数据库三范式
什么是三范式
设计关系型数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
目前关系型数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。一般来说,数据库只需要满足第三范式就行了。
第一范式:保证每列的原子性
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库满足了第一范式。
第一范式需要根据系统的实际需求来定,比如有一张用户信息表:

一般来说"住址"设计成一个字段就行,但是如果经常访问"住址"中城市的部分,那么就非要将"住址"这个属性重新拆分为"省份"、"城市"、"地址"等多个部分进行存储,这样在对"住址"中某一部分进行操作的时候将非常方便。这么设计才算满足了数据库的第一范式,修改之后的表结构如图:

第二范式:保证一张表只描述一件事情
这是通俗的说法,用第二范式的定义描述第二范式,说的是在满足第一范式的基础上,数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖,也即所有非关键字段都完全依赖于任一组候选关键字。
看不懂是吗,没关系,我也看不懂,下面举一个例子,有一张表如下图:
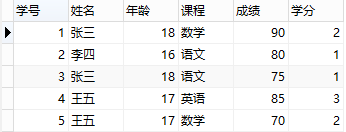
上表满足第一范式,即每个字段不可再分,但是这张表设计得并不好,或者说,这张表的设计并不满足第二范式。因为这张表里面描述了两件事情:学生信息、课程信息,"学分"完全依赖于"课程名称"、"姓名"与"年龄"完全依赖于"学号"。这么做的后果是:
1、数据冗余:同一门课程由n个学生选修,"学分"重复n-1次;同一个学生选修了m门课程,姓名和年龄重复m-1次
2、更新异常:若调整了某门课程的学分,数据表中所有行的"学分"值都需要更新,否则会出现同一门课程学分不同的情况
3、插入异常:假设要开一门新课程,暂时没有人选修,那么由于没有"学号"关键字,"课程"与"学分"也无法记录入数据库
4、删除异常:假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,"课程"和"学分"也被删除了,显然,这最终可能会导致插入异常
所以,此表的结构必须修改,修改后如下:
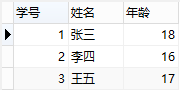
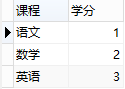
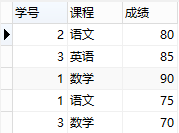
增加了表,将学生信息与课程信息通过一张中间表关联,很好地解决了上面的几个问题,这就是第二范式的中心----保证一张表只讲一件事情。
第三范式----保证每列都和主键直接相关
第三范式又和第二范式相关,用第三范式的定义描述第三范式就是,数据库表中如果不存在非关键字段任一候选关键字段的传递函数依赖则符合第三范式,所谓传递函数依赖指的是如果存在"A-->B-->C"的决定关系,则C传递函数依赖于A。也就是说表中的字段和主键直接对应不依靠其他中间字段,说白了就是,决定某字段值的必须是主键。
举个例子,看一下如下的表结构:
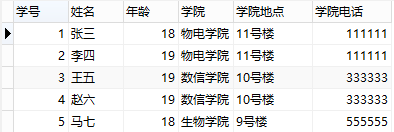
第三范式和第二范式有点像,从这张数据库表结构中可以看出,"姓名"、"年龄"、"学院"和主键"学号"直接关联,但是"学院地点"、"学院电话"却不直接和主键"学号"相关联,和"学院电话"直接相关联的是"学院",如果表结构这么设计,同样会造成和第二范式一样的数据冗余、更新异常、插入异常、删除异常的问题。
修改之后的表结构如下图:
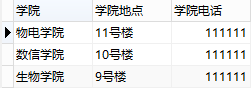
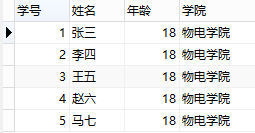
同样,这么设计表结构将合理地多,也解决了前面的四个问题。
后记
定理是死的,人是活的,在前人给我们总结出这些范式的前提下,使用这些范式灵活地应用到实际需求中,才是最重要的。
我不能保证写的每个地方都是对的,但是至少能保证不复制、不黏贴,保证每一句话、每一行代码都经过了认真的推敲、仔细的斟酌。每一篇文章的背后,希望都能看到自己对于技术、对于生活的态度。
我相信乔布斯说的,只有那些疯狂到认为自己可以改变世界的人才能真正地改变世界。面对压力,我可以挑灯夜战、不眠不休;面对困难,我愿意迎难而上、永不退缩。
其实我想说的是,我只是一个程序员,这就是我现在纯粹人生的全部。
==================================================================================

 浙公网安备 33010602011771号
浙公网安备 33010602011771号