Python爬虫教程-23-数据提取-BeautifulSoup4(一)
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据,查看文档
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
Python爬虫教程-23-数据提取-BeautifulSoup4(一)
- Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能
- 它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序
- Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了
常用数据提取工具的比较
- 1.正则:很快,不好用,不需要安装
https://blog.csdn.net/qq_40147863/article/details/82181151 - 2.lxml:比较快,使用简单,需要安装
https://blog.csdn.net/qq_40147863/article/details/82192119 - 3.BeautifulSoup4(建议):慢,使用简单,需要安装
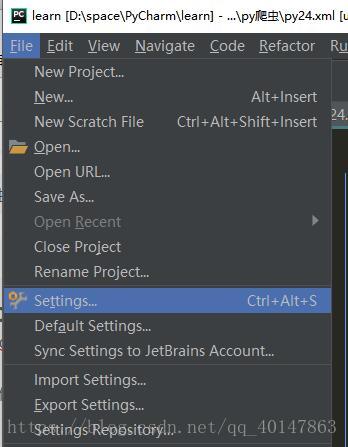
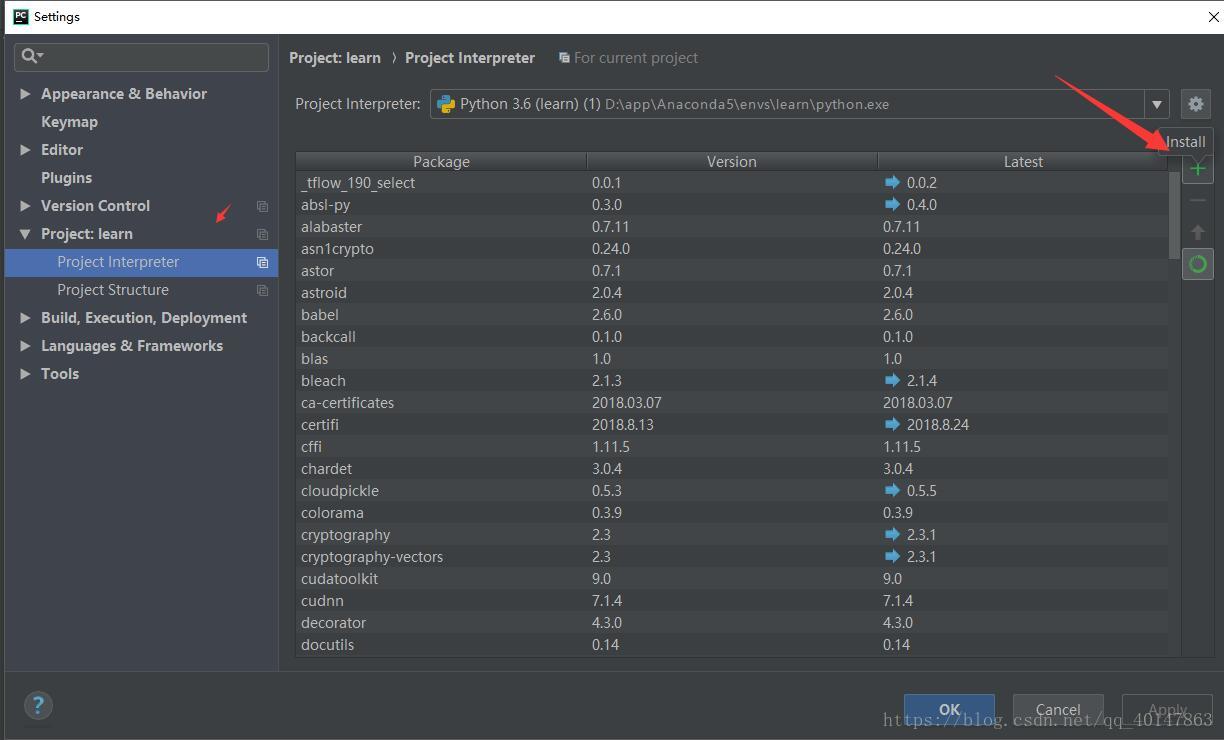
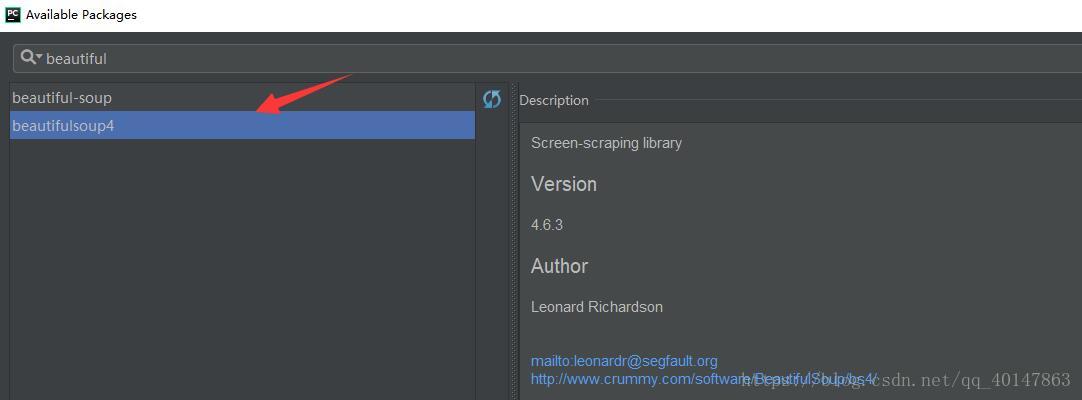
BeautifulSoup4 的安装
- 【PyCharm】>【file】>【settings】>【Project Interpreter】>【+】 >【BeautifulSoup4】>【install】
- 具体操作截图:
BeautifulSoup 的简单使用案例
- 代码27bs.py文件:https://xpwi.github.io/py/py爬虫/py27bs.py
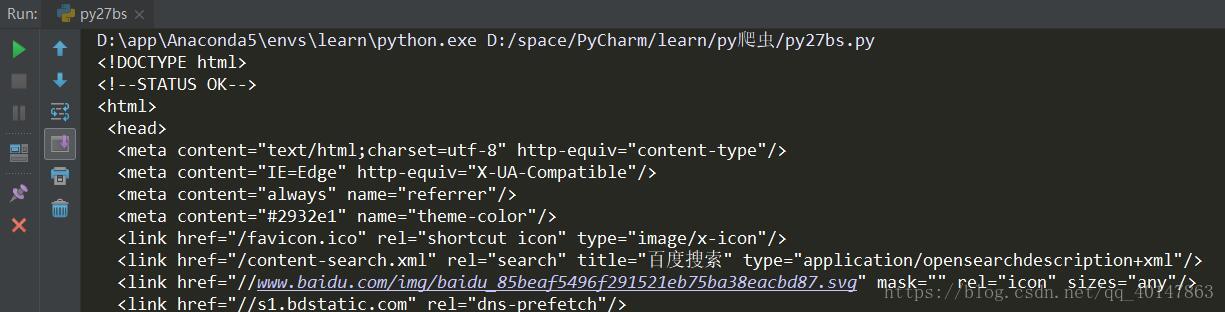
# BeautifulSoup 的使用案例
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
print(content)
运行结果
BeautifulSoup 四大对象
- 1.Tag
- 2.NavigableString
- 3.BeautifulSoup
- 4.Comment
(1)Tag
- 对应HTML中的标签
- 可以通过soup.tag_name(例如:soup.head;soup.link )
- tag 的属性:
- name :例:soup.meta.name(对应下面案例代码)
