
生成器和迭代器
列表生成式:[ x for y in z ]:x为结果,y用于遍历z,z为一个可迭代对象,x跟y必须要对应上,即x用y表示


eg: a=[i*2 for i in range(10)] >>> a [0,2,4,6,8,10,12,14,16,18] 使代码更加简洁,相当于: >>>a = [] >>>for i in range(10): ... a.append(i*2) ... >>>a [0,2,4,6,8,10,12,14,16,18]
的确,通过列表生成式,我们可以更加简便的创建一个列表,但是,当一个列表的数据量很大很大,超过百万个元素,而我们要用到的就只有前面的几个时,占用的内存空间就白白浪费了,为此,在python中,有一种一遍循环一遍计算的机制------生成器,即generator。只能一个一个的获取,当调用到这个元素时才生成相应的数据,而且只记录当前的数据而不能记录前面的数据,不支持切片获取,这,就是生成器...
为什么生成器只能记录当前的数据?
因为python有一个垃圾回收机制:数据占有内存而不被变量引用时,内存空间将会被回收,根据这个机制,假设生成器s永远指向当前数据的内存地址,被引用过的数据因为没有变量引用而被删除。。。
生成器的创建有多两种方法:
1.把列表生成式中的[ ]改成()
>>> a = (i*2 for i in range(10)) >>> a <generator object <genexpr> at 0x000001FA53C9E938>
generator保存的是算法,直接输出将会输出内存地址,不能通过切片获取数据,要想一个一个打印出数据,只能用__next__()方法(在2.7中为next()),但是,一般这种带"_"的方法尽量不要使用,在py.3版本中,一般用next(a)
>>> a.__next__() 0 >>> a.__next__() 2 >>> a.__next__() 4 >>> a.__next__() 6 >>> a.__next__() 8 >>> a.__next__() 10 >>> a.__next__() 12 >>> a.__next__() 14 >>> a.__next__() 16 >>> a.__next__() 18 >>> a.__next__() Traceback (most recent call last): File "<input>", line 1, in <module> StopIteration
每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
用for循环可以避免这个问题:
a = (i*2 for i in range(10)) for i in a: print(i)
for循环,每循环一次就是对内部进行一次next调用,即
for i in a: while True: i = next(f) print(i)
若for循环前面有next方法,for循环会从next()停留的状态开始遍历数据
2.用yield来实现:
斐波那契数列:除第一个和第二个数外,任意一个数都可由前两个数相加得到
1,1,2,3,5,8,13,21,34,55......
这个数列用列表生成式写不出来,但是用函数却可以很轻松地怼出来
def fib(mac): n,a,b = 0,0,1 while n <= mac: print(b) a,b=b,a+b n += 1 return 'done'
注意,赋值语句:
a, b = b, a + b
相当于:
t = (b, a + b) # t是一个tuple a = t[0] b = t[1]
把print改成yield之后,就变成了一个生成器,即
def fib(mac): n,a,b = 0,0,1 while n <= mac: yield b a,b=b,a+b n += 1 return 'done'
如图,fib()是生成一个生成器对象,调用它之后,只是生成了函数的内存地址,并没用进入函数去执行函数
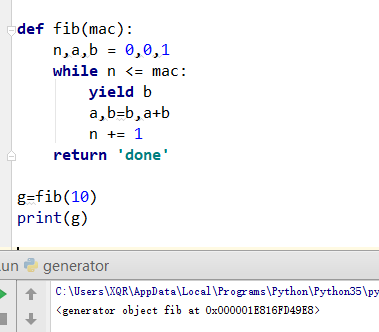
调用next方法可以把数字一个一个打印出来:

关于yield,下面举一个例子了解一下:
def foo(): print('ok1') yield 1 print('ok2') yield 2 g=foo() print(g) a=next(g) b=next(g) print(a,b) >>> <generator object foo at 0x000002ED6C2A49E8> >>>ok1 ok2 1 2
执行一次next调用之后,生成器的状态将会保存在yield 1 那里,再次调用next,将会从print('ok2')开始执行
生成器遇到yield时,可以从函数里面暂时跳出来执行别的操作,等下次调用next是再进入函数,并且从上次出来的地方继续执行
yield的功能:一是暂时跳出函数,二是跟return一样,返回值;比如上面第一次调用next时,先打印ok1,然后跳出函数并返回1
用yield创建的生成器,有一个send方法,这个方法跟next方法差不多,能够进入函数体里面执行命令,不同处在于它同时也还可以给yield前的变量赋值;如果yield前没有这个变量,那么就没有被传的对象了,但是不会报错,变成跟next一样的效果。
但是要注意,send前若无next方法,只能传送None,因为它不知道要传送值给谁
def bar(): print('ok1') count = yield 1 print(count) print('ok2') yield 2 b=bar() print(b.send(None))#相当于next(b), 状态保存在yield 1,并返回1给b.send(None) print(b.send('eee'))#先返回yield 1,然后把‘eee’传送给count,再执行函数,直到遇到yield
迭代器(Iterator):生成器都是迭代器,但是迭代器不一定是生成器
迭代器具备两个条件:
1.有iter方法
2.有next方法
【生成器之所以能调用next方法,是因为它本身属于迭代器】
l=[1,2,3,4,5,6] d=iter(l)#相当于__iter__,返回一个迭代器对象,<list_iterator object at 0x0000022E796C7978> print(d)#>>><list_iterator object at 0x0000022E796C7978>
for循环后面加的必须是可迭代对象(iterable),有iter方法的成为可迭代对象
可以使用isinstance()判断一个对象是否是Iterator对象,如下:
>>> from collections import Iterable >>> isinstance([], Iterable) True >>> isinstance({}, Iterable) True >>> isinstance('abc', Iterable) True >>> isinstance((x for x in range(10)), Iterable) True >>> isinstance(100, Iterable) False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator) True >>> isinstance(iter('abc'), Iterator) True
关于for循环内部处理的三件事;
1.调用可迭代对象的iter()方法返回一个迭代器对象
2.调用next()方法
3.处理stopiteration异常
