实用爬虫-03-爬取视频教程课程名+链接+下载图片
实用爬虫-03-爬取视频教程课程名+链接+下载图片
很长时间不写爬虫的学习笔记了,想到用爬虫来动态的更新数据,简单的搭一个页面的框架,加上爬虫获取数据,岂不是省了自己建库又有了优质的数据源
当然我们写爬虫不能过分的爬取,有些涉及原创的东西,最好不好私自爬取,好,政治正确哈
一、爬虫的目的:
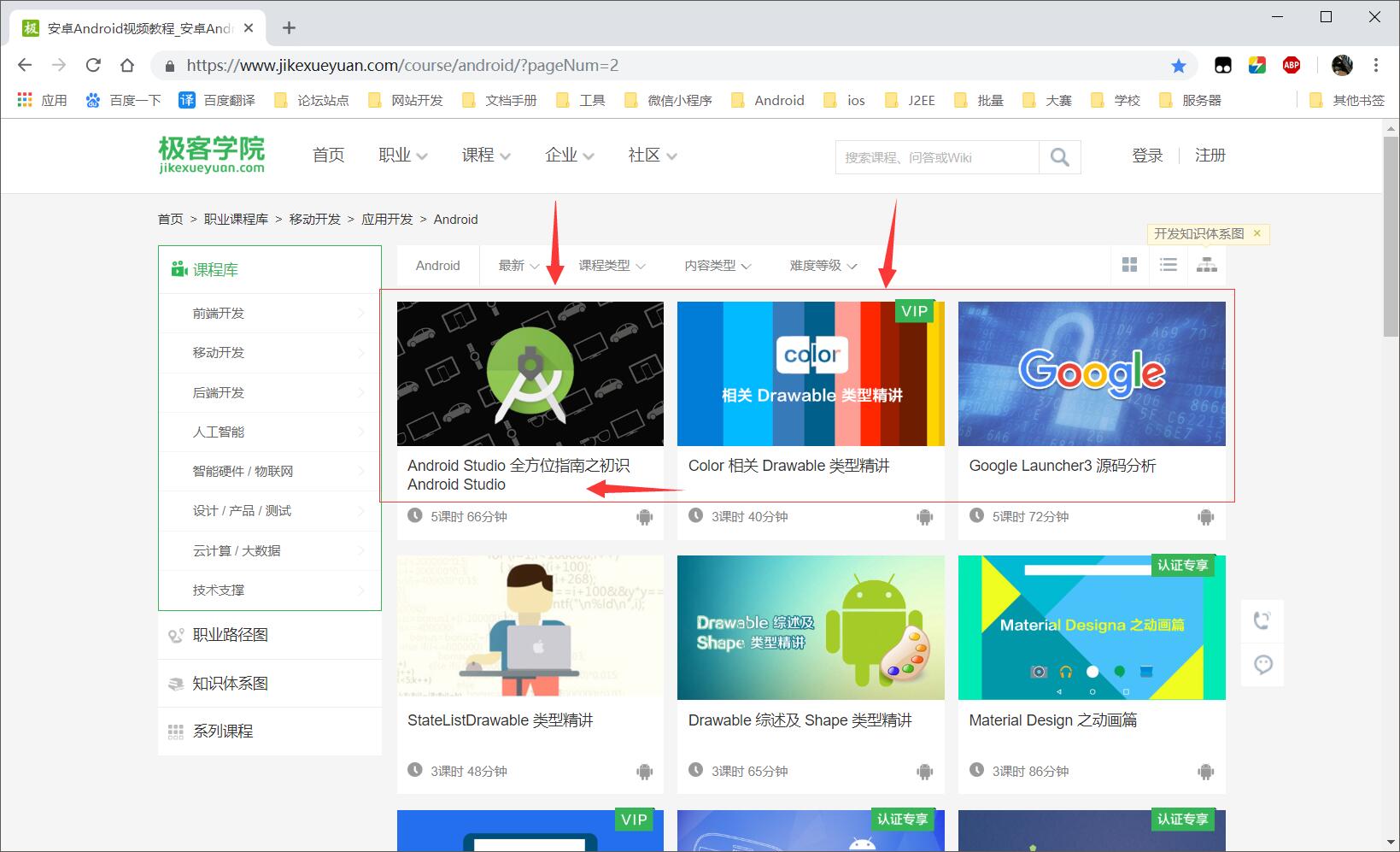
二、注意事项:
下载图片,我是放在了 pic 目录下,需要自己创建和 Python 文件同级的目录
三、不多说,在注释上聊:
# coding:utf-8
'''
使用爬虫获取教程网站信息:
1.获取课程视频连接
2.获取课程名
3.获取图片连接,并下载图片
作者:cnblogs.com/xpwi
'''
import re, requests
# 目标地址
url = "https://www.jikexueyuan.com/course/android/?pageNum=2"
if __name__ == '__main__':
# 获取页面 html
html = requests.get(url).text
# print(html)
# 获取 title
title = re.findall("<title>(.*?)</title>", html)
print(title[0])
# 获取24门课程的链接
h2 = re.findall('<h2 class="lesson-info-h2">(.*?)</h2>', html)
h2_a = ""
for i in h2:
# 因为正则获取到的是一个数组,把每个元素合起来到一个长字符串中
h2_a = h2_a + i
name = re.findall('">(.*?)</a>', h2_a)
