
MySQL用B+树(而不是B树)做索引的原因
众所周知,MySQL的索引使用了B+树的数据结构。那么为什么不用B树呢?
先看一下B树和B+树的区别。
B树
维基百科对B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。”
B 树可以看作是对2-3查找树的一种扩展,即他允许每个节点有M-1个子节点。
定义
- 根节点至少有两个子节点
- 每个节点有M-1个key,并且以升序排列
- 位于M-1和M key的子节点的值位于M-1 和M key对应的Value之间
- 其它节点至少有M/2个子节点
下图是一个M=4 阶的B树:
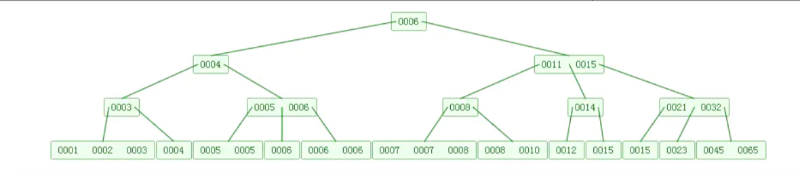
可以看到B树是2-3树的一种扩展,他允许一个节点有多于2个的元素。
B树的插入及平衡化操作和2-3树很相似,这里就不介绍了。
B+树
B+树是对B树的一种变形树,它与B树的差异在于:
- 有k个子结点的结点必然有k个关键码。
- 非叶结点仅具有索引作用,跟记录有关的信息均存放在叶结点中。
- 树的所有叶结点构成一个有序链表,可以按照关键码排序的次序遍历全部记录。
如下图是一个B+树:
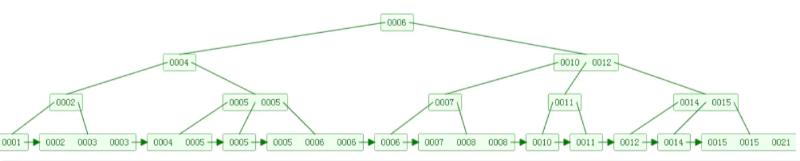
B+树和B树的区别
B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
B+ 树的优点在于:
- IO次数更少:由于B+树在内部节点上不包含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子节点上关联的数据也具有更好的缓存命中率。
- 遍历更加方便:B+树的叶子结点都是相链的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
下面是B 树和B+树的区别图:
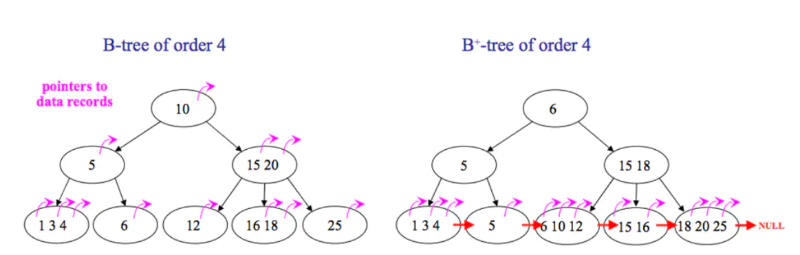
为什么MySQL选择B+树做索引
-
B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
-
B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
-
B+树更便于遍历:由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。
-
B+树更适合基于范围的查询:B树在提高了IO性能的同时并没有解决元素遍历的我效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作或者说效率太低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号