

Hibernate基础入门2
HQL与Criteria
HQL(Hibernate Query Language)-官方推荐面向对象的查询语言,与SQL不同,HQL中的对象名是区分大小写的(除了JAVA类和属性其他部分不区分大小写);HQL中查的是对象而不是表,并且支持多态;HQL主要通过Query来操作,Query的创建方式:
Query q = session.createQuery(hql); from Person from User user where user.name=:name from User user where user.name=:name and user.birthday < :birthday
Criteria是一种比HQL更面向对象的查询方式;Criteria的创建方式:
Criteria crit = session.createCriteria(DomainClass.class); //简单属性条件如: criteria.add(Restrictions.eq(propertyName, value)), criteria.add(Restrictions.eqProperty(propertyName,otherPropertyName))
uniqueResult方法:当session.createQuery(“from xxx where cardid=‘xxx’”).uniqueResult();返回的结果只有一个对象时,可以使用uniqueResult()得到该对象。但是,如果结果是多条,使用该方法就会抛出异常。
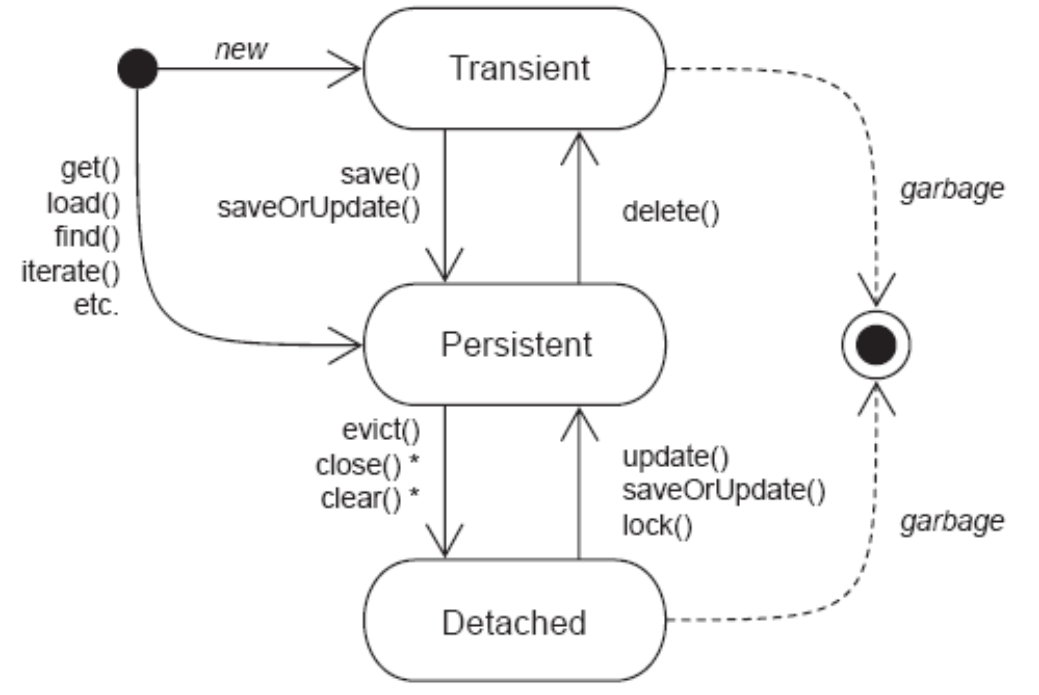
对象状态
- 瞬时(transient):数据库中没有数据与之对应,超过作用域会被JVM垃圾回收器回收,一般是new出来且与session没有关联的对象。
- 持久(persistent):数据库中有数据与之对应,当前与session有关联,并且相关联的session没有关闭,事务没有提交;持久对象状态发生改变,在事务提交时会影响到数据库(hibernate能检测到)。
- 脱管/游离(detached):数据库中有数据与之对应,但当前没有session与之关联;脱管对象状态发生改变,hibernate不能检测到。
对象关系映射
多对一(Employee - Department)
<!--Employee映射文件 --> <many-to-one name=”depart” column=”depart_id”/>
一对多(Department-Employee)
<!--Department映射文件--> <set name=”集合对象属性名”> <key column=”外键名”/> <one-to-many class=”集合放入的类名”/> </set>
一对一(Person - IdCard)
<!--IdCard的映射文件--> <id name=”id”> <generator class=”foreign”><param name=”property”>person</param></generator> <id> <one-to-one name=” person” constrained=”true”/> <!--Person映射文件--> <one-to-one name=“idCard” />
多对多(teacher - student)
在操作和性能方面都不太理想,所以多对多的映射使用较少,实际使用中最好转换成一对多的对象模型;Hibernate会为我们创建中间关联表,转换成两个一对多。
cascade(Employee – Department)
Casade用来说明当对主对象进行某种操作时是否对其关联的从对象也作类似的操作,常用的cascade:none,all,save-update ,delete, lock,refresh,evict,replicate,persist,merge,delete-orphan(one-to-many) 。一般对many-to-one,many-to-many不设置级联,在<one-to-one>和<one-to-many>中设置级联。
- 在集合属性和普通属性中都能使用cascade
- 一般讲cascade配置在one-to-many(one的一方,比如Employee-Department),和one-to-one(主对象一方)
缓存与加强
懒加载的概念
懒加载(Load On Demand)是一种独特而又强大的数据获取方法 ,是指程序推迟访问数据库,这样做可以保证有时候不必要的访问数据库,因为访问一次数据库是比较耗时的。
解决懒加载几种情况(方式)
- 首先我们要明确一点 Domain Object 是非final的,才能实现懒加载。解决懒加载的方法:明确初始化在session还没有关闭时,访问一次 xxx.getXxx(),强制访问数据库。
- Hibernate.initialize(xxx)
- openSessionView 这个往往需要过滤器配合使用(web程序)。在ssh中,可以实现在service层,标注方式解决懒加载.
