【题解】 P7077 [CSP-S2020] 函数调用(dp,拓扑排序)
【题解】 P7077 [CSP-S2020] 函数调用
好题!
结合了 topsort 和线段树
(所以这题跟 DP 有什么关系?)
题目链接
题意概述
给定一个长度为
-
单点加;
-
全局乘;
-
以一定顺序调用其他操作,保证不直接或间接调用自身。
思路分析
首先刚开始我先打了个暴力。(雾)
得到了 45pts 的高分。
然后观察了一下数据范围发现:
-
数据点
-
数据点
往往当我们不会一道题的时候,数据范围总能成为突破口。——aqx
考虑一下如何处理这几个测试点。
首先考虑:对于操作
-
当不含操作
只有全局乘这一个操作,很容易想到利用线段树懒标记的思想,维护一个
-
当不含操作
发现可以在从
在这里从每个起点跑一遍,事实上也可以建立一个虚点
-
当不含操作
可以类比线段树 2,我们先举个例子:假如要对一个元素执行以下操作:
那么第一次操作
第二次操作
第三次操作:
第四次操作
可以发现,每次乘操作,会使得
那么我们就有了一个较为清晰的思路:
我们首先可以像线段树 2 一样规定“先乘后除”。
可以对于每个点
那么对于每次加操作,对于
对于每次乘操作,直接给全局乘标记乘上对应值即可。
最后输出每个
那么解决了上述这几个特殊性质的问题之后,我们就会顺利拿到 60pts 的高分。
而同时,上述这些特殊性质,也为我们想出正解提供了极大的帮助。
结合上述的性质我们便可以很容易想出此题正解。
首先对于所有的函数属性为
然后对于
接下来我们来看一张图:
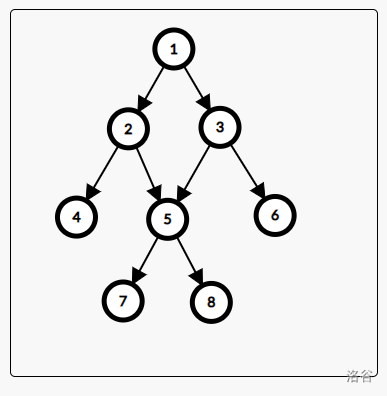
若
我们发现,一个节点的
那么我们可以用一个 topsort 求出
需要注意的是,这次的 topsort 的反向建图的。(因为是子节点更新父节点嘛。)
然后我们再看一张图:
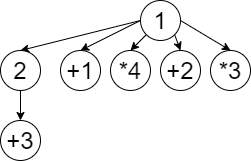
(选自洛谷)
假如
所以下传
那么只需要正向建图再跑一遍 topsort,求出每个节点的
那么最后只需要将
然后就结束了。
梳理一下整个求解思路:
对于所有的操作
易错点
-
对于所有操作属性为
-
-
第一次 topsort 要反向建图;
-
第二次 topsort 要倒序枚举每个子节点。
经验
-
一道难题一眼看不出正解时,不妨考虑打暴力,然后再优化暴力;
-
一定要多关注数据范围以及部分分和特殊性质,这些往往能成为你突破和解决问题的关键!
代码实现
//luoguP7077
//正解
#include<iostream>
#include<cstdio>
#include<cstring>
#include<string>
#include<queue>
#define int long long
using namespace std;
const int maxn=1e5+10;
const int mod=998244353;
int n,m;
int in1[maxn],in2[maxn];
int a[maxn],opt[maxn],p[maxn],v[maxn],add[maxn],mul[maxn],cnt[maxn];
basic_string<int>edge1[maxn],edge2[maxn];
inline int read()
{
int x=0,f=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')f=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){x=x*10+ch-48;ch=getchar();}
return x*f;
}
void topsort1()
{
queue<int>q;
for(int i=0;i<=m;i++)
{
if(in1[i]==0)q.push(i);
}
while(!q.empty())
{
int now=q.front();
q.pop();
for(int nxt:edge1[now])
{
(mul[nxt]*=mul[now])%=mod;
in1[nxt]--;
if(!in1[nxt])q.push(nxt);
}
}
return ;
}
void topsort2()
{
queue<int>q;
for(int i=0;i<=m;i++)
{
if(!in2[i])q.push(i);
}
while(!q.empty())
{
int now=q.front();
q.pop();
int Mul=1;
for(int i=edge2[now].size()-1;i>=0;i--)
{
int nxt=edge2[now][i];
cnt[nxt]=(cnt[nxt]+cnt[now]*Mul%mod)%mod;
(Mul*=mul[nxt])%=mod;
in2[nxt]--;
if(!in2[nxt])q.push(nxt);
}
}
return ;
}
signed main()
{
n=read();
for(int i=1;i<=n;i++)a[i]=read();
m=read();
mul[0]=1;
for(int i=1;i<=m;i++)
{
opt[i]=read();
if(opt[i]==1)
{
p[i]=read();add[i]=read();
mul[i]=1;
}
else if(opt[i]==2) mul[i]=read();
else
{
v[i]=read();mul[i]=1;
for(int j=1;j<=v[i];j++)
{
int x=read();
edge2[i]+=x;edge1[x]+=i;
in2[x]++;in1[i]++;
}
}
}
int q=read();
cnt[0]=1;
for(int i=1;i<=q;i++)
{
int x=read();
int tt=0;
edge2[0]+=x;
edge1[x]+=tt;
in2[x]++;in1[0]++;
}
topsort1();
topsort2();
for(int i=1;i<=n;i++)(a[i]*=mul[0])%=mod;
for(int i=1;i<=m;i++)
{
if(opt[i]==1)(a[p[i]]=a[p[i]]+add[i]*cnt[i]%mod)%=mod;
}
for(int i=1;i<=n;i++)cout<<a[i]<<" ";
cout<<'\n';
return 0;
}
/*3
1 2 3
3
1 1 1
2 2
3 2 1 2
2
2 3*/



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!