Python爬虫编程常见问题解决方法
Python爬虫编程常见问题解决方法:
1.通用的解决方案:
【按住Ctrl键不送松】,同时用鼠标点击【方法名】,查看文档
2.TypeError: POST data should be bytes, an iterable of bytes, or a file object. It cannot be of type str.
问题描述:【类型错误】就是数据的类型应该是bytes类型,而不是str类型
解决方案:
data = data.encode('utf-8')
3.爬取得到的HTML在一行显示
调试步骤:通过print(type(html))查看html的类型, 可以查出是bytes类型,就需要解码
解决方案:
html = html.decode()
4.有时候使用爬虫会被网站封了IP,所以需要去模拟浏览器
解决方案:
header = {"User-Agent": "mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"}
req = request.Request(url=base_url,data=bytes(data,encoding='utf-8'),headers=header)
5.当服务器返回json格式的数据乱码
调试步骤:
1.通过print(type(json_data))查看数据的类型,
2.可以查出是str类型,就是说返回的字符串中有bytes类型的数据
解决方案:把json字符串转换为字典
json_data = json.loads(json_data)
6.怎么只输出json数据的value或者某个key对应的value,不要[{}]
问题描述: 想要jsonkey/value的一部分
典型案例:
例如:
json_data=
{'errno': 0,
'data': [{'k': 'good',
'v': 'adj. 好的;'
},
{'k': 'good morning',
'v': 'int. 早安;'
}
]
}
要求: 只想要输出good: adj. 好的,而不要其他的格式
1.可以通过json_data['data'],只输出json数据json_data中‘data’对应的值,也就是
[{'k': 'good',
'v': 'adj. 好的;'
},
{'k': 'good morning',
'v': 'int. 早安;'
}
]
2.遍历输出每个'k'和'v'的值
# 遍历输出每个'k'和'v'的值
for item in json_data['data']:
print(item['k'], ": ", item['v'])
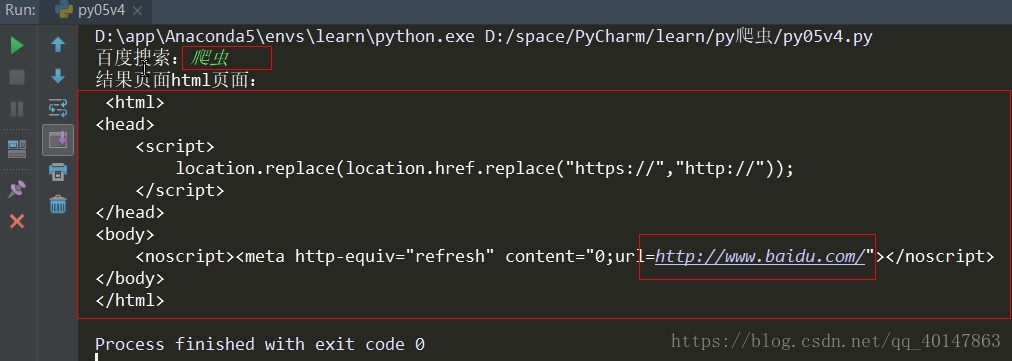
7.返回的页面是一个链接,而不是链接的页面
问题描述: 百度搜索,我们输入搜索内容,返回的是一个包括原地址链接的html,而不是访问该链接 的html,且返回的html中:location.replace(location.href.replace("https://","http://"));
问题实例截图:
解决方案: 如果使用的是http改成https,
如果使用的是https改成http,就可以了
我的爬虫笔记
- Python爬虫教程-01-爬虫介绍
- Python爬虫教程-02-使用urlopen
- Python爬虫教程-03-使用 chardet 检测编码
- Python爬虫教程-04-response简介
- Python爬虫教程-05-python爬虫实现百度翻译
- Python爬虫教程-06-爬虫实现百度翻译(requests)
- Python爬虫教程-07-post介绍(百度翻译)(上)
- Python爬虫教程-08-post介绍(百度翻译)(下)
- Python爬虫教程-09-error 模块
- Python爬虫教程-10-UserAgent和常见浏览器UA值
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
- Python爬虫教程-12-爬虫使用cookie爬取登录后的页面(人人网)(上)
- Python爬虫教程-13-爬虫使用cookie爬取登录后的页面(人人网)(下)
- Python爬虫教程-14-爬虫使用filecookiejar保存cookie文件(人人网)
- Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)
- Python爬虫教程-16-破解js加密实例(有道在线翻译)
- Python爬虫教程-17-ajax爬取实例(豆瓣电影)
- Python爬虫教程-18-页面解析和数据提取
- Python爬虫教程-19-数据提取-正则表达式(re)
- Python爬虫教程-20-xml简介
- Python爬虫教程-21-xpath
- Python爬虫教程-22-lxml-etree和xpath配合使用
- Python爬虫教程-23-数据提取-BeautifulSoup4(一)
- Python爬虫教程-24-数据提取-BeautifulSoup4(二)
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
- Python爬虫教程-26-Selenium + PhantomJS
- Python爬虫教程-27-Selenium Chrome版本与chromedriver兼容版本对照表
- Python爬虫教程-28-Selenium 操纵 Chrome
- Python爬虫教程-29-验证码识别-Tesseract-OCR
- Python爬虫教程-30-Scrapy 爬虫框架介绍
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
- Python爬虫教程-32-Scrapy 爬虫框架项目 Settings.py 介绍
- Python爬虫教程-33-scrapy shell 的使用
- Python爬虫教程-34-分布式爬虫介绍
- 本笔记不允许任何个人和组织转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号