
一、面向对象基础:
类和对象: 类是对象的抽象,对象是类的实体。
类:是对现实生活中一类具有共同属性和行为的事物的抽象
对象:是能看得到摸得着的真实存在的实体
类的特点:
类是对象的数据类型。
类是具有相同属性和行为的一组对象的集合
属性:对象具有的各种特征,每个对象的每个属性都拥有特定的值
行为:对象能够执行的操作
类的定义:
类的重要性:是Java程序的基本组成单位
类的组成,属性和行为
属性:在类中通过成员变量来体现(类方法中的变量)
行为:在类中通过成员方法来体现(和前面的方法相比去掉static关键字即可)
类的定义步骤:
1.定义类
2.编写类的成员变量
3.编写类的成员方法public class 类名 {
//成员变量
变1的数据类型 变1;
……
//成员方法
方1;
……
}
对象的使用:
创建对象
格式: 类名 对象名 = new 类名();
例: Phone p = new Phone();
使用对象:
1.使用成员变量
格式: 对象名.变量名 例:p.brand
2.使用成员方法:
格式:对象名.方法名() 例:p.call()
成员变量和局部变量
成员变量:类中方法外的变量 局部变量:方法中的变量
区别:
封装:
private关键字:
1.是一个权限修饰符
2.可以修饰成员(成员变量和成员方法)
3.作用是保护成员不被别的类使用,被private修饰的成员只在本类中才能访问
针对private修饰的成员变量,如果需要被其他类使用,提供相应的操作:
1.提供“get变量名()”方法,用于获取成员变量的值,方法用public修饰
2.提供“set变量名()”方法,用于设置成员变量的值,方法用public修饰
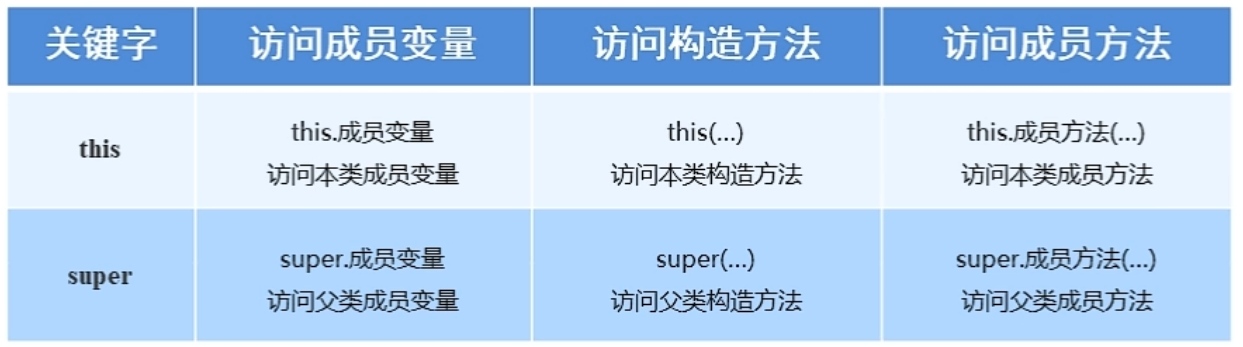
this关键字:
1.this修饰的变量用于指代成员变量
方法的形参如果与成员变量同名,不带this修饰的变量指的是形参,而不是成员变量
方法的形参没有与成员变量同名,不带this修饰的变量指的是成员变量
2.什么时候用this?
解决局部变量隐藏成员变量
3.this代表所在类的对象引用
记住:方法被哪个对象调用,this就代表哪个对象
封装概述:
是面向对象三大特征之一(封装、继承、多态)
是面向对象编程语言对客观世界的模拟,客观世界里成员变量都是隐藏在对象内部的,外界是无法直接操作的
封装原则:
将类的某些信息隐藏在类内部,不允许外部程序直接访问,而是通过该类提供的方法来是实现对隐藏信息的操作和访问成员变量private,提供对应的getXXX()/setXXX()方法
封装好处:
通过方法来控制成员变量的操作,提高了代码的安全性
把代码用方法进行封装,提高了代码的复用性
构造方法:
概述:构造方法是一种特殊的方法
作用:创建对象
格式:
public class 类名{
修饰符.类名(参数){
}
}
例如:
public class Student{
public Student(){
构造方法内书写的内容
}
}
功能:主要是完成对象数据的初始化
构造方法的注意事项:
1.构造方法的创建
如果没有定义构造方法,系统将给出一个默认的无参数构造方法
如果定义了构造方法,系统将不再提供默认的构造方法
2.构造方法的重载:
如果自定义了带参构造方法,还要使用无参数构造方法,就必须再写一个无参数构造方法
3.推荐的使用方式
无论是否使用,都手工书写无参数构造方法
标准类制作:
1.成员变量
使用private修饰
2.构造方法
提供一个无参构造方法
提供一个带多个参数的构造方法
3.成员方法
提供每一个成员变量对应的setXXX()/getXXX().
