


Using MySQL as a NoSQL - A story for exceeding 750,000 qps on a commodity server[转载]
UPDATE: Oracle officially released memcached daemon plugin that talks with InnoDB. I'm glad to see that NoSQL+MySQL has become an official solution. It's still preview release but will be very promising. Let's try it to make it better!
Most of high scale web applications use MySQL + memcached. Many of them use also NoSQL like TokyoCabinet/Tyrant. In some cases people have dropped MySQL and have shifted to NoSQL. One of the biggest reasons for such a movement is that it is said that NoSQL performs better than MySQL for simple access patterns such as primary key lookups. Most of queries from web applications are simple so this seems like a reasonable decision.
Like many other high scale web sites, we at DeNA(*) had similar issues for years. But we reached a different conclusion. We are using "only MySQL". We still use memcached for front-end caching (i.e. preprocessed HTML, count/summary info), but we do not use memcached for caching rows. We do not use NoSQL, either. Why? Because we could get much better performance from MySQL than from other NoSQL products. In our benchmarks, we could get 750,000+ qps on a commodity MySQL/InnoDB 5.1 server from remote web clients. We also have got excellent performance on production environments.
Maybe you can't believe the numbers, but this is a real story. In this long blog post, I'd like to share our experiences.
(*) For those who do not know.. I left Oracle in August 2010. Now I work at DeNA, one of the largest social game platform providers in Japan.
Is SQL really good for fast PK lookups?
How many times do you need to run PK lookups per second? Our applications at DeNA need to execute lots of PK lookups, such as fetching user info by user id, fetching diary info by diary id. memcached and NoSQL certainly fit very well for such requirements. When you run simple multi-threaded "memcached get" benchmarks, you can probably execute 400,000+ get operations per second, even though memcached clients are located on remote servers. When I tested with the latest libmemcached and memcached, I could get 420,000 get per sec on a 2.5GHz x 8 core Nehalem box with a quad-port Broadcom Gigabit Ethernet card.
How frequently can MySQL execute PK lookups? Benchmarking is easy. Just run concurrent queries from sysbench, super-smack, mysqlslap, etc.
[matsunobu@host ~]$ mysqlslap --query="select user_name,..
from test.user where user_id=1" \
--number-of-queries=10000000 --concurrency=30 --host=xxx -uroot
You can easily check how many InnoDB rows are read per second.
[matsunobu@host ~]$ mysqladmin extended-status -i 1 -r -uroot \
| grep -e "Com_select"
...
| Com_select | 107069 |
| Com_select | 108873 |
| Com_select | 108921 |
| Com_select | 109511 |
| Com_select | 108084 |
| Com_select | 108483 |
| Com_select | 108115 |
...
100,000+ queries per second seems not bad, but much slower than memcached. What is MySQL actually doing? From vmstat output, both %user and %system were high.
[matsunobu@host ~]$ vmstat 1
r b swpd free buff cache in cs us sy id wa st
23 0 0 963004 224216 29937708 58242 163470 59 28 12 0 0
24 0 0 963312 224216 29937708 57725 164855 59 28 13 0 0
19 0 0 963232 224216 29937708 58127 164196 60 28 12 0 0
16 0 0 963260 224216 29937708 58021 165275 60 28 12 0 0
20 0 0 963308 224216 29937708 57865 165041 60 28 12 0 0
Oprofile output told more about where CPU resources were spent.
