结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
实验目的
结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
实验过程
一、理解task_struct数据结构
进程是处于执行期的程序以及它所管理的资源(如打开的文件、挂起的信号、进程状态、地址空间等等)的总称。
在linux操作系统下,当触发任何一个事件时,系统都将它定义为一个进程,并且给予这个进程一个ID,即PID。
那么如何产生一个进程呢?简单来说就是“执行一个程序或命令”。
Linux内核通过一个被称为进程描述符的task_struct结构体来管理进程,这个结构体包含了一个进程所需的所有信息。
为了管理进程,操作系统必须对每个进程所做的事情进行清楚的描述,为此,操作系统使用数据结构来代表处理不同的实体,这个数据结构就是通常所说的进程描述符或进程控制块(PCB)。
在linux操作系统下这就是task_struct结构 ,所属的头文件#include <sched.h>每个进程都会被分配一个task_struct结构,它包含了这个进程的所有信息,在任何时候操作系统都能够跟踪这个结构的信息.
一个进程创建的另一个新进程称为子进程。相反地,创建子进程的进程称为父进程。
对于一个普通的用户进程,它的父进程就是执行它的哪个Shell,对于Linux而言,Shell就是bash
二、分析fork函数对应的内核处理过程
Linux中创建进程一共有三个函数
fork,创建子进程
vfork,与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。
clone,主要用于创建线程
do_fork代码:
long do_fork(unsigned long clone_flags, unsigned long stack_start, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; // ... // 复制进程描述符,返回创建的task_struct的指针 p = copy_process(clone_flags, stack_start, stack_size, child_tidptr, NULL, trace); if (!IS_ERR(p)) { struct completion vfork; struct pid *pid; trace_sched_process_fork(current, p); // 取出task结构体内的pid pid = get_task_pid(p, PIDTYPE_PID); nr = pid_vnr(pid); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); // 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行 if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); get_task_struct(p); } // 将子进程添加到调度器的队列,使得子进程有机会获得CPU wake_up_new_task(p); // ... // 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间 // 保证子进程优先于父进程运行 if (clone_flags & CLONE_VFORK) { if (!wait_for_vfork_done(p, &vfork)) ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid); } put_pid(pid); } else { nr = PTR_ERR(p); } return nr; }
具体流程如下:
fork, vfork和clone的系统调用定义是依赖于体系结构的, 因为在用户空间和内核空间之间传递参数的方法因体系结构而异,但他们都调用体系结构无关的_do_fork(或者早期的do_fork)函数, 负责进程的复制。
_do_fork以调用copy_process开始, 后者执行生成新的进程的实际工作, 并根据指定的标志复制父进程的数据。在子进程生成后, 内核必须执行一些收尾操作,如复制进程信息,子进程加入调度器等。
copy_process流程:调用 dup_task_struct复制当前的task_struct->检查进程数限制并初始化CPU 定时器等信息->调用 sched_fork 初始化进程数据结构,并把进程状态设置为 TASK_RUNNING->复制所以进程信息并调用copy_thread_tls初始化子进程内核栈->为新进程分配设置新的pid。
三、使用gdb跟踪分析一个fork系统调用过程
使用上次编译好内核的虚拟机环境
启动menuos
进入gdb调试模式
gdb file linux-5.0.1/vmlinux
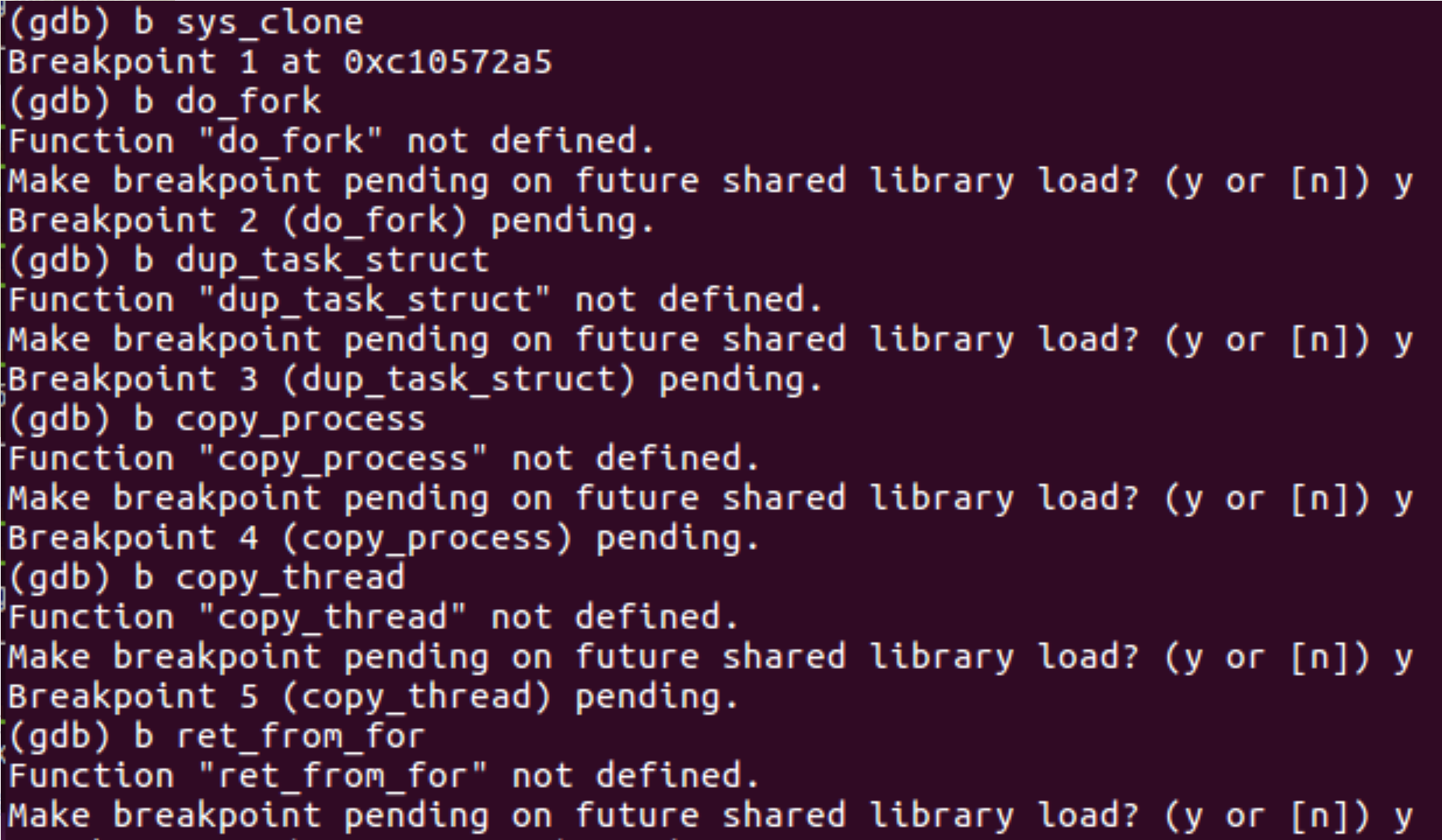
在这几个地方设置断点
b sys_clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_for
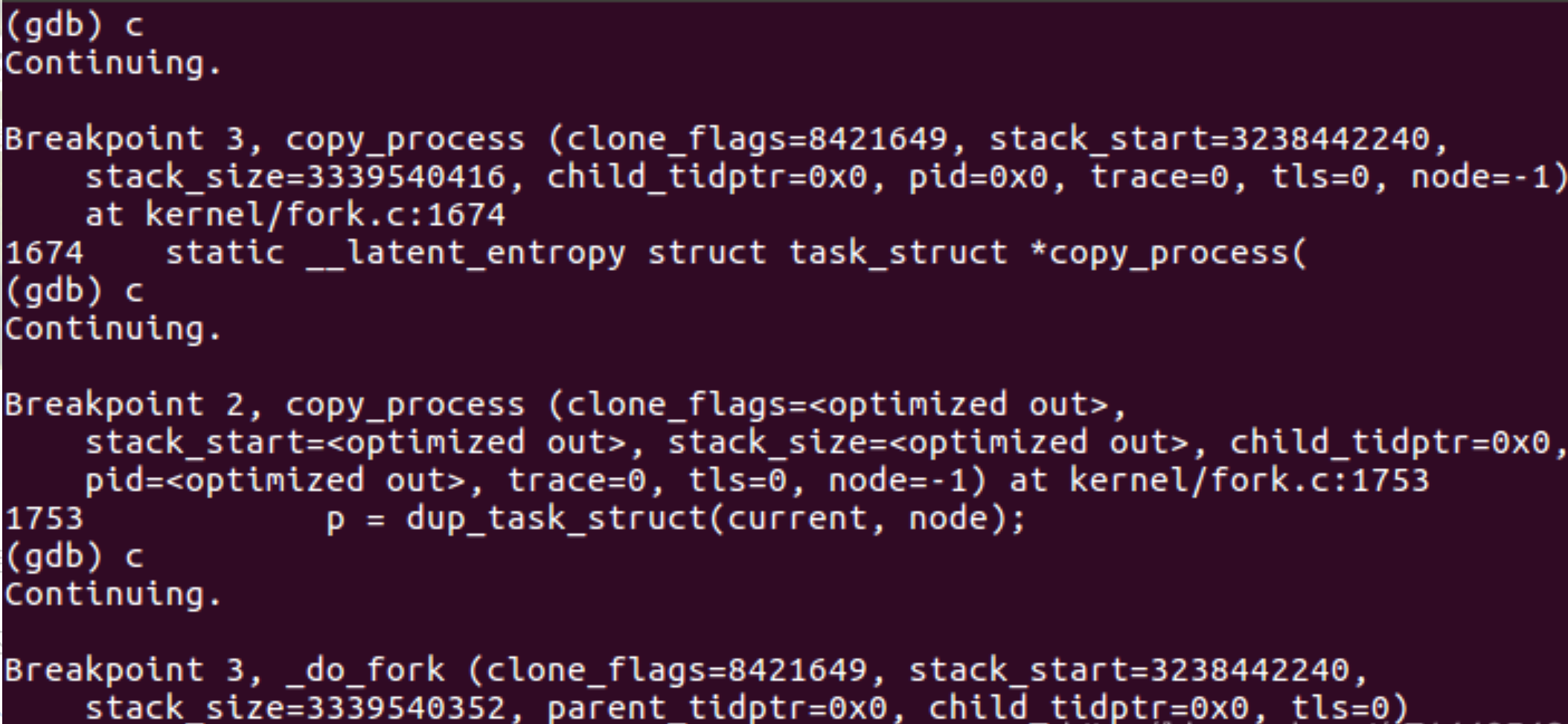
根据上述调试方法可以得到如下的结果:
理解编译链接的过程和ELF可执行文件格式
