Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)
Python爬虫教程-15-爬虫读取cookie(人人网)和SSL(12306官网)
上一篇写道关于存储cookie文件,本篇介绍怎样读取cookie文件
cookie的读取
# 读取cookie文件
from urllib import request,parse
from http import cookiejar
# 创建cookiejar的实例
cookie = cookiejar.MozillaCookieJar()
cookie.load('py15renrenCookie.txt', ignore_discard=True, ignore_expires=True)
# 常见cookie的管理器
cookie_handler = request.HTTPCookieProcessor(cookie)
# 创建http请求的管理器
http_handler = request.HTTPHandler()
# 生成https管理器
https_handler = request.HTTPSHandler()
# 创建请求管理器
opener = request.build_opener(http_handler,https_handler,cookie_handler)
def getHomePage():
# 地址是用在浏览器登录后的个人信息页地址
url = "http://www.renren.com/967487029/profile"
# 如果已经执行login函数,则opener自动已经包含cookie
rsp = opener.open(url)
html = rsp.read().decode()
with open("py13rsp.html", "w", encoding="utf-8")as f:
# 将爬取的页面
print(html)
f.write(html)
if __name__ == '__main__':
getHomePage()
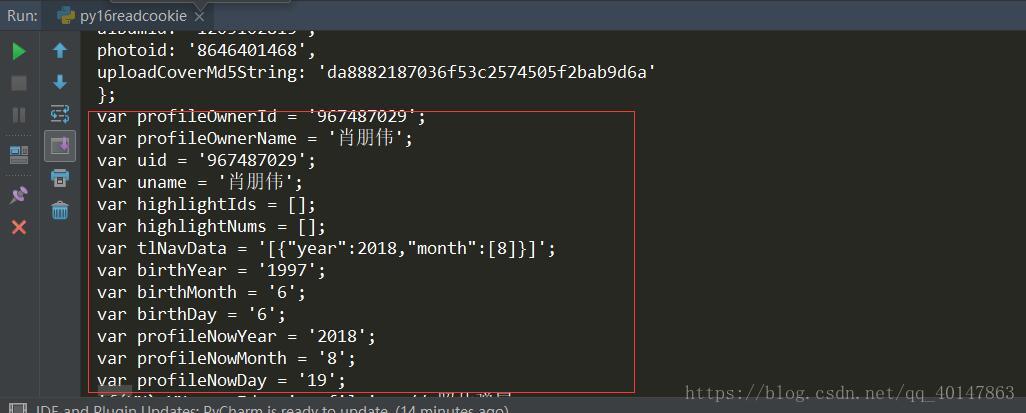
运行结果
同样是当返回页面有个人信息,才算成功!
SSL
- ssl证书就是指遵守ssl安全套阶层协议的服务器数字证书(SercureSocketLayer)
- 美国网景公司开发
- 使用ssl,加密信息
- 俗称https协议
- CA(CertificateAuthority)是数字证书任重中心,是发放,管理,废除数字证书的收信人的第三方机构
- 遇到不信任的SSL证书,需要单独处理
- 案例v17ssl文件:
'''
使用ssl
1.直接访问https://www.12306.cn/mormhweb/会无法访问,报错如下
----------------------------------
您的连接不是私密连接
攻击者可能会试图从 www.12306.cn 窃取您的信息
(例如:密码、通讯内容或信用卡信息)
-----------------------------------
2.不使用https使用http解可以访问
3.因为12306的证书是自己做的,而不是第三方机构
4.所以说http不安全会泄露个人信息
'''
from urllib import request
import ssl
# 利用非认证上下文环境替换认证的上下文环境
ssl._create_default_https_context = ssl._create_unverified_context
url = "https://www.12306.cn/mormhweb/"
rsp = request.urlopen(url)
html = rsp.read().decode()
print(html)
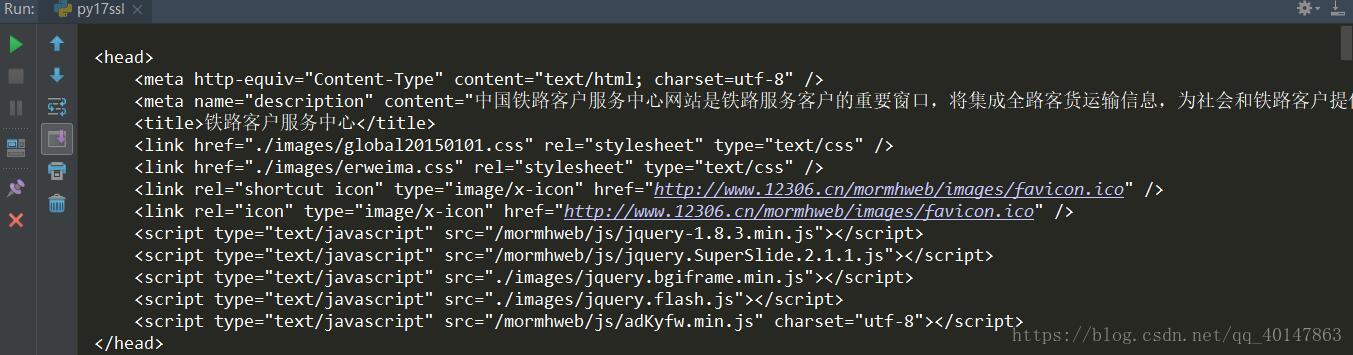
运行结果
不是报错页面,表示使用成功
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号