- 在对象映射文件中配置,lazy=“false”
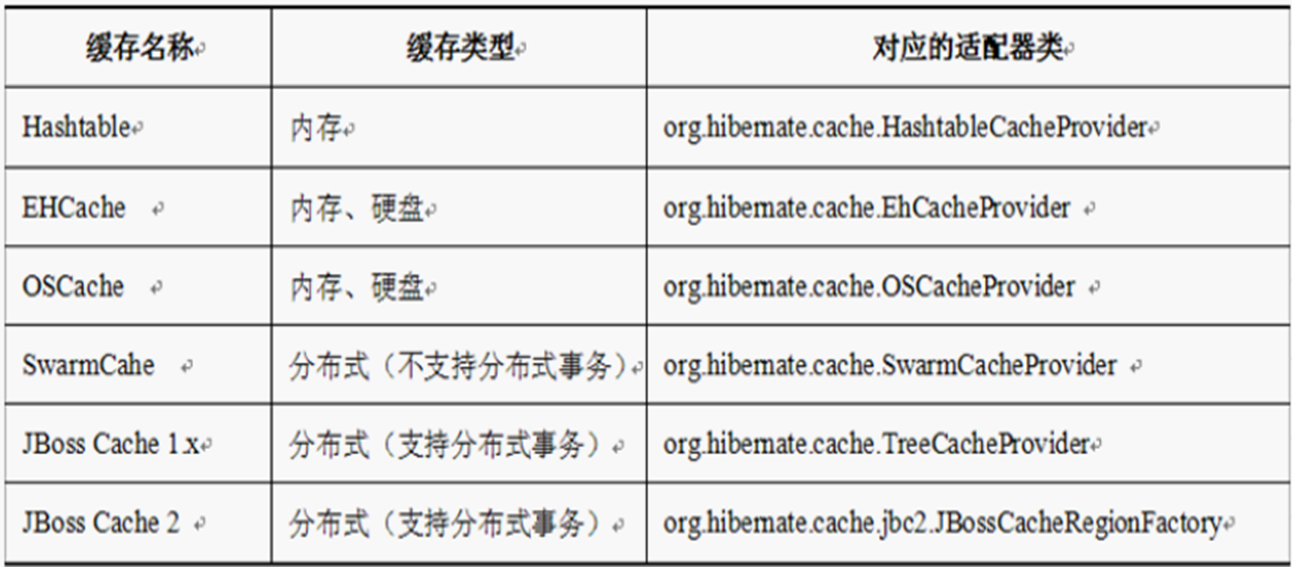
缓存
作用主要用来提高性能,可以简单的理解成一个Map;使用缓存涉及到三个操作:把数据放入缓存、从缓存中获取数据、删除缓存中的无效数据。
- 一级缓存,Session级共享。save,update,saveOrUpdate,load,get,list,iterate,lock这些方法都会将对象放在一级缓存中,一级缓存不能控制缓存的数量,所以要注意大批量操作数据时可能造成内存溢出;可以用evict,clear方法清除缓存中的内容。
- 二级缓存, SessionFacotry级共享
主键增长策略
Hibernate 中的持久化对象对应数据库中的一张数据表,因此区分不同的持久化对象,在Hibernate中是通过OID(对象标识符)来完成的,从表的角度看,OID对应表的主键。
- increment: 由Hibernate自动以递增方式生成标识符,每次增量为1。
优点:不依赖于底层数据库系统,适用于所有的数据库系统。
缺点:适用于单进程环境下,在多线程环境下很可能生成相同主键值,而且OID必须为数值类型,比如long,int,short类型
配置方式:
<id name=“id” type=”long” column=”ID”> <generator class=”increment”/> </id>
- indentity:由底层数据库生成标识符。
前提条件:数据库支持自动增长字段类型,比如(sql server,mysql),而且OID必须为数值类型,比如long,int,short类型。
配置文件:<id name=”id” type=”long” column=”ID”> <generator class=”identity”/> </id>
- sequence:依赖于底层数据库系统的序列
前提条件:需要数据库支持序列机制(如:oracle等),而且OID必须为数值类型,比如long,int,short类型。
配置文件:
<id name=”id” type=”java.lang.Long” column=”ID”> <generator class=”sequence”> <param name=”sequence”>my_seq</param> </generator> </id>
- hilo
hilo标识符生成器由Hibernate按照一种high/low算法生成标识符,他从数据库中的特定表的字段中获取high值,因此需要额外的数据库表保存主键生成的历史状态,hilo生成方法不依赖于底层数据库,因此适用于每一种数据库,但是OID必须为数值类型(long,int,shor类型)。
