namenode和secondary namenode之间的工作原理 整理,以及datanode 的工作机制和原理
namenode和secondary namenode中涉及到的主要概念就是
1 元数据
2 fsimage (备份元数据)
3 edits (操作日志)
namenode为了快速响应随机访问,所以把元数据放在内存,同时为了防止断电导致元数据丢失,在磁盘上存在一个备份元数据的fsimage。当在内存中的元数据更新时,如果同时更新 FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦 NameNode 节点断电,就会产生数据丢失。因此,引入 Edits 文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到 Edits 中。这样,一旦 NameNode 节点断电,可以通过 FsImage 和 Edits 的合并,合成元数据。而这个合并操作是由secondary namenode 来完成的。
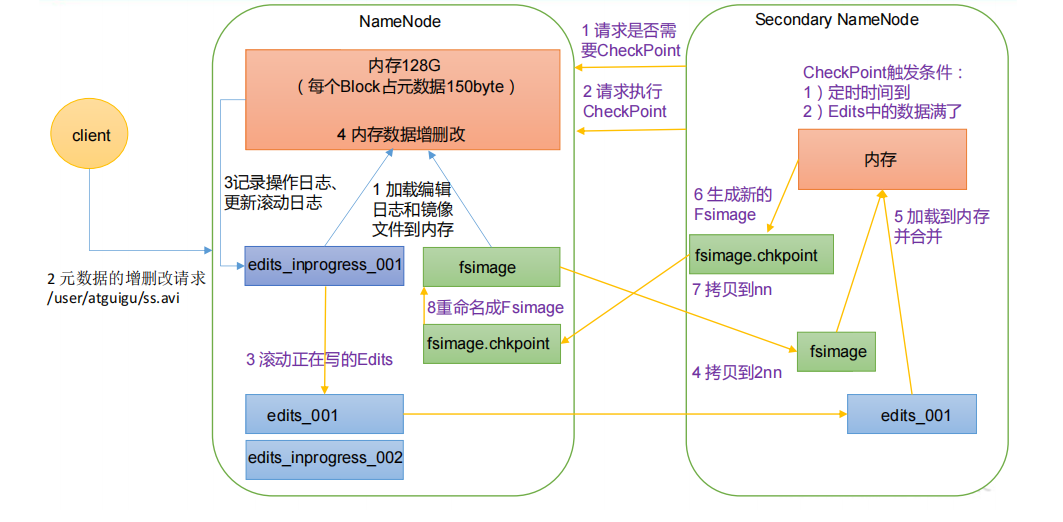
总体来看,namenode 和secondary namenode 的工作流程分成俩个阶段
1)第一阶段:NameNode 启动
- (1)第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启 动,直接加载编辑日志和镜像文件到内存。
- (2)客户端对元数据进行增删改的请求。
- (3)NameNode 记录操作日志(增删改查操作,查不会更新滚动日志),更新滚动日志。(注意namenode 只会更新edits操作日志文件)
- (4)NameNode 在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode 工作 (secondary namenode 会比namenode 节点 一直缺少一个最新的更新操作,也就是edits.new文件中的内容)
- (1)Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode是否检查结果。
(fsimage与edits的合并时机取决于两个参数,第一个参数是默认1小时fsimage与edits合并一次。第二个参数是hdfs操作次数达到1000000 也会触发合并!)这俩个参数是可以自己设置的
- (2)Secondary NameNode 请求执行 CheckPoint。
- (3)NameNode 滚动正在写的 Edits 日志。
(意思就是说 secondary namenode 要求namenode 停止使用旧edis日志文件,如果此时namenode正在进行一个新的更新操作,namenode就把新更新操作放到 edits.new文件中)
(这种操作能有效防止edits文件不停增大)
- (4)将滚动前的旧edits文件和fsimage文件拷贝到 Secondary NameNode。
- (5)Secondary NameNode 加载旧edits文件和fsimage文件到内存,并合并。
- (6)生成新的镜像文件 fsimage.chkpoint。
- (7)拷贝 fsimage.chkpoint 到 NameNode。
- (8)NameNode 将 fsimage.chkpoint 重新命名成 fsimage。将edits.new 重新命名为edits

 浙公网安备 33010602011771号
浙公网安备 33010602011771号