href = re.findall('href="//(.*?)" ',h2_a)
# print("--------课程名称-------------")
# for i in name:
# print(i)
# print("--------课程链接-------------")
# for i in href:
# print(i)
i = 0
for i in range(0, len(name)):
print('课程名:' + name[i] + '\n课程连接:' + href[i])
# 获取24张图片的链接
img_href = re.findall('<img src="(.*?)"',html)
print("--------下载图片-------------")
i = 0
for m in img_href:
# 由于没有精确匹配,并不是所有连接都是我们要的课程的连接,排出第一张图片
if m == '//e.jikexueyuan.com/headerandfooter/images/logo.png?t=1513326254000':
continue
print('正在下载:' + m)
# 爬取每个网页图片的连接
pic = requests.get(m)
# 打开 pic 同级目录【必须手动创建好】
fp = open('pic\\' + str(i) + '.jpg', 'wb')
# 写入本地文件
fp.write(pic.content)
# 目前没有想到更好的方式,暂时只能写一次,关闭一次,如果有更好的欢迎讨论
fp.close()
i += 1
四、运行结果:
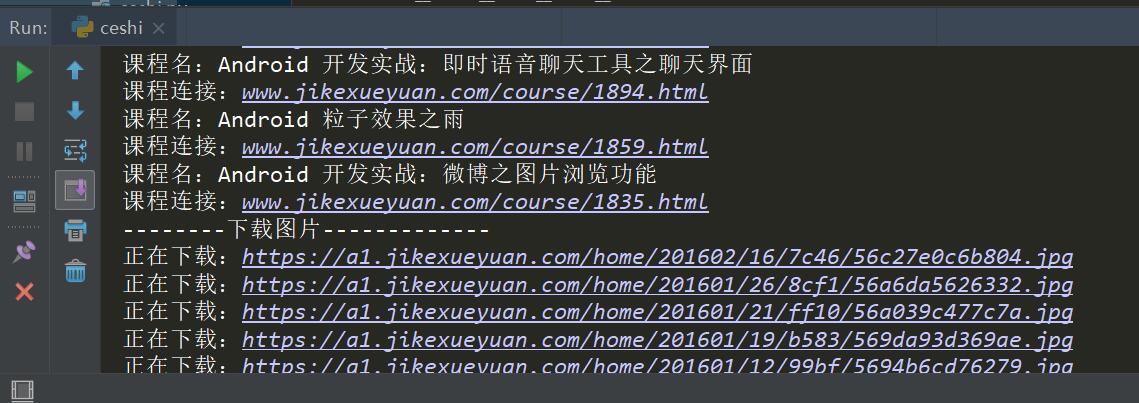
图片截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号