我想这篇博客内容可能比较散,因为我没有任何思路,可能想到哪里写到哪里,工作中用到什么功能写什么功能。
1. drop_duplicates
drop_duplicates()的作用是删除重复行,首先,有这么一个DataFrame
![在这里插入图片描述]()
df.drop_duplicates()后的结果:
![在这里插入图片描述]()
drop_duplicates()还可以指定要判断的列,比如我们要删除A,B,C重复的行:
df.drop_duplicates(['A','B','C'])
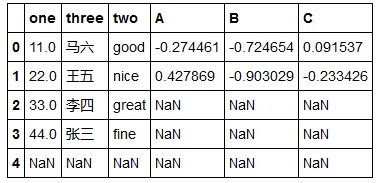
2. fillnan
fillnan可以用指定值填充无效值(NAN)
![在这里插入图片描述]()





 浙公网安备 33010602011771号
浙公网安备 33010602011771号