【文化课学习笔记】【数学】统计与概率
【数学】统计与概率
统计
定义
为了实现某种调查目的,进行收集数据,整理数据,分析数据。
收集数据
方法:全面调查和抽样调查。
全面调查:调查所有对象。优点:全面。缺点:工作量大。
抽样调查:从全体中抽取一部分样本调查。抽样调查必须保证每个个体有相同的几率被抽到。
高中阶段介绍了三种抽样调查:简单随机抽样、系统抽样和分层抽样。
简单随机抽样
适用范围:当总体中的个体之间差异程度较小,并且总体中个体数目较少时,通常采用这种方法。
内容:抽签,随机数法。
系统抽样(等距抽样)
适用范围:总体数量和需要抽取的数量都比较大。
内容:线分段在第一段中随机抽取一个,再依次加上分段间隔。
例如:在 \(1000\) 名学生中抽取 \(100\) 人,根据系统抽样,可以首先将 \(1000\) 个人平均分为 \(100\) 段,每段 \(10\) 人,将每一段的所有人从 \(1\) 到 \(10\) 编号,然后在 \(1\) 到 \(10\) 中随机抽取一个编号,对每一段都抽取这个编号。则抽到的 \(100\) 个人即为所求。
分层抽样(按比例抽样)
适用范围:调查对象可分成有明显差别的、互不重叠的几部分。
内容:每一部分可称为层,在各层中按层在总体中所占比例进行随机抽样。
例如:某校有 \(300\) 名男生,\(700\) 名女生,需要抽取 \(100\) 人调查身高情况。
由于身高与性别有关,所以需要分层。可以按照男女比例为 \(3:7\) 抽取 \(30\) 个男生,\(70\) 个女生,调查身高。
整理数据
茎叶图
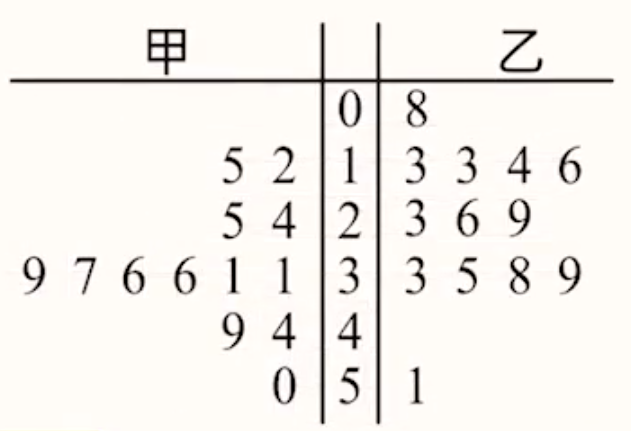
以上图为例。中间一列叫做茎,表示高位数字,甲和乙共用。两边的列叫做叶,表示低位数字,甲和乙各自用。
观察时可一行一行看,那么甲对应的数为 \(0,12,15,24,25,\cdots\),乙对应的数为 \(8,13,13,14,16,23,26,29,\cdots\)。
频率分布直方图
频数:对应区间有几个对象(出现的次数)。
频率:对应区间占总人数的比(比值)。所有的频率之和为 \(1\)。
频数分布直方图的纵坐标表示频数,即每个组的个数;频率分布直方图纵坐标不表示频率,而表示 \(\dfrac{频率}{组距}\),组距即为每一组对应区间的端点之差。
做有关频率分布直方图的问题时,应该先找到组距,再根据组距 \(\times\) 纵坐标求得每一组的频率。
在频率分布直方图中,每个矩形的面积即为频率。
技巧方法:
- 利用频率分布直方图估计平均数时,可以通过直方图求出每组的频率,然后通过每组频率 \(\times\) 对应组的组中值 再相加的方式估算。注意:若题目告诉用每组的某个对应值代替每组的平均数,则直接代入即可;若没有告诉,则利用对应组的组中值代替平均数。
- 利用频率分布直方图估计中位数时,由于每一组的矩形面积即为每一组的频率,则需要找到一条直线 \(x = a\) 平分图中所有矩形面积,通过图形找出对应 \(x = a\) 所在组然后根据面积估算即可。
分析数据
统计量
表示数据集中程度:平均数,中位数,众数。
表示数据离散程度:极差,方差,标准差。
平均数
定义:给定一组数 \(x_1,x_2, \cdots,x_n\),则其平均数为 \(\overline x = \dfrac 1 n (x_1 + x_2 +\cdots + x_n)\),常记为 \(\overline x = \dfrac 1 n \sum \limits_{i = 1}^n x_i\)。
用频率计算平均数:将每个数与其出现的频率相乘,再相加。
性质:
- 把一组数同时加上 \(b\),则平均数也加 \(b\)。
