

使用jsoup来实现一个简单的java爬虫
事件起源
昨天摸了一天的鱼,下午快下班的时候,突然来活了,说要爬取钓友之家的钓场数据!什么?爬虫?之前一直没写过啊啊!为了保住自己的饭碗,赶紧打开百度,开始了自己第一个爬虫程序之旅!
概念
什么是爬虫?
答:简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
了解了爬虫的概念之后,我随便翻了几篇博客,发现大部分的人都是用jsoup来实现爬虫的。简单的瞄了一下代码,发现jsoup使用起来还蛮简单,于是我就决定使用jsoup来编写我的第一个爬虫程序!
实战演练
1.需求分析
我接到的任务需求是这样的,爬取钓鱼之家上常州每个钓场的名称、区域、是否收费、收费规则以及描述等数据。这里我了博客写起来方便,我简化一下需求,查询常州所有钓场的数据。
我们打开钓友之家网站,点击钓场,进入如下页面:

随便找个城市点击进去,这里我们按照需求,选择常州,进去之后,我们进入钓场列表页面:

发现我们需要的钓场名称、收费方式以及描述等数据都能在列表页找到!但是钓场所在区域却没办法直接获取,我们点击进入详情
发现依然没有区域,这可怎么办?
接着,我突然灵机一动,又回到列表页:
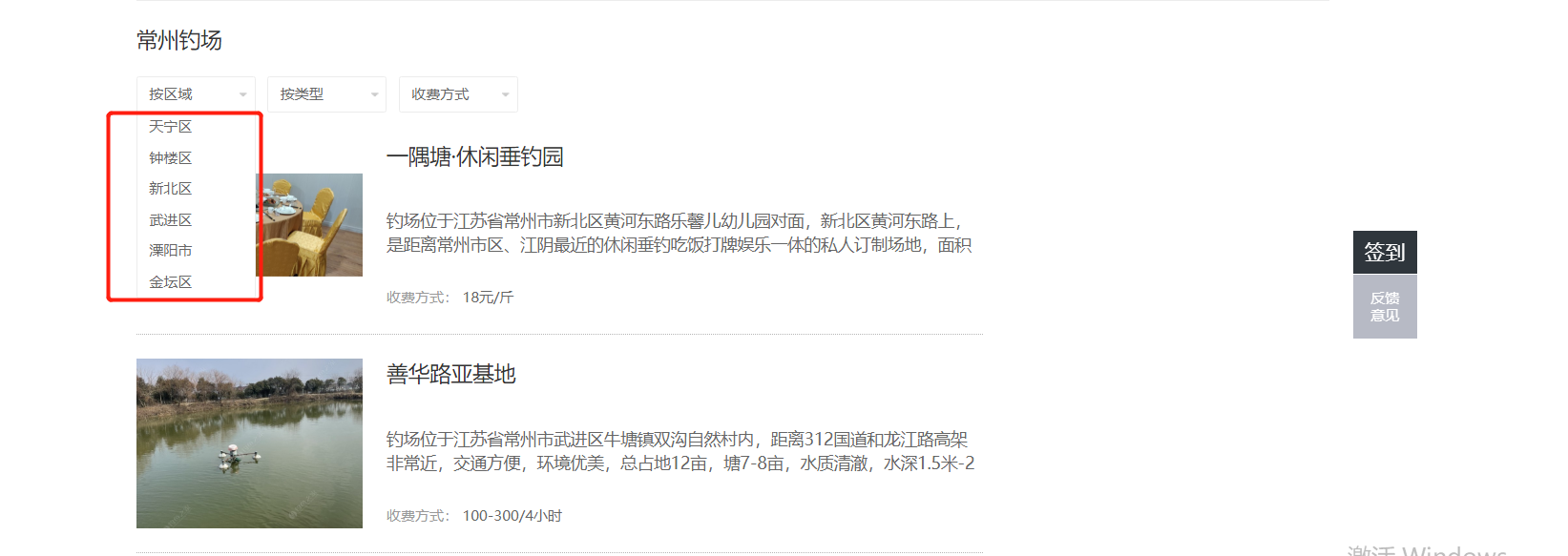
列表页有按照区域查询的筛选条件,我们可以先获取所有的区域,再按照每个区域查询出钓场列表,那么每次查询出来的列表都属于我们该次查询时指定的区域!不得不佩服自己的机智!
2.编码
1.新建一个SpringBoot项目,导入相关jsoup依赖
我想SpringBoot大家应该都很熟悉了,怎么新建项目在这里我就不多说了。
项目新建完成之,我们引入jsoup相关依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
2.获取列表页区域信息
在编写代码之前,jsoup中有几个方法需要介绍一下:
Document document = Jsoup.connect(url).get();通过该方法可以获取我们的整个页面,我们页面中的所有元素都包含在这个对象里。Element对象,就是我们html页面上的DOM节点Elements列表,DOM节点的集合。Document,Element,Elements对象中的方法都与javascript中的DOM节点方法一样。
我们进入列表页面,F12打开调试,选择Elements分析页面数据:
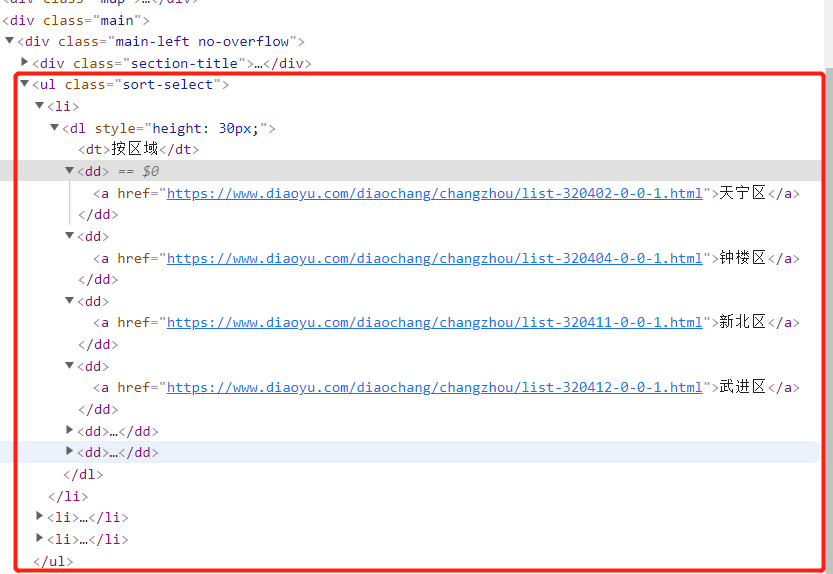
从中,我们发现我们可以使用 标签的class与标签种类来定位到我们的区域。
@Test
void contextLoads() throws Exception {
//这个就是博客中的java反射的url
String url= "https://www.diaoyu.com/diaochang/changzhou/";
Document document = Jsoup.connect(url).get();
// select表示使用css选择器
// .sort-select li 是一个关系选择器,表示选择class是sort-select的所有li子元素
Elements elements = document.select(".sort-select li");
System.out.println(elements);
}
运行测试:

