
clickhouse的lib目录下的文件结构整理,以及数据写入和分区合并的概念
记录一下clickhouse存放数据的目录格式,版本是21.7.3.14
1. lib下的数据存储
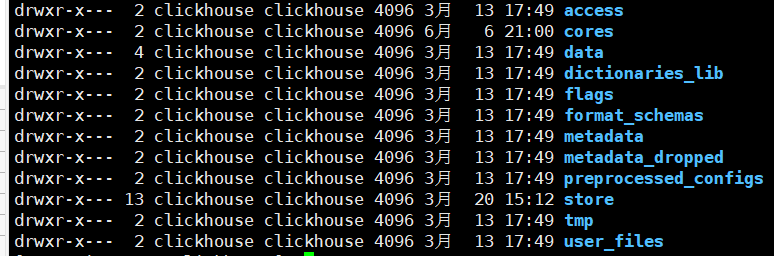
2.主要关注metadata和data这俩个元数据存储和数据储存的目录,这是metadata 下的结构

3.点开default数据库,下面的结构,都是一些元数据的sql文件

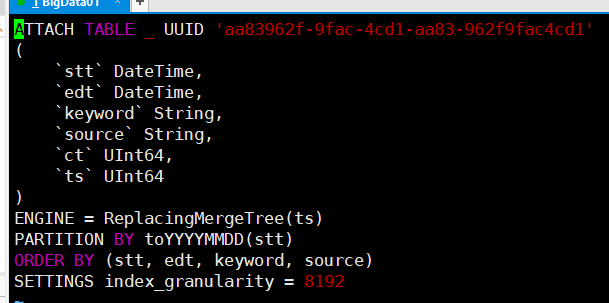
4.以keyword_stats.sql为例子,里面就是 建表语句加一些字段
5. data下的目标结构,因为这里只做了一个分区,所以只有一个20220317_1_6_1,有多个分区的话就会有多个文件

目录中20220317_1_6_1这几个数字的含义:
PartitionId_MinBlockNum_MaxBlockNum_Level
分区值_最小分区块编号_最大分区块编号_合并层级
=》PartitionId
数据分区ID生成规则
数据分区规则由分区ID决定,分区ID由PARTITION BY分区键决定。根据分区键字段类型,ID生成规则可分为:
未定义分区键
没有定义PARTITION BY,默认生成一个目录名为all的数据分区,所有数据均存放在all目录下。
整型分区键
分区键为整型,那么直接用该整型值的字符串形式做为分区ID。
日期类分区键
分区键为日期类型,或者可以转化成日期类型。
其他类型分区键
String、Float类型等,通过128位的Hash算法取其Hash值作为分区ID。
=》MinBlockNum
最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
=》MaxBlockNum
最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号。
=》Level
合并的层级,被合并的次数。合并次数越多,层级值越大。
20220317_1_6_1中的_1_6_1是最小分区块是一号,最大分区块号是六号,合并了一次。
这里看下图例子来更好的理解一下,这里涉及到clickhouse中的数据写入和分区合并概念
数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,不会纳入任何一个已有的分区。写入
后的某个时刻(大概 10-15 分钟后),ClickHouse 会自动执行合并操作(等不及也可以手动
通过 optimize 执行),把临时分区的数据,合并到已有分区中。
初次数据

第二次同样的分区数据写入写入,多了3和4分区块,这里是在临时分区的

手动合并一次,可以看到多了1_3_1和2_4_1,至于合并前原来的分区块会在规定时间后进行清理删除

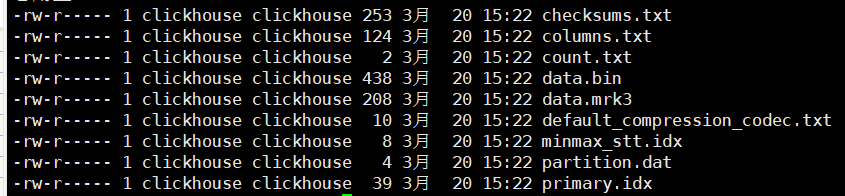
6 分区文件下的目录结构
bin文件:数据文件
mrk文件:标记文件
标记文件在 idx索引文件 和 bin数据文件 之间起到了桥梁作用。
以mrk2结尾的文件,表示该表启用了自适应索引间隔。
primary.idx文件:主键索引文件,用于加快查询效率。
minmax_create_time.idx:分区键的最大最小值。
checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值。
(这里是mergtree引擎,新版的是bin和mrk3只有一个文件,老版本的是表中的每一个列都会有各自的一个bin和mrk2文件)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号