- 把一组数同时乘上 \(a\),则平均数也乘 \(a\)。
中位数
定义:
- 如果一组数有奇数个,且按照从小到大排列 \(x_1,x_2,\cdots,x_{2n + 1}\),则 \(x_{n+1}\) 为中位数。
- 如果一组数有偶数个,且按照从小到大排列 \(x_1,x_2,\cdots,x_{2n}\),则 \(\dfrac{x_n + x_{n + 1}}{2}\) 为中位数。
性质:
- 把一组数同时加上 \(b\),则中位数也加 \(b\)。
- 把一组数同时乘上 \(a\),则中位数也乘 \(a\)。
众数
定义:一组数据中,出现次数最多的数据。众数可以不唯一。
如果所有数出现的次数相同,则没有众数。
性质:
- 把一组数同时加上 \(b\),则众数也加 \(b\)。
- 把一组数同时乘上 \(a\),则众数也乘 \(a\)。
极差
定义:一组数的极差指的是这组数的最大值减去最小值的差。
性质:
- 把一组数同时加上常数 \(b\),则极差不变。
- 把一组数同时乘上常数 \(a\),则极差乘 \(|a|\)。
方差和标准差
定义:如果 \(x_1,x_2,\cdots,x_n\) 的平均数为 \(\overline x\),则方差 \(s^2 = \dfrac 1 n \sum \limits_{i = 1}^n (x_i - \overline x)^2\)。其中方差的算术平方根 \(s\) 称为标准差。
本质:方差表示的是一组数偏离平均数的偏离程度。
求方差的步骤:
- 求平均数。
- 每个数减去平均数再平方。
- 求第二步得到的所有数的平均数。
方差的性质:
- 把一组数同时加上常数 \(b\),则方差不变。
- 把一组数同时乘上常数 \(a\),则方差乘 \(a^2\)。
标准差的性质:
- 把一组数同时加上常数 \(b\),则标准差不变。
- 把一组数同时乘上常数 \(a\),则标准差乘 \(|a|\)。
性质规律总结
把一组数同时加上常数 \(b\),则:平均数、中位数、众数都 \(+b\),极差、标准差、方差都不变。
把一组数同时乘上常数 \(a\),则:平均数、中位数、众数都 \(\times a\),极差、标准差都 \(\times |a|\),方差 \(\times a^2\)。
小技巧:求两组数平均数的差,除了可以将两者平均数分别算出再作差之外。当两组数个数相同时,还可以对两组数对应位置的数相减,再将得到的值相加,除以个数。
概率
定义
事件发生可能性的大小。这里的事件指的是随机事件。
随机试验:结果随机/不确定的试验。
样本点与样本空间:我们把随机试验中每一种可能出现的结果,都称为样本点;把由所有样本点组成的集合称为样本空间,通常用大写希腊字母 \(\Omega\) 表示。
随机事件:如果随机试验的样本空间为 \(\Omega\),则随机事件 \(A\) 是 \(\Omega\) 的一个子集。而且若试验的结果是 \(A\) 中的元素,则称 \(A\) 发生(或出现等),否则,称 \(A\) 不发生(或不出现等)。
事件中的三个概念
【互斥事件】
给定事件 \(A,B\),若事件 \(A\) 与 \(B\) 不能同时发生,则称 \(A\) 与 \(B\) 互斥。所以互斥事件两个事件的交集为空。
一般地,如果 \(A_1,A_2,\cdots,A_n\) 是两两互斥的事件,则 \(P(A_1 + A_2 + \cdots + A_n) = P(A_1) + P(A_2) + \cdots + P(A_n)\),即 \(n\) 个事件至少发生一个的概率等于每一个事件各自发生的概率之和。
【对立事件】
给定事件 \(A,B\),若事件 \(A\) 与 \(B\) 不能同时发生,且 \(A\) 与 \(B\) 必有一个会发生,则称 \(A\) 与 \(B\) 对立,\(A\) 的对立事件记作 \(\overline A\)。所以对立事件中的两个事件互为补集。
