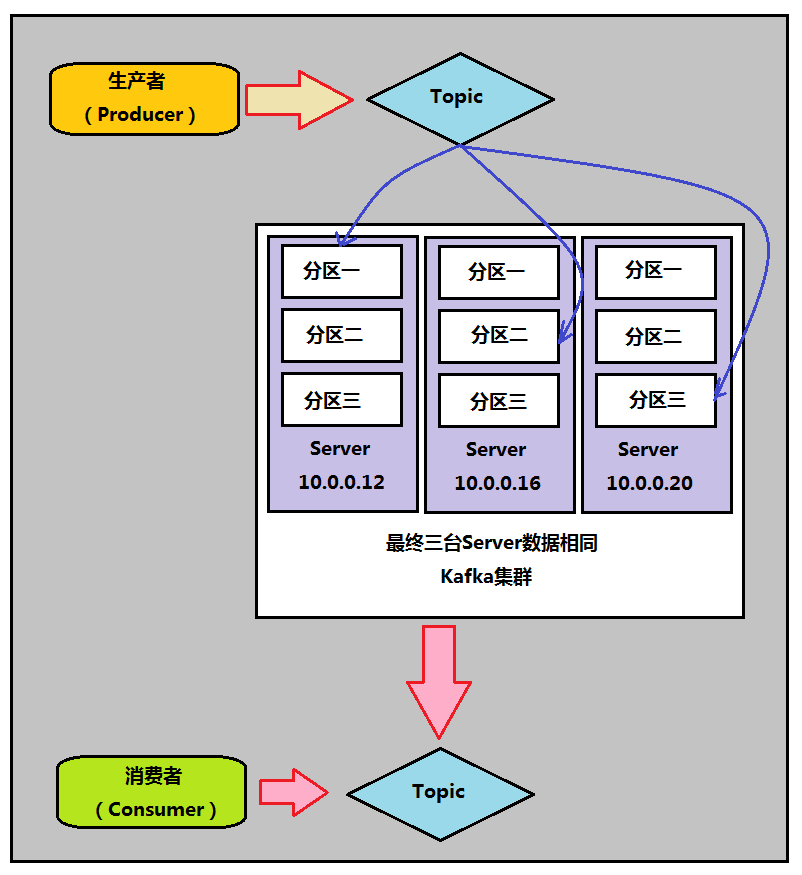
Kafka分区原理图
一个Topic的多个分区,被分布在kafka集群中的多个server上。每个分区都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader 跟进,同步消息即可。由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多 少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定。
具体流程:
1. Producer根据指定的partition方法,将消息发布到指定topic的partition里面
2. kafka集群接收到Producer发过来的消息后,将其持久化到硬盘
3.Consumer从kafka集群pull数据,并控制获取消息的offset
作者:Rick__想太多先森
出处:http://www.cnblogs.com/xtdxs/
注意:本文仅代表个人理解和看法哟!和本人所在公司和团体无任何关系!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号