堆排序的理解
堆是具有下列性质的完全二叉树:
每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;
每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
堆排序的过程:
1.把数组复制一份
2.建堆
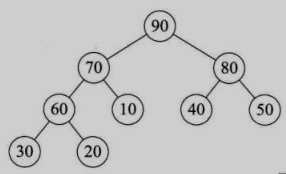
建堆的过程就是从最下层最右边的非终端结点开始,把两个子结点和父结点中最大的值作为父节点,从下往上遍历一遍。最终得到如下图所示的完全二叉树:
建堆的代码如下:
//传入数组及其长度 private void heapbuild(int[] c, int len) { //根据二叉树的性质知道,i为最后一个父节点,从后往前遍历 for(int i=(len/2);i>=0;i--){ //根据二叉树的性质,如果根节点是0,那么父节点的左右子树分别是2*i+1,2*i+2 int left=2*i+1; int right=2*i+2; //假设父节点是最大的值。 int large=i; //求出三个数中最大的,和父节点交换。 if(left<len&&c[left]>c[large]){ swap(c,left,large); } if(right<len&&c[right]>c[large]){ swap(c,right,large); } } }
3.重排
最终数组是要按照从小到大的顺序存储。建立的是大顶堆,所以重排的过程就是把堆顶(最大的数)和数组的末尾交换,然后对前面的数进行重新建堆,然后再把最大的数和末尾的前一个交换,以此类推,最终得到的为从小到大排好序的数组。
代码如下:
for(int i=len;i>0;i--){ //首位交换 swap(b,0,len-1); //建堆的长度减一 len--; //建堆 heapbuild(b,len); }
复杂度分析:
堆排序的效率到底有多高呢?我们来分析一下。
它的运行时间主要是消耗在初始构建堆和在重建堆时的反复筛选上。
在构建堆的过程中,因为我们是完全二叉树从最下层最右边的非终端结点开始构建,将它与其孩子进行比较和若有必要的互换,对于每个非终端结点来说,其实最多进行两次比较和互换操作,因此整个构建堆的时间复杂度为O(n)。
在正式排序时,第i次取堆顶记录重建堆需要用O(logi)的时间,并且需要取n-1次堆顶记录,因此,重建堆的时间复杂度为O(nlogn)。
所以总体来说,堆排序的时间复杂度为O(nlogn)。由于堆排序对原始记录的排序状态并不敏感,因此它无论是最好、最坏和平均时间复杂度均为O(nlogn)。这在性能上显然要远远好过于冒泡、简单选择、直接插入的O(n2)的时间复杂度了。空间复杂度上,它只有一个用来交换的暂存单元,也非常的不错。不过由于记录的比较与交换是跳跃式进行,因此堆排序也是一种不稳定的排序方法。
另外,由于初始构建堆所需的比较次数较多,因此,它并不适合待排序序列个数较少的情况.