所以对立事件一定是互斥事件,即对立事件是互斥事件的充分不必要条件,\(A\) 与 \(B\) 对立 \(\implies A\) 与 \(B\) 互斥。
对于一个事件 \(A\),有 \(P(A) + P(\overline A) = 1\)。
【相互独立事件】
若事件 \(A\) 是否发生对事件 \(B\) 的发生概率无影响,则称事件 \(A,B\) 相互独立。当 \(P(AB) = P(A)P(B)\) 时,就称事件 \(A\) 与 \(B\) 相互独立(简称独立),即 \(A\) 与 \(B\) 相互独立 \(\iff P(AB) = P(A)P(B)\),其中 \(P(AB)\) 表示事件 \(A,B\) 同时发生的概率。
计算每个事件发生的概率可以通过目标事件数除以总事件数,总事件数可以利用表格列举法求解。
计算概率的方法
【用频率估计概率】
一般地,如果在 \(n\) 次重复进行的试验中,事件 \(A\) 发生的概率为 \(\dfrac m n\),则当 \(n\) 很大时,可以认为事件 \(A\) 发生的概率 \(P(A)\) 的估计值为 \(\dfrac m n\)。
【用事件数计算概率(古典概型)】
古典概型:当结果有有限多个,且每种结果出现的可能性相等时即可用此方法。一般情况下题目会给定一个事件,问满足某些条件的概率是多少,题目当中一般不会给定任何已知的概率。
【用概率计算概率(独立事件)】
适用范围:①已知条件中会告诉某些概率;②某些事件相互独立(互不影响)。
内容:若 \(A,B\) 独立,则 \(P(AB) = P(A)P(B)\)。
对于题目中求至少有一个的概率可以拆解成多个不同的状态求解。例如:甲、乙两球至少有一个落入盒子的概率,可以拆解成甲落,乙落;甲落乙不落;甲不落乙落。三种情况各自分别用乘法计算,然后将三种情况下的概率相加即可。也可以反面计算,即用 \(1\) 减去两者均不落入盒子的概率。
随机变量
定义
如果随机试验的样本空间为 \(\Omega\),且对于 \(\Omega\) 中的每一个样本点,变量 \(X\) 都对应有唯一确定的实数值,就称 \(X\) 为一个随机变量。
随机变量一般用大写英文字母 \(X,Y,Z,\cdots\) 或小写希腊字母 \(\xi,\eta,\cdots\) 表示。
随机变量所有可能的取值组成的集合,称为这个随机变量的取值范围。
例如,把扔骰子可能的结果记为 \(X\),则 \(X\) 可能为 \(1,2,3,4,5,6\),这里的 \(X\) 即为一个随机变量。
分布列
| \(X\) | \(x_1\) | \(x_2\) | \(\cdots\) | \(x_k\) | \(\cdots\) | \(x_n\) |
|---|---|---|---|---|---|---|
| \(P\) | \(p_1\) | \(p_2\) | \(\cdots\) | \(p_k\) | \(\cdots\) | \(p_n\) |
第一行表示随机变量 \(X\) 的所有取值,第二行表示每个取值对应的概率。
离散型随机变量的分布列必须满足:
- \(p_k \ge 0,k = 1,2,\cdots,n\)。
- \(\sum \limits_{k = 1}^n p_k = p_1 + p_2 + \cdots + p_n = 1\)。
期望(均值)
| \(X\) | \(x_1\) | \(x_2\) | \(\cdots\) | \(x_k\) | \(\cdots\) | \(x_n\) |
|---|---|---|---|---|---|---|