配置文件:
<id name=”id” type=”java.lang.Integer” column=”ID”> <generator class=”hilo”> <param name=”table”>my_hi_value</param> <param name=”column”>next_value</param> </generator> </id>
- native
native生成器能根据底层数据库系统的类型,自动选择合适的标识符生成器,因此非常适用于跨数据库平台开发,他会由Hibernate根据数据库适配器中的定义,自动采用identity,hilo,sequence的其中一种作为主键生成方式,但是OID必须为数值类型(比如long,short,int等)
配置文件:
<id name=”id” type=”java.lang.Integer” column=”ID”> <generator class=”native”/> </id>
- assigned
采用assign生成策略表示由应用程序逻辑来负责生成主键标识符,OID类型没有限制。
配置文件:
<id name=”id” type=”java.lang.Integer” column=”ID”> <generator class=”assigned”/> </id>
- uuid
由Hibernate基于128位唯一值产生算法,根据当前设备IP,时间,JVM启动时间,内部自增量等4个参数生成16进制数值作为主键,一般而言,利用uuid方式生成的主键提供最好的数据插入性能和数据库平台适应性. OID一般使用是String类型,大家去试试数值可否?
配置文件:
<id name=”id” type=”java.lang.String” column=”ID”> <generator class=”uuid”/> </id>
- foreign
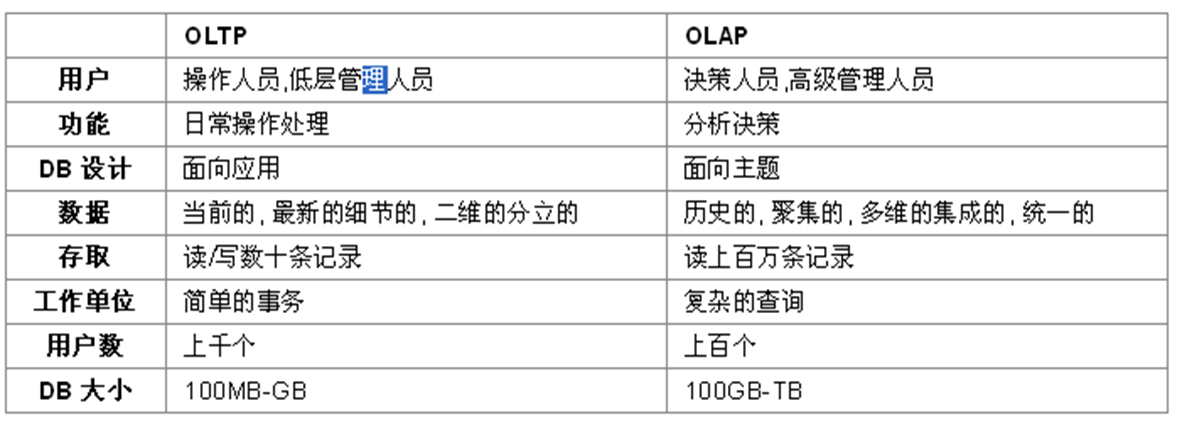
Hibernate不适合的场景
- 不适合OLAP(On-Line Analytical Processing联机分析处理),以查询分析数据为主的系统;适合OLTP(on-line transaction processing联机事务处理)。
- 对于些关系模型设计不合理的老系统,也不能发挥hibernate优势。
- 数据量巨大,性能要求苛刻的系统,hibernate也很难达到要求, 批量操作数据的效率也不高。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现