我们发现,按照document.select(".sort-select li")选择器筛选出来的条件有三个,对应列表页面的三个查询条件,想要获得区域信息,我们只要拿第一个就可以了。
以下是我们最终代码:
新建一个pojo类,来存放区域信息:
package com.xdw.pojo;
import lombok.Data;
import java.io.Serializable;
@Data
public class Area implements Serializable {
// 城市名称
private String cityName;
// 省
private String province;
// 区域名称
private String areaName;
// 区域对应链接
private String href;
}
编写获取区域代码:
package com.xdw.utils;
import com.xdw.pojo.Area;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.util.CollectionUtils;
import java.util.ArrayList;
import java.util.List;
@SuppressWarnings("all")
public class JsoupUtils {
public static List<Area> getAreaList(Document document, String cityName, String provinceName) {
List<Area> areaList = new ArrayList<>();
// select表示使用css选择器
// .sort-select li 是一个关系选择器,表示选择class是sort-select的所有li子元素
// first()表示选择第一个li,即我们的区域信息
Element areaElement = document.select(".sort-select li").first();
// 选择li标签下的dd标签,我们需要的区域名称以及对应的检索链接都在这个DOM节点下
Elements ddList = areaElement.select("dd");
if(!CollectionUtils.isEmpty(ddList)) {
for (Element d : ddList) {
Area area = new Area();
area.setAreaName(d.text());
// 链接位于dd标签下的a标签中
area.setHref(d.select("a").attr("abs:href"));
area.setCityName(cityName);
area.setProvince(provinceName);
areaList.add(area);
}
}
return areaList;
}
}
编写测试代码:
@Test
void contextLoads() throws Exception {
//这个就是博客中的java反射的url
String url= "https://www.diaoyu.com/diaochang/changzhou/";
Document document = Jsoup.connect(url).get();
List<Area> areaList = JsoupUtils.getAreaList(document, "常州市", "江苏省");
for (Area area : areaList) {
System.out.println(area);
}
}
运行测试:

区域列表获取成功。
3.从列表数据中获取钓场信息
进入钓场列表页面,f12进入浏览器调试页面:
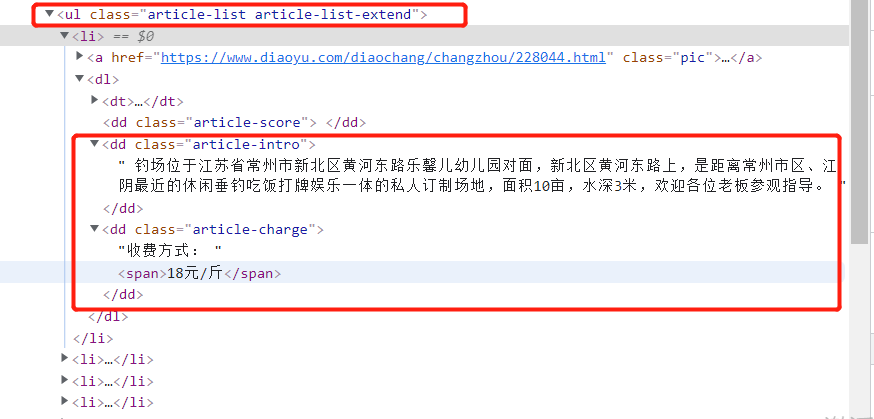
下面开始编写我们的代码:
新建一个钓场类:
package com.xdw.pojo;
import cn.afterturn.easypoi.excel.annotation.Excel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Fishery {
// 钓场名称
private String name;
// 区域名称
private String areaName;
// 城市名称
private String cityName;
// 省名称
private String province;
// 收费方式
private String priceType;
// 价格
private String price;
// 钓场描述
private String descript;
}
在JsoupUtils中新增如下方法,用来获取钓场信息:
public static List<Fishery> getFisheryListByArea(Area area) {
List<Fishery> fisheryList = new ArrayList<>();
String url = area.getHref();
try {
//先获得的是整个页面的html标签页面
Document doc = Jsoup.connect(url).get();
// 交集选择器,选出钓场元素所在DOM
Elements elements = doc.select("ul.article-list").select("li");
if(!CollectionUtils.isEmpty(elements)) {
for (Element element : elements) {
Fishery fishery = new Fishery();
// 设置钓场区域名称
fishery.setAreaName(area.getAreaName());
fishery.setCityName(area.getCityName());
fishery.setProvince(area.getProvince());
// 获取钓场名称
String name = element.select("dl dt a").text();
fishery.setName(name);
// 设置钓场描述
fishery.setDescript(element.select("dl dd.article-intro").text());
// 获取收费类型
Elements priceElement = element.select("dl dd.article-charge");
if(CollectionUtils.isEmpty(priceElement)) {
fishery.setPriceType("免费");
} else {
fishery.setPriceType("收费");
String price = priceElement.select("span").text();
fishery.setPrice(price);
}
fisheryList.add(fishery);
}
}
} catch (Exception e) {
e.printStackTrace();
}
return fisheryList;
}
编写测试类:
@Test
void contextLoads() throws Exception {
//这个就是博客中的java反射的url
String url= "https://www.diaoyu.com/diaochang/changzhou/";
Document document = Jsoup.connect(url).get();
List<Area> areaList = JsoupUtils.getAreaList(document, "常州市", "江苏省");
List<Fishery> fisheryList = new ArrayList<>();
if(!CollectionUtils.isEmpty(areaList)) {
for (Area area : areaList) {
fisheryList.addAll(JsoupUtils.getFisheryListByArea(area));
}
}
for (Fishery fishery : fisheryList) {
System.out.println(fishery);
}
}
运行测试:
我们发现成功获取了钓场数据。
3.代码完善,获取分页数据
问题:刚刚我们只是获得每个区域的第一页数据,我们如何获取后面页的数据呢?


我们发现,当列表页到了尾页时,下一页按钮就会消失,所以我们可以在获取钓场数据方法中添加一个循环,直到没有下一页,才跳出循环!
完善我们的getFisheryListByArea方法如下:
public static List<Fishery> getFisheryListByArea(Area area) {
List<Fishery> fisheryList = new ArrayList<>();
String url = area.getHref();
try {
boolean flag = true;
while(flag) {
//先获得的是整个页面的html标签页面
Document doc = Jsoup.connect(url).get();
// 交集选择器,选出钓场元素所在DOM
Elements elements = doc.select("ul.article-list").select("li");
if(!CollectionUtils.isEmpty(elements)) {
for (Element element : elements) {
Fishery fishery = new Fishery();
// 设置钓场区域名称
fishery.setAreaName(area.getAreaName());
fishery.setCityName(area.getCityName());
fishery.setProvince(area.getProvince());
// 获取钓场名称
String name = element.select("dl dt a").text();
fishery.setName(name);
// 设置钓场描述
fishery.setDescript(element.select("dl dd.article-intro").text());
// 获取收费类型
Elements priceElement = element.select("dl dd.article-charge");
if(CollectionUtils.isEmpty(priceElement)) {
fishery.setPriceType("免费");
} else {
fishery.setPriceType("收费");
String price = priceElement.select("span").text();
fishery.setPrice(price);
}
fisheryList.add(fishery);
}
}
// 获取页面信息
Elements pageElements = doc.select(".page a");
// 没有页面,说明只有一页
if(CollectionUtils.isEmpty(pageElements)) {
flag = false;
} else if(!pageElements.text().contains("下一页")) {
// 没有下一页,直接跳出循环
flag = false;
} else {
for (Element pe : pageElements) {
if(pe.text().equals("下一页")) {
// 存在下一页,获取页面信息
url = pe.attr("abs:href");
}
}
}
if(!flag) {
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
return fisheryList;
}
至此,我们的爬虫大功告成!
我擦了擦额头的汗水,庆幸保住了的饭碗!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· C#/.NET/.NET Core技术前沿周刊 | 第 29 期(2025年3.1-3.9)
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异