| \(P\) | \(p_1\) | \(p_2\) | \(\cdots\) | \(p_k\) | \(\cdots\) | \(p_n\) |
对于上述分布列,则期望 \(E(x) = x_1p_1 + x_2p_2 + \cdots + x_np_n\)。
性质:若 \(X\) 与 \(Y\) 都是随机变量,且 \(Y = aX + b(a \ne 0)\),则 \(E(Y) = aE(x) + b\)。
方差
分布列同上。
对于上述分布列,方差 \(D(X) = [x_1 - E(x)]^2 p1 + [x_2 - E(x)]^2 p2 + \cdots + [x_n - E(x)]^2 p_n\)。
其中,\(\sqrt{D(X)}\) 叫做随机变量 \(X\) 的标准差。
性质:若 \(X\) 与 \(Y\) 都是随机变量,且 \(Y = aX + b(a \ne 0)\),则 \(D(Y) = a^2 D(X)\)。
二项分布
\(n\) 次独立重复试验(\(n\) 重伯努利试验)
将同一随机试验重复 \(n\) 次,每次试验是独立的,每次试验只有 \(2\) 种结果,每种结果的概率是不变的。
二项分布的定义
如果一次试验中,出现「成功」的概率为 \(p\),且 \(n\) 次独立重复试验中出现「成功」的次数为 \(X\),称 \(X\) 服从参数为 \(n,p\) 的二项分布,记作 \(X \sim B(n,p)\),其中 \(X\) 的取值范围是 \(\{0,1,\cdots,k,\cdots,n\}\)。
则独立重复试验中出现 \(k\) 次成功的概率即为 \(P(X = k) = \mathrm C_n^k p^k(1 - p)^{n-k},k = 0,1,\cdots,n\)。
二项分布求概率的一般方法:先找到随机变量 \(X\) 所有的取值,观察需要计算的概率对应到随机变量的哪些取值,然后用加法或减法计算概率(一般选择情况较少的一种方法)。
二项分布的期望和方差
若 \(X\) 服从参数为 \(n,p\) 的二项分布,即 \(X \sim B(n,p)\),则 \(E(X) = np,D(X) = np(1 - p)\)。
注意:求解二项分布的数学期望时,一般首先要说明 \(X \sim B(n,p)\)。
求解有关二项分布的题型时,可以考虑表格法,即画出每一次独立试验和对应成功/失败的概率,观察分析求解。
例题
例 1:一带中有 \(5\) 个白球,\(3\) 个红球,现从袋中往外取球,每次任取一个记下颜色后放回,直到红球出现 \(10\) 次时停止,设停止时共取了 \(X\) 次球,则 \(P(X = 12)\) 是多少。
分析:
题目求 \(P(x = 12)\) 相当于求当抽到第 \(12\) 次时,红球出现了 \(10\) 次,求抽到 \(12\) 次暂停的概率是多少。
由于当出现 \(10\) 次红球时停止,所以第 \(12\) 次一定抽到的是红球,所以只需要让前 \(11\) 次总共抽到 \(9\) 次红球,\(2\) 次白球,所以概率 \(P(X = 12) = \mathrm C_{11}^9 {\left(\dfrac{3}{8}\right)}^{10}\cdot {\left(\dfrac 5 8\right)}^2\)。
注意:此类题目虽然看起来与二项分布很像,但并不是二项分布,注意观察题目条件的区别,不要硬套。
超几何分布
一般地,若有总数为 \(N\) 件的甲、乙两类物品,其中甲类 \(M\) 件(\(M < N\)),从所有物品中随机取出 \(n\) 件(\(n \le N\)),则这 \(n\) 件中所含甲类物品数 \(X\) 时一个离散型随机变量,称 \(X\) 服从参数为 \(N,n,M\) 的超几何分布,且 \(E(X) = \dfrac{nM}{N}\)。