ELF文件格式包括三种主要的类型:可执行文件、可重定向文件、共享库。
1.可执行文件(应用程序)可执行文件包含了代码和数据,是可以直接运行的程序。
2.可重定向文件(.o)可重定向文件又称为目标文件,它包含了代码和数据(这些数据是和其他重定位文件和共享的object文件一起连接时使用的)。
.o文件参与程序的连接(创建一个程序)和程序的执行(运行一个程序),它提供了一个方便有效的方法来用并行的视角看待文件的内容,这些.o文件的活动可以反映出不同的需要。
Linux下,我们可以用gcc -c编译源文件时可将其编译成.o格式。
3.共享文件(*.so)也称为动态库文件,它包含了代码和数据(这些数据是在连接时候被连接器ld和运行时动态连接器使用的)。动态连接器可能称为ld.so.1,libc.so.1或者 ld-linux.so.1。
静态链接与动态链接
静态链接
在编译链接时直接将需要的执行代码复制到最终可执行文件中,有点是代码的装在速度块,执 行速度也比较快,对外部环境依赖度低。编译时它会把需要的所有代码都链接进去,应用程序相对较大。
动态链接
动态链接是在程序运行时由操作系统将需要的动态库加载到内存中。动态链接分为装载时动态链接和运行时动态链接。
理解Linux系统中进程调度的时机
(1).中断处理过程(包括时钟中断、I/O中断、系统调用和异常)中,直接调用schedule(),或者返回用户态时根据need_resched标记调用schedule();
(2).内核线程可以直接调用schedule()进行进程切换,也可以在中断处理过程中进行调度,也就是说内核线程作为一类的特殊的进程可以主动调度,也可以被动调度;
(3).用户态进程无法实现主动调度,仅能通过陷入内核态后的某个时机点进行调度,即在中断处理过程中进行调度。
特别关注并仔细分析switch_to中的汇编代码,理解进程上下文的切换机制,以及与中断上下文切换的关系
(1).关键函数的调用关系:
schedule() --> context_switch() --> switch_to --> __switch_to()
(2).代码分析
asm volatile(“pushfl\n\t” /* 保存当前进程的标志位 / “pushl %%ebp\n\t” / 保存当前进程的堆栈基址EBP / “movl %%esp,%[prev_sp]\n\t” / 保存当前栈顶ESP / “movl %[next_sp],%%esp\n\t” / 把下一个进程的栈顶放到esp寄存器中,完成了内核堆栈的切换,从此往下压栈都是在next进程的内核堆栈中。 / “movl $1f,%[prev_ip]\n\t” / 保存当前进程的EIP / “pushl %[next_ip]\n\t” / 把下一个进程的起点EIP压入堆栈 / __switch_canary “jmp __switch_to\n” / 因为是函数所以是jmp,通过寄存器传递参数,寄存器是prev-a,next-d,当函数执行结束ret时因为没有压栈当前eip,所以需要使用之前压栈的eip,就是pop出next_ip。 */ “1:\t” /* 认为next进程开始执行。 / “popl %%ebp\n\t” / restore EBP / “popfl\n” / restore flags / / output parameters 因为处于中断上下文,在内核中 prev_sp是内核堆栈栈顶 prev_ip是当前进程的eip / : [prev_sp] “=m” (prev->thread.sp), [prev_ip] “=m” (prev->thread.ip), //[prev_ip]是标号 “=a” (last), / clobbered output registers: */ “=b” (ebx), “=c” (ecx), “=d” (edx), “=S” (esi), “=D” (edi)
__switch_canary_oparam /* input parameters: next_sp下一个进程的内核堆栈的栈顶 next_ip下一个进程执行的起点,一般是$1f,对于新创建的子进程是ret_from_fork*/ : [next_sp] “m” (next->thread.sp), [next_ip] “m” (next->thread.ip), /* regparm parameters for __switch_to(): */ [prev] “a” (prev), [next] “d” (next) __switch_canary_iparam /* reloaded segment registers */ “memory”); } while (0)
内核在switch_to中执行如下操作:
1.进程切换, 即esp的切换, 由于从esp可以找到进程的描述符
2.硬件上下文切换, 设置ip寄存器的值, 并jmp到__switch_to函数
3.堆栈的切换, 即ebp的切换, ebp是栈底指针, 它确定了当前用户空间属于哪个进程
通过系统调用,用户空间的应用程序就会进入内核空间,由内核代表该进程运行于内核空间,这就涉及到上下文的切换,用户空间和内核空间具有不同的地址映射,通用或专用的寄存器组,而用户空间的进程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回到用户空间继续执行,所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