samples % app name symbol name
259130 4.5199 mysqld MYSQLparse(void*)
196841 3.4334 mysqld my_pthread_fastmutex_lock
106439 1.8566 libc-2.5.so _int_malloc
94583 1.6498 bnx2 /bnx2
84550 1.4748 ha_innodb_plugin.so.0.0.0 ut_delay
67945 1.1851 mysqld _ZL20make_join_statistics
P4JOINP10TABLE_LISTP4ItemP16st_dynamic_array
63435 1.1065 mysqld JOIN::optimize()
55825 0.9737 vmlinux wakeup_stack_begin
55054 0.9603 mysqld MYSQLlex(void*, void*)
50833 0.8867 libpthread-2.5.so pthread_mutex_trylock
49602 0.8652 ha_innodb_plugin.so.0.0.0 row_search_for_mysql
47518 0.8288 libc-2.5.so memcpy
46957 0.8190 vmlinux .text.elf_core_dump
46499 0.8111 libc-2.5.so malloc
MYSQLparse() and MYSQLlex() are called during SQL parsing phase. make_join_statistics() and JOIN::optimize() are called during query optimization phase. These are "SQL" overhead. It's obvious that performance drops were caused by mostly SQL layer, not by "InnoDB(storage)" layer. MySQL has to do a lot of things like below while memcached/NoSQL do not neeed to do.
* Parsing SQL statements
* Opening, locking tables
* Making SQL execution plans
* Unlocking, closing tables
MySQL also has to do lots of concurrency controls. For example, fcntl() are called lots of times during sending/receiving network packets. Global mutexes such as LOCK_open, LOCK_thread_count are taken/relesed very frequently. That's why my_pthread_fastmutex_lock() were ranked #2 in the oprofile output and %system were not small.
Both MySQL development team and external community are aware of concurrency issues. Some issues have already been solved in 5.5. I'm glad to see that lots of fixes have been done so far.
But it is also important that %user reached 60%. Mutex contentions result in %system increase, not %user increase. Even though all mutex issues inside MySQL are fixed, we can not expect 300,000 queries per second.
You may be heard about HANDLER statement. Unfortunately HANDLER statement was not so much helpful to improve throughput because query parsing, opening/closing tables still be needed.
CPU efficiency is important for in-memory workloads
If little active data fit in memory, SQL overheads become relatively negligible. This is simply because disk i/o costs are much much higher. We do not need to care so much about SQL costs in this case.
But, on some of our hot MySQL servers, almost all data fit in memory and they became completely CPU bound. Profiling results were similar to what I described above: SQL layer spent most of resources. We needed to execute lots of primary key lookups(i.e. SELECT x FROM t WHERE id=?) or limited range scans. Even though 70-80% of queries were simple PK lookups from the same table (difference was just values in WHERE), every time MySQL had to parse/open/lock/unlock/close, which seemed not efficient for us.
Have you heard about NDBAPI?
Is there any good solution to reduce CPU resources/contentions around SQL layer in MySQL? If you are using MySQL Cluster, NDBAPI would be the best solution. When I worked at MySQL/Sun/Oracle as a consultant, I had seen lots of customers who were dissapointed at SQL Node + NDB performance, then became happy after they could get N times bettern performance by writing NDBAPI clients. You can use both NDBAPI and SQL in MySQL Cluster. It's recommended using NDBAPI for frequent access patterns, and using SQL + MySQL + NDB for ad-hoc or infrequent query patterns.
This was what we wanted. We wanted faster access APIs, but we also wanted to use SQL for ad-hoc or complex queries. But DeNA is using InnoDB, like many other web services. Switching to NDB is not trivial. Embedded InnoDB does neither support SQL nor network interface so it's not an option for us.
Developing "HandlerSocket Plugin" - a MySQL plugin that speaks NoSQL network protocols
We thought that the best approach was implementing a NoSQL network server inside MySQL. That is, writing a network server as a MySQL plugin (daemon plugin) which listens on specific ports, accepting NoSQL protocols/APIs, then accessing to InnoDB directly by using MySQL internal storage engine APIs. This approach is similar to NDBAPI, but it can talk with InnoDB.
