低。
ConcurrentHashMap使用分段锁保证线程安全,锁粒度较小,效率高
HashMap的扩容操作是怎么实现的?
HashMap是怎么解决哈希冲突的?
Hash本质上是一种压缩映射,散列值占用的空间远远小于输入的空间,但是这种压缩映射会存在一个问题:不同的输入值得到了相同的Hash值。
解决hash冲突的方法:
- 链地址法:
4,HashMap和TreeMap的选择
插入,删除定位选用HashMap,对key集合有序遍历选用TreeMap。
数组和List之间如何转换?
数组转List:Arrays.asList(array);
List转数组:List自带toArray()方法;
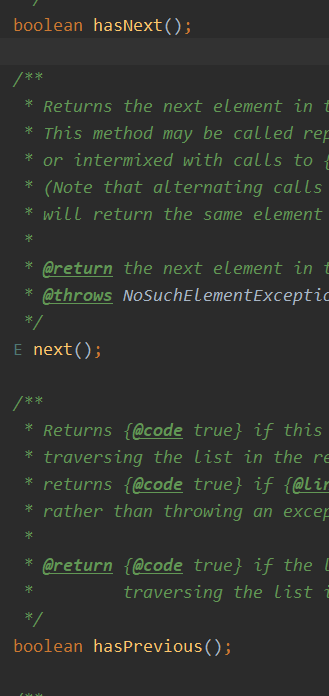
关于迭代器Iterator
Iterator提供遍历任何Collection的接口。其特点是更加安全,在遍历的时候如果集合被修改会抛出ConcurrentModificationException异常。
Iterator和ListIterator的区别?
遍历范围:
- Iterator可以遍历Set和List,ListIterator只能遍历List
遍历方向:
- Iterator只能从前往后遍历,ListIterator可以双向遍历(反转)
5,集合通用性导致的问题
当把一个元素丢进集合后,集合为了更好的通用性,都会编译成Object类。
导致的问题:
- 不同对象保存到同一指定集合的异常
- 取出集合中元素导致的强制类型转换异常
什么是泛型?
参数化类型!!!
什么是参数化类型???
将具体的类型(如String,Integer)抽象成参数。
泛型的作用
- 消除了集合中的强制类型转换,减少异常。
- 指定了对象的限定类型,实现了Java的类型安全。
- 合并代码。提高重用率。
泛型的表现形式
菱形语法:
List<String> list = new List<>();
Map<Integer , String > = new Map<>();
泛型类
//泛型类
public class Main<T>
{
private T data;
public Main(T data)
{
this.data=data;
}
public T getData()
{
return data;
}
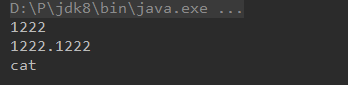
public static void main(String []args)
{
Main<Integer> g1 = new Main<Integer>(1222);
System.out.println(g1.getData());
Main<Double> g2 = new Main<Double>(1222.1222);
System.out.println(g2.getData());
Main<String> g3 = new Main<String>("cat");
System.out.println(g3.getData());
}
}
泛型方法
public class Main
{
public static <E> void printArray(E inputArray[])
{
for(E element:inputArray)
{
System.out.printf("%s",element);
}
}
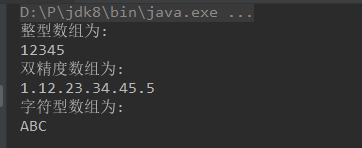
public static void main(String args[])
{
Integer intArray[]= {1,2,3,4,5};
Double doubleArray[]= {1.1,2.2,3.3,4.4,5.5};
Character charArray[]= {'A','B','C'};
System.out.printf("整型数组为:\n");
printArray(intArray);
System.out.printf("\n");
System.out.printf("双精度数组为:\n");
printArray(doubleArray);
System.out.printf("\n");
System.out.printf("字符型数组为:\n");
printArray(charArray);
System.out.printf("\n");
}
}
泛型接口
public interface TestInterface<T> {
public T next();
}
import java.util.Random;
public class Main implements TestInterface<String>
{
String list[]={"L","A","C"};
@Override
public String next()
{
Random rand = new Random();
return list[rand.nextInt(2)];
}
public static void main(String[] args)
{
Main obj = new Main();
System.out.println(obj.next());
}
}