- attrs :例:soup.meta.attrs
- attrs['属性名']:例:soup.meta.attrs['content']
- 案例代码27bs2.py文件:https://xpwi.github.io/py/py爬虫/py27bs2.py
# BeautifulSoup 的使用案例
from urllib import request
from bs4 import BeautifulSoup
url = 'http://www.baidu.com/'
rsp = request.urlopen(url)
content = rsp.read()
soup = BeautifulSoup(content, 'lxml')
# bs 自动解码
content = soup.prettify()
# 虽然原文中有多个 meta 但是使用 soup.meta 只会打印出以第一个
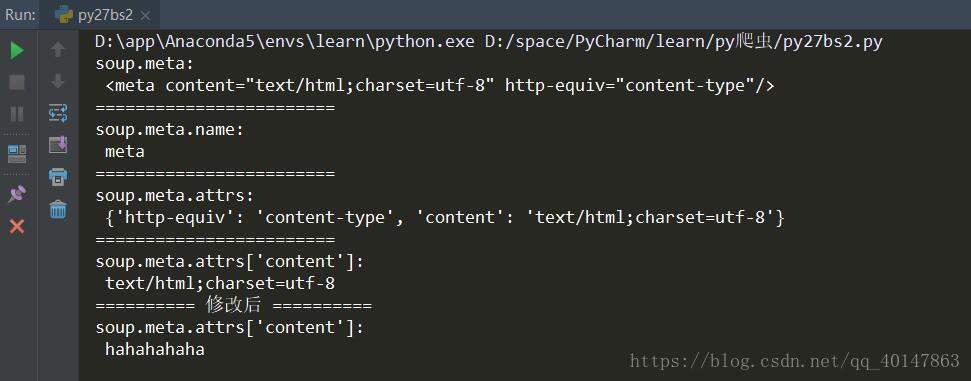
print("soup.meta:\n", soup.meta)
print("=="*12)
print("soup.meta.name:\n",soup.meta.name)
print("=="*12)
print("soup.meta.attrs:\n",soup.meta.attrs)
print("=="*12)
print("soup.meta.attrs['content']:\n",soup.meta.attrs['content'])
# 当然我们也可以对获取到的数据进行修改
soup.meta.attrs['content'] = 'hahahahaha'
print("=="*5, "修改后","=="*5)
print("soup.meta.attrs['content']:\n",soup.meta.attrs['content'])
运行结果
这里结果我们看到,只有一个 meta 标签,而源文档有多个,不是出错,而是这里使用 soup.meta 这种方式,只会打印出以第一个,也就是说数据提取时,1次匹配成功即退出
怎样打印多个 meta 标签呢?使用遍历的方式,具体代码写在下一篇
(2)NavigableString
- 对应内容值
(3)BeautifulSoup
- 表示的是一个文档的内容,大部分可以把它当做 tag 对象
- 不常用
(4)Comment
- 特殊类型的 NavigableString 对象
- 对其输出,则内容不包括注释符号
本篇就介绍到这里了,剩下的写在下一篇
拜拜
- 本笔记不允许任何个人和组织转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号