This concept was initially invented and prototyped by Kazuho Oku at Cybozu Labs last year. He wrote MyCached UDF that speaks memcached protocols. My colleague Akira Higuchi implemented another plugin: HandlerSocket. The below picture shows about what Hanldersocket can do.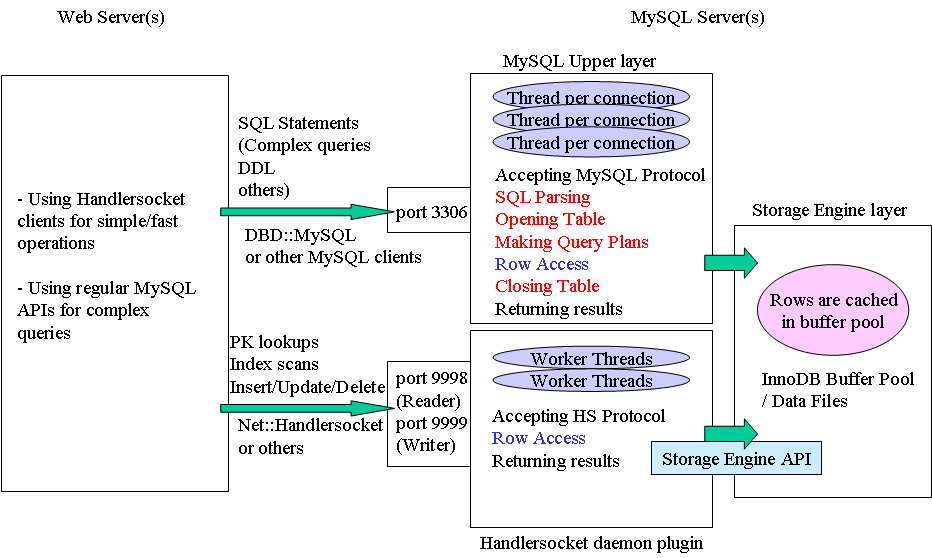
< Fig 1 > What is Hanldersocket?
HandlerSocket is a MySQL daemon plugin so that applications can use MySQL like NoSQL. The biggest purpose of the HandlerSocket is that it talks with storage engines like InnoDB without SQL-related overheads. To access MySQL tables, of course HandlerSocket needs to open/close tables. But HandlerSocket does not open/close tables every time. It keeps tables opened for reuse. Opening/closing tables is very costly and causes serious mutex contentions so it's very helpful to improve performance. Of course HandlerSocket closes tables when traffics become small etc so that it won't block administrative commands (DDL) forever.
What is different from using MySQL + memcached? By comparing Fig 1 with Fig 2, I think you'll notice lots of differences. Fig 2 shows typical memcached and MySQL usage. memcached is aggressively used for caching database records. This is mainly because memcached get operation is much faster than in-memory / on-disk PK lookups in MySQL. If HandlerSocket can fetch records as fast as memcached, we don't need memcached for caching records.
< Fig 2 > Common architecture pattern for MySQL + memcached
Using HandlerSocket
As an example, here is a "user" table. Suppose we need to fetch user information by user_id.
CREATE TABLE user (
user_id INT UNSIGNED PRIMARY KEY,
user_name VARCHAR(50),
user_email VARCHAR(255),
created DATETIME
) ENGINE=InnoDB;
In MySQL, fetching user info can be done by, of course, SELECT statements.
mysql> SELECT user_name, user_email, created FROM user WHERE user_id=101;
+---------------+-----------------------+---------------------+
| user_name | user_email | created |
+---------------+-----------------------+---------------------+
| Yukari Takeba | yukari.takeba@dena.jp | 2010-02-03 11:22:33 |
+---------------+-----------------------+---------------------+
1 row in set (0.00 sec)
Let me show how we can do the same thing with HandlerSocket.
* Installing HandlerSocket
Installation steps are described here. Basic steps are as below:
1. Download HandlerSocket here
2. Building HandlerSocket (both client and server codes)
./configure --with-mysql-source=... --with-mysql-bindir=... ; make; make install
3. Installing HandlerSocket into MySQL
mysql> INSTALL PLUGIN handlersocket soname 'handlersocket.so';
Since HandlerSocket is a MySQL plugin, you can use it like other plugins such as InnoDB Plugin, Q4M, Spider, etc. That is, you do not need to modify MySQL source code itself. MySQL version has to be 5.1 or later. You need both MySQL source code and MySQL binary to build HandlerSocket.
