
本单元作业给我的体验还是很糟糕的,由于不注意算法时间复杂度问题,导致在作业过程中出现了多次重构,尤其是第三次作业。之前的作业涉及到时间复杂度问题还是上一单元的防轮询限制,于是我本单元在写的时候反而忽视了这一点,以为只要是正常的算法,数据结构跑正常的用例就不会超时,事实并不是这样,不幸的是我知道的晚了一些。等到讨论课听到台上大佬专门讲复杂度的时候才意识到这一点。具体出现问题的原因有很多,放在下文BUG分析部分再仔细说明。
整体三次作业做下来,除了疯狂重构避免超时的体验极差以外,对JML,Junit的逐渐掌握应该算是本单元收获最大的一点。从最一开始的逐句翻译JML规格写程序,到后来的读懂规格的含义并从中走出更加高效的道路;从只会读规格写程序,到学会读代码写规格,或是读描述写规格(尽管可能写不太好);从println测试程序到使用Junit测试单元,这些都算是“肉眼可见”的收获。
下面就结合几次作业以及本次博客的要求来逐步进行分析。
• (1)梳理JML语言的理论基础、应用工具链情况
JML是一种行为接口规格语言(Behavior Interface Specification Language,BISL),基于Larch方法构建。关于JML的基础知识如果一一列举难免有粘百科或者使用文档之嫌。这里只梳理用到过的,或者说比较重要的。
\result表达式:表示一个非void 类型的方法执行所获得的结果,即方法执行后的返回值。
\old( expr )表达式:用来表示一个表达式expr 在相应方法执行前的取值。
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式:存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\typeof(expr)表达式:该表达式返回expr对应的准确类型。
推理操作符: b_expr1==>b_expr2 或者b_expr2<==b_expr1 ;\nothing指示一个空集;\everything指示一个全集。
前置条件通过requires子句来表示: requires P; 。其中requires是JML关键词,表达的意思是“要求调用者确保P为真”。
后置条件通过ensures子句来表示: ensures P; 。其中ensures是JML关键词,表达的意思是“方法实现者确保方法执行返回结果一定满足谓词P的要求,即确保P为真”
JML还提供了副作用约束子句,使用关键词assignable 或者modifiable 。
signals子句的结构为signals (***Exception e) b_expr ,意思是当b_expr 为true 时,方法会抛出括号中给出的相应异常e
应用工具链如下:可以通过开源的JML编译器,比如OpenJml,编译含有JML标记的代码。Openjml中包含z3等SMT Solver,可以对代码等价性进行验证。测试过程中用到的工具有Junit,可以对可以生成一个Java类文件测试的框架,实现对代码的自动化测试。我在本单元的作业中主要用到的就是这三种。
• (2)部署SMT Solver,至少选择3个主要方法来尝试进行验证,报告结果
在之前使用SMT Solver的时候出现了一些问题,smt 在静态检测变量名时对变量类型十分敏感,导致无法验证代码逻辑等价性,暂时不太清楚是为什么。
• (3)部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例, 并结合规格对生成的测试用例和数据进行简要分析
JMLunit测试代码在大佬提供的基础上进行了修改和完善,部分测试代码如下:
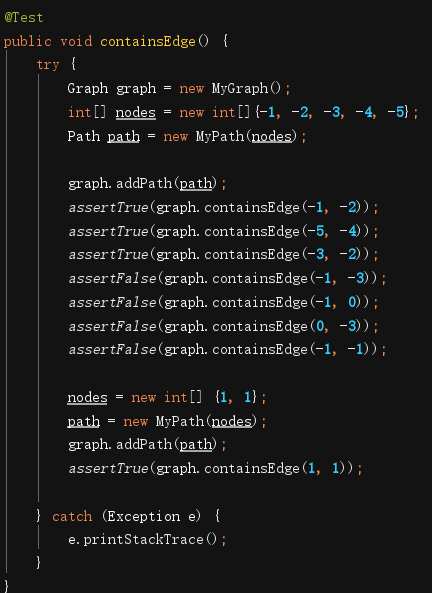
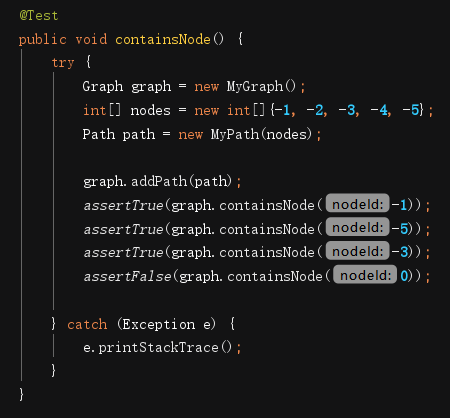
经测试功能未发现错误。
• (4)按照作业梳理自己的架构设计,并特别分析迭代中对架构的重构
一提到重构,感到身体里肝脏的部位在隐隐作痛,从第一单元到现在,没有一次是三次作业迭代下来不需要做重构的(LZZSCL)。上个单元还能够笑着写出总结“重构使我学到了东西",这个单元我连品重构过程的闲情逸致都没有。话虽这么说,但是这一单元的迭代还是蛮曲折的,不可不分析。在此感谢Yzx大佬在我重构过程中给予的帮助,让我不至于险些玩出事。
第一次作业刚刚接触到规格的时候,我对整体的概念把握还不是很清楚。基本上处于一个你有几个规格,我写几个方法,方法之间完全自闭,基本不交流的那种,甚至一开始我连数据结构都是照搬的什么int[] nodes。不过好在动手比较早,改还算来得及,再加上第一次作业实现起来本身代码量就少,不至于出什么大问题,不过方法之间自闭的垃圾构架还是留了下来。
第二次作业无可避免的仍在这样的构架上继续写,当时我还没对第一次作业进行改错,有CPU超时的情况也直接忽略了。实际上超时的原因在下一部分我会讲。在第二次编码中我的目光仍然十分局限,以为选对了数据结构,挨个复现规格就没啥问题,然后等于是仍然带着超时的错误,把重构的需求扔给了第三次作业。甚至连最短路径都没用dij或floyd这样的传统算法,而是写了个深搜。因为不交互,所以isconnected也没法共享最短路径的返回结果,现在想来真的是蠢。(这里没法结合代码说明,因为第三次重构后为了改错我一气之下把第二次的删了,git上也直接覆盖了)
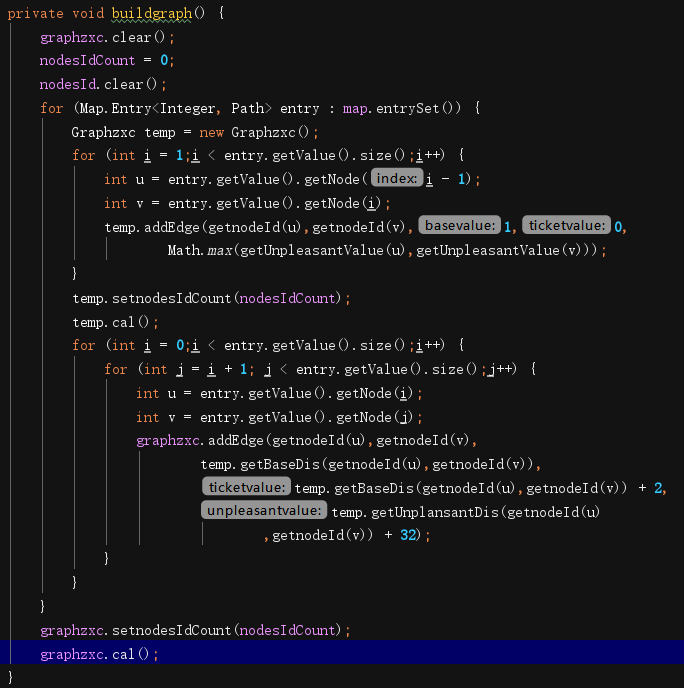
第三次作业就热闹了。刚开始的时候我还是没意识到究竟应该不应该重构还是怎么重构,看讨论区提到了分支限界法,我之前写过深搜的分支限界,于是十分兴奋地在周六就把dfs的分支限界写出来了,最小票价和满意度都是用的这一套东西,然后问yzx大佬要了个测试用例,一跑炸了(不可能不炸系列)。然后周日就被迫翻讨论区开始构思什么所谓的拆点不拆点的各大佬给出的方案(当时真的是一脸懵逼不知道都在说什么)。后来周一上午终于写出来一版,然后传上去发现中测都过不了。再次绝望的再向大佬求助建图思路,从下午干到深夜,最后采用的是wjy大佬最高赞的那个建图方法:
计算最低票价时,对每条Path, 任意两个直接连边,边权x+2y,即在边权中直接加入换乘的钱,然后跑dij。这样做求出的结果多最后一次换乘2y的代价,减去即可。
说实话,最后深夜中测全对的那一刻,我都不知道为什么这样的建图能保证正确性(不会理论证明),算下来为了重构我在电脑前可能坐了整两天……我不确定最后一次难度是否有些过于高了,并且对卡CPU时间这件事也多有怨言。不过经历了这一番重构,我对迭代开发最初版本构架的重要性算是有了清楚的认识,只能说可喜可贺,从这个漩涡中活着飘了出来。最后附上最终版本正确且不超时的建图代码,也算是本单元修成了正果……
• (5)按照作业分析代码实现的bug和修复情况
代码实现上的BUG只有一处,发生在MyPath.getDistinctNodeCount()方法(由于太蠢了就不贴源码了)。第一次作业写出来自己感觉难度也比较简单,中测过了以后自己稍作了一些测试就没再管了,然后结果出来了上述方法出现了错误。条件语句逻辑错了,导致把重复的点也算了进来,而不是distinctnode,属于规格读懂了但是写的过于马虎,写完了测试不利导致的。