直观理解:两类物品,每类物品的数量确定,从两类物品中共抽出固定数量的物品,\(X\) 是抽出的物品中其中一类的数量,则 \(X\) 的期望 \(=\) 抽出的数量 \(\times\) 这类物品的比例。
超几何分布计算概率一般可用 目标事件数除以总事件数 计算,求分布列可以列出所有随机变量 \(X\) 可能的情况,再将每一种情况的概率计算求得。
二项分布与超几何分布的区别
二项分布:多次试验,每次试验有两种结果,每种结果的概率确定。
超几何分布:两类物品取固定数量,每类物品的数量确定。
简单来说,二项分布是有放回的抽取,而超几何分布是一次性抽取。
核心区别:
- 二项分布:概率确定,数量不确定,所以一般用概率计算概率。
- 超几何分布:数量确定,概率不确定,所以一般用事件数计算概率。
例如:扔 \(100\) 次硬币,正面朝上和朝下的概率都是 \(\dfrac 1 2\)(概率确定),但正面朝上和朝下的具体数量不确定,这就属于二项分布;\(50\) 名男生,\(50\) 名女生,从中选 \(40\) 人(数量确定),每次选到男生女生的概率不确定,这就属于超几何分布。
例:某精准扶贫帮扶单位,为帮助顶点扶贫村真正脱贫,坚持扶贫同扶智相结合,帮助精准扶贫户利用互联网电商渠道销售当地特产苹果。苹果单果直径不同单价不同,为了更好地销售,现从该精准扶贫户种植的苹果树上随即摘下 \(50\) 个苹果测量其直径,经统计,其单果直径分布在区间 \([50,95]\) 内(单位:\(\pu{mm}\)),统计地茎叶图如图所示:

以此茎叶图中单果直径出现的频率代表概率,直径位于 \([65,90)\) 内的苹果称为优质苹果,对于该精准扶贫户的这批苹果,某电商提出两种收购方案:
方案 A:所有苹果均以 \(5\) 元/千克收购;
方案 B:从这批苹果中随机抽取 \(3\) 个苹果,若都是优质苹果,则按 \(6\) 元/千克收购;若有 \(1\) 个非优质苹果, 则按 \(5\) 元/千克收购;若有 \(2\) 个非优质苹果,则按 \(4.5\) 元/千克收购;若有 \(3\) 个非优质苹果,则按 \(4\) 元/千克收购。
请你通过计算为该精准扶贫户推荐最好的方案。
分析:
所谓最好的方案,就是将方案 A 的苹果单价与方案 B 的期望苹果单价作比较,然后选择苹果单价更高的作为最好方案。
由于方案 A 的苹果单价已知,那么问题转化为计算方案 B 的期望苹果单价。
观察题目可知,方案 B 是从这批苹果中随机抽取 \(3\) 个苹果,并不是从题目茎叶图已知的 \(50\) 个苹果中抽取 \(3\) 个,所以相当于数量不确定,又由于题目告诉了让用频率代表概率,所以相当于概率确定;又由于这批苹果的基数很大,所以抽取 \(1\) 个苹果后不放回对抽取下一个苹果的概率影响极小,所以综合而言,可以近似认为它属于二项分布。
那么将茎叶图中的 \(50\) 个苹果的直径分为在 \([65,90)\) 内和不在 \([65,90)\) 内的,发现有 \(40\) 个优质苹果,\(10\) 个非优质苹果,所以可以认为优质苹果的概率为 \(\dfrac 4 5\),非优质苹果的概率为 \(\dfrac 1 5\)。设 B 方案的收购价格为 \(X\),则:
由于二项分布的期望计算公式里的 \(X\) 表示的是某种结果出现的次数,不适用于这里的收购价格,那么需要使用期望的定义求解。
则
推荐方案 B。
总结:
此类题目地特点:从全体中抽取一部分样本,已知样本数据。
如果题目是从样本中抽取几个,则样本数量确定,属于超几何分布,用事件数计算概率。
如果题目是从全体中抽取几个,且已知「用频率代替概率」,则属于二项分布,用概率(频率)计算概率。