* Writing HandlerSocket client code
We provice C++ and Perl client libraries. Here is a sample Perl code to fetch a row by pk lookup.
- #!/usr/bin/perl
- use strict;
- use warnings;
- use Net::HandlerSocket;
- #1. establishing a connection
- my $args = { host => 'ip_to_remote_host', port => 9998 };
- my $hs = new Net::HandlerSocket($args);
- #2. initializing an index so that we can use in main logics.
- # MySQL tables will be opened here (if not opened)
- my $res = $hs->open_index(0, 'test', 'user', 'PRIMARY',
- 'user_name,user_email,created');
- die $hs->get_error() if $res != 0;
- #3. main logic
- #fetching rows by id
- #execute_single (index id, cond, cond value, max rows, offset)
- $res = $hs->execute_single(0, '=', [ '101' ], 1, 0);
- die $hs->get_error() if $res->[0] != 0;
- shift(@$res);
- for (my $row = 0; $row < 1; ++$row) {
- my $user_name= $res->[$row + 0];
- my $user_email= $res->[$row + 1];
- my $created= $res->[$row + 2];
- print "$user_name\t$user_email\t$created\n";
- }
- #4. closing the connection
- $hs->close();
The above code fetches user_name, user_email and created columns from user table, looking by user_id=101. So you'll get the same results as the above SELECT statement.
[matsunobu@host ~]$ perl sample.pl
Yukari Takeba yukari.takeba@dena.jp 2010-02-03 11:22:33
For most web applications, it's a good practice to keep lightweight HandlerSocket connections established (persistent connections), so that lots of requests can focus on main logic (the #3 in the above code).
HandlerSocket protocol is a small-sized text based protocol. Like memcached text protocol, you can use telnet to get rows through HandlerSocket.
[matsunobu@host ~]$ telnet 192.168.1.2 9998
Trying 192.168.1.2...
Connected to xxx.dena.jp (192.168.1.2).
Escape character is '^]'.
P 0 test user PRIMARY user_name,user_email,created
0 1
0 = 1 101
0 3 Yukari Takeba yukari.takeba@dena.jp 2010-02-03 11:22:33
(Green lines are request packets, fields must be separated by TAB)
Benchmarking
Now it's good time to show our benchmarking results. I used the above user table, and tested how many PK lookup operations can be done from multi-threaded remote clients. All user data fit in memory (I tested 1,000,000 rows). I also tested memcached with similar data (I used libmemcached and memcached_get() to fetch a user data). In MySQL via SQL tests, I used a traditional SELECT statement: "SELECT user_name, user_email, created FROM user WHERE user_id=? ". Both memcached and HandlerSocket client codes were written in C/C++. All client programs were located on remote hosts, connecting to MySQL/memcached via TCP/IP.
The highest throughput was as follows:
approx qps server CPU util
MySQL via SQL 105,000 %us 60% %sy 28%
memcached 420,000 %us 8% %sy 88%
MySQL via HandlerSocket 750,000 %us 45% %sy 53%
MySQL via HandlerSocket could get over 7.5 times higher throughput than traditional MySQL via SQL statements, even though %us was 3/4. This shows that SQL-layer in MySQL is very costly and skipping the layer certainly improves performance dramatically. It is also interesting that MySQL via HandlerSocket was 178% faster than memcached, and memcached spent too much %system resources. Though memcached is an excellent product, there are still rooms for optimizations.