有关卡代码时间复杂度的错误请允许我发个牢骚 - -|| :由于本地无法复现评测机上的评测环境,所以究竟怎样的测试用例能抛出怎样的CPU时间是个不太好界定的问题,只能停留在时间复杂度尽可能优和大概不会超时的范畴(我不知道是不是我太弱了,无法对这件事控制的非常清楚)。然后在作业三的讨论区中,有大佬提出了这个问题,但是“为时已晚”,前两次作业已经吃了瘪。
当然原因是多面的,不能复现评测机CPU时间只是一部分。在最后一次重构完全部代码并顺便改完上次的错后,我思考了前面出现两次超时的具体原因,没能领会指导书意图也算是一个主要的问题,这里我用第二次的指导书举例:
总上限为7000条
其中,下述指令被称为线性指令,总数不超过500条
PATH_ADD
PATH_REMOVE
PATH_REMOVE_BY_ID
PATH_GET_ID
PATH_GET_BY_ID
CONTAINS_PATH
COMPARE_PATHS
下述指令被称为图结构变更指令,总数不超过20条
PATH_ADD
PATH_REMOVE
PATH_REMOVE_BY_ID
后来我读到过同学的代码结构,主要的时间复杂度的部分全部集中于PATH_ADD、PATH_REMOVE、PATH_REMOVE_BY_ID的实现逻辑中,而所谓的最短路径维护的矩阵是随着图结构变更指令变化的。所以由于图结构变更指令比例较小,时间复杂度也不会占用太多。
然而我在读指导书的时候却忽视了这一隐藏信息,将比较占时间的算法扔到了类似于isConnected,shortestpath中,因而无可避免的超时。对规格以及规格实现理解的过于死板也算是一个原因,总觉得一个规格对应一个方法,一个方法就干这个规格规定的全部事,addpath就老老实实的添加路径,不用更新最短路径矩阵等等。后来第三次作业经历了比较痛苦的重构后,终于能在有效时间内干劲利落的解决,也算是为理解上的问题买了单。
• (6)阐述对规格撰写和理解上的心得体会
写到这里才发现对规格的理解和撰写心得实在是一个不好形容的话题,因为规格是一个很值得研究的领域,就好比我们课上举得一些软件工程领域的例子和行业大佬的研究一样,水很深,而三次作业能带给我的只是入门级的启发。泛泛谈一下的话主要有以下几点:
(1)规格理解,编写代码的过程是一个构造的过程,类似于从建筑图纸中汲取必要的设计元素,复现建筑。这个过程要求灵活复现,该有的要有,该控制住的必须控制住,但规格以外的东西,如果有助于整体结构的搭建,还是要实现的。几次作业我经历了“你给我几个规格,我实现几个方法”到“你给我几个规格,为了辅助计算我添加几个private方法帮忙”再到“除了你的方法名和你的规格严格要求之外,其他的类似数据结构和算法,怎么高效怎么来”的编码过程,强测的分数也越来越好。这说明了规格是死的也是灵活的,复现规格不能“死”到底,也不能“灵活”越界。
(2)规格撰写则是反向的一个过程,代码不是唯一的写法,但规格必须精简准确的抓住关键点所在。就拿我课上课下并不丰富的撰写规格经历来讲,撰写者并不需要关心代码的数据结构究竟用了什么,而是关心数据形式,在撰写的时候抓住数据流和逻辑流的变化,然后用准确简练的JML语法书写出来,就差不太多(当然我只是针对简单的撰写,复杂的方法或者类的规格撰写我也没法保证能做对)。 归根结底还是要多写多想,写完代码想规格,遇事不决写一套,对规格撰写的理解会越来越深,写的也会越来越准确。
Finally, constant efforts make success. 身为重修生,也算有惊无险的经过了三个单元的磨练,已经做的比之前好了太多。静下心来仔细思考的话,收获的感悟要远比流言蜚语,自怨自艾要来的真实。愿最后一个单元也能顺顺利利,带满收获成功的渡到彼岸。