The below is oprofile outputs, gathered during MySQL via HandlerSocket tests. CPU resources were spent on core operations such as network packets handling, fetching rows, etc (bnx2 is a network device driver program).
samples % app name symbol name
984785 5.9118 bnx2 /bnx2
847486 5.0876 ha_innodb_plugin.so.0.0.0 ut_delay
545303 3.2735 ha_innodb_plugin.so.0.0.0 btr_search_guess_on_hash
317570 1.9064 ha_innodb_plugin.so.0.0.0 row_search_for_mysql
298271 1.7906 vmlinux tcp_ack
291739 1.7513 libc-2.5.so vfprintf
264704 1.5891 vmlinux .text.super_90_sync
248546 1.4921 vmlinux blk_recount_segments
244474 1.4676 libc-2.5.so _int_malloc
226738 1.3611 ha_innodb_plugin.so.0.0.0 _ZL14build_template
P19row_prebuilt_structP3THDP8st_tablej
206057 1.2370 HandlerSocket.so dena::hstcpsvr_worker::run_one_ep()
183330 1.1006 ha_innodb_plugin.so.0.0.0 mutex_spin_wait
175738 1.0550 HandlerSocket.so dena::dbcontext::
cmd_find_internal(dena::dbcallback_i&, dena::prep_stmt const&,
ha_rkey_function, dena::cmd_exec_args const&)
169967 1.0203 ha_innodb_plugin.so.0.0.0 buf_page_get_known_nowait
165337 0.9925 libc-2.5.so memcpy
149611 0.8981 ha_innodb_plugin.so.0.0.0 row_sel_store_mysql_rec
148967 0.8943 vmlinux generic_make_request
Since MySQL via HandlerSocket runs inside MySQL and goes to InnoDB, you can get statistics from regular MySQL commands such as SHOW GLOBAL STATUS. It's worth to see 750,000+ Innodb_rows_read.
$ mysqladmin extended-status -uroot -i 1 -r | grep "InnoDB_rows_read"
...
| Innodb_rows_read | 750192 |
| Innodb_rows_read | 751510 |
| Innodb_rows_read | 757558 |
| Innodb_rows_read | 747060 |
| Innodb_rows_read | 748474 |
| Innodb_rows_read | 759344 |
| Innodb_rows_read | 753081 |
| Innodb_rows_read | 754375 |
...
Detailed specs were as follows.
Model: Dell PowerEdge R710
CPU: Nehalem 8 cores, E5540 @ 2.53GHz
RAM: 32GB (all data fit in the buffer pool)
MySQL Version: 5.1.50 with InnoDB Plugin
memcached/libmemcached version: 1.4.5(memcached), 0.44(libmemcached)
Network: Broadcom NetXtreme II BCM5709 1000Base-T (Onboard, quad-port, using three ports)
* Both memcached and HandlerSocket were network i/o bound. When I tested with a single port, I got around 260,000 qps on MySQL via HandlerSocket, 220,000 qps on memcached.
Features and Advantages of HandlerSocket
HandlerSocket has lots of features and advantages like below. Some of them are really beneficial for us.
* Supporting lots of query patterns
HandlerSocket supports PK/unique lookups, non-unique index lookups, range scan, LIMIT, and INSERT/UPDATE/DELETE. Operations that do not use any index are not supported. multi_get operations (similar to IN(1,2,3..), fetching multiple rows via single network round-trip) are also supported.
See documentation for details.
* Can handle lots of concurrent connections
HandlerSocket connection is light. Since HandlerSocket employs epoll() and worker-thread/thread-pooling architecture, the number of MySQL internal threads is limited (can be controlled by handlersocket_threads parameter in my.cnf). So you can establish thousands or tens of thousands of network connections to HandlerSocket, without losing stability(consuming too much memory, causing massive mutex contentions, etc: such as bug#26590, bug#33948,bug#49169).
* Extremely high performance
HandlerSocket is possible to gain competitive enough performance against other NoSQL lineups, as already described. Actually I have not seen any NoSQL product that can execute 750,000+ queries on a commodity server from remote clients via TCP/IP.
Not only HandlerSocket eliminates SQL related function calls, but also it optimizes around network/concurrency issues.
** Smaller network packets
HandlerSocket protocol is much simpler and smaller than normal MySQL protocols. So overall network transfer size can be much smaller.
** Running limited number of MySQL internal threads
See above.
** Grouping client requests
When lots of concurrent requests come to HandlerSocket, each worker thread gathers as many requests as possible, then executing gathered requests at one time, and sending back results. This can improve performance greatly, by sacrificing response time a bit. For example, you can gain the following benefits. I'll explain them in depth in later posts, if anybody is interested.
*** Can reduce the number of fsync() calls
*** Can reduce replication delay
* No duplicate cache
When you use memcached to cache MySQL/InnoDB records, records are cached in both memcached and InnoDB buffer pool. They are duplicate so less efficient (Memory is still expensive!). Since HandlerSocket plugin accesses to InnoDB storage engine, records are cached inside InnoDB buffer pool, which can be reused by other SQL statements.
* No data inconsistency
Since data is stored at one place (inside InnoDB), data consistency check between memcached and MySQL is not needed.
* Crash-safe
Backend storage is InnoDB. It's transactional and crash safe. Even though you use innodb-flush-log-at-trx-commit!=1, you lose only < 1s of data on server crash.
* SQL can be used from mysql clients
In many cases people still want to use SQL (i.e to generate summary reports). This is why we can't use Embedded InnoDB. Most NoSQL products don't support SQL interface, either.
HandlerSocket is just a plugin for MySQL. You can usually send SQL statements from MySQL clients, and use HandlerSocket protocols when you need high throughput.
* All operational benefits from MySQL
Again, HandlerSocket runs inside MySQL, so all MySQL operations such as SQL, online backups, replication, monitoring by Nagios / EnterpriseMonitor, etc are supported. HandlerSocket activities can be monitored by regular MySQL command such as SHOW GLOBAL STAUTS, SHOW ENGINE INNODB STATUS, SHOW PROCESSLIST, etc.
* No need to modify/rebuild MySQL
Since it's a plugin, it runs on both MySQL Community and MySQL Enterprise Servers.
* Independent from storage engines
HandlerSocket is developed so that it can talk with any storage engine, though we have tested and used with 5.1 and 5.5 InnoDB Plugin only.
Notes and Limitations
* Need to learn HandlerSocket APIs
You need to write a program to talk with HandlerSocket, though it's pretty easy to use. We provide C++ API and Perl bindings.
* No security
Like other NoSQL databases, HandlerSocket does not provide any security feature. HandlerSocket's worker threads run with system user privileges, so applications can access to all tables through HandlerSocket protocols. Of course you can use firewalls to filter packets, like other NoSQL products.
* No benefit for HDD bound workloads
For HDD i/o bound workloads, a database instance can not execute thousands of queries per second, which normally results in only 1-10% CPU usage. In such cases, SQL execution layer does not become bottleneck, so there is no benefit to use Hanldersocket. We use HandlerSocket on servers that almost all data fit in memory.
DeNA is using HandlerSocket in production
We already use HandlerSocket plugin in our production environments. The results are great. We could have reduced lots of memcached and MySQL slave servers. Overall network traffics have been reduced, too. We haven't seen any performance problem (slow response time, stalls etc) so far. We've been very satisfied with the results.
I think MySQL has been underrated from NoSQL/Database communities. MySQL actually has much longer history than most of other products, and lots of unique and great enhancements have been done so far by excellent my ex-colleagues. I know from NDBAPI that MySQL has very strong potentials as a NoSQL. Storage engine API and daemon plugin interface are completely unique, and they made Akira and DeNA develop HandlerSocket possible. As an ex-employee at MySQL and a long-time fun for MySQL, I'd like to see MySQL becomes better and more popular, not only as an RDBMS, but also as Yet Another NoSQL lineup.
Since HandlerSocket plugin is Open Source, feel free to try. We'd be appreciated if you give us any feedback.
原文地址:http://yoshinorimatsunobu.blogspot.com/2010/10/using-mysql-as-nosql-story-for.html