提供一个显示对象信息的show()
测试类
4.创建对象并为其成员变量赋值的两种方式
无参构造方法创建对象后使用setXXX()赋值
使用带参构造方法直接创建带有属性值的对象
API:
概述:API(Application Programming Interface):应用程序编程接口
JavaAPI:指的就是jdk中提供的各种功能的Java类
String概述:
String类在Java.lang包下,所以使用的时候不需要导包String类代表字符串,Java程序中的所有字符串文字(例如:“abc”)都被实现为此类的实例,也就是说,Java程序中所有的双引号字符串,都是String类的对象
字符串的特点:
字符串不可变,它们的值在创建后不能被更改
虽然String的值是不可变的,但是它们可以被共享
字符串效果上相当于字符数组(char[]),但是底层原理是字节数组(byte[])
String构造方法:
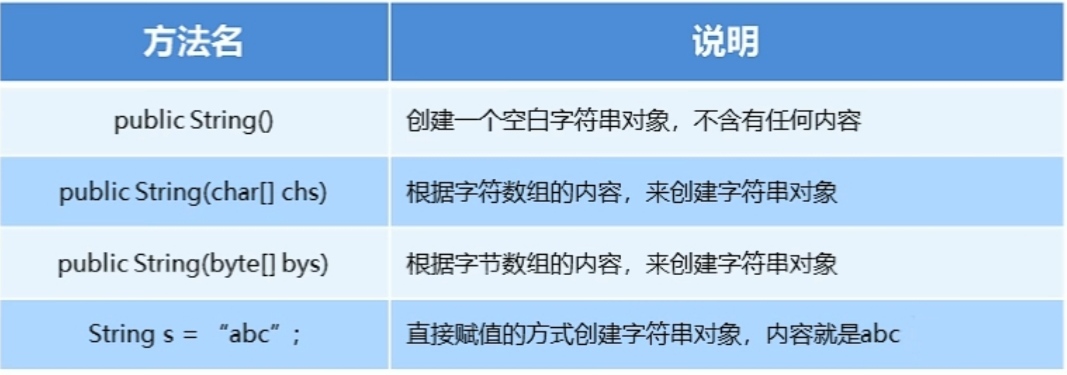
推荐使用直接赋值的方式得到字符串对象
字符串的比较:
使用==做比较
基本类型:比较的是数据值是否相同
引用类型:比较的是地址值是否相同
字符串是对象,它比较内容是否相同,是通过equals()方法实现的
StringBuilder:
概述:StringBuilder是一个可变的字符串类,我们可以把它看成是一个容器,这里的可变指的是StringBuilder对象中的内容是可变的
String:内容是不可变的
StringBuilder:内容是可变的
StringBuilder构造方法:
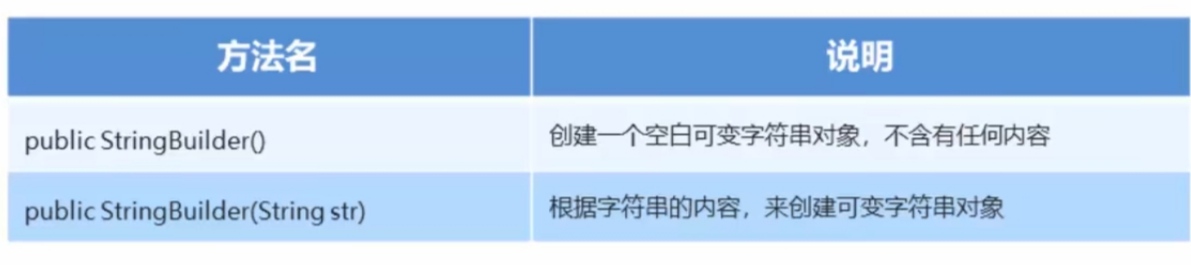
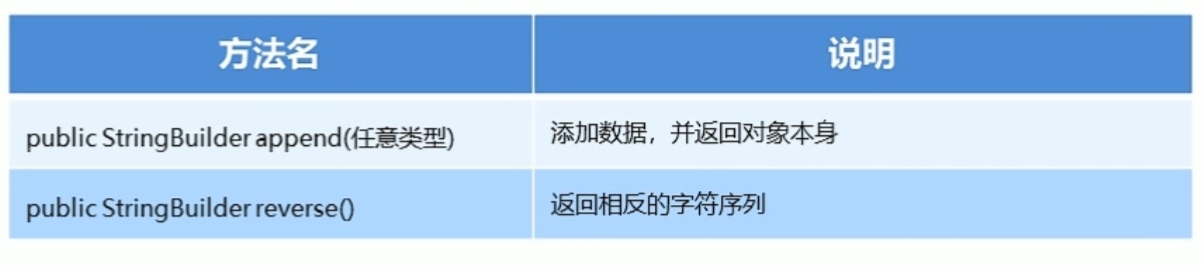
StringBuilder的添加和反转方法
StringBuilder转换为String
public String toString();通过toString()就可以实现
String转换为StringBuilder
public StringBuilder(String s);通过构造方法就可以实现
集合基础:
集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以发生改变。
集合类有很多 现在学的是: ArrayList
ArrayList<E>:
可调整大小的数组实现
<E>:是一种特殊的数据类型,泛型
ArrayList构造方法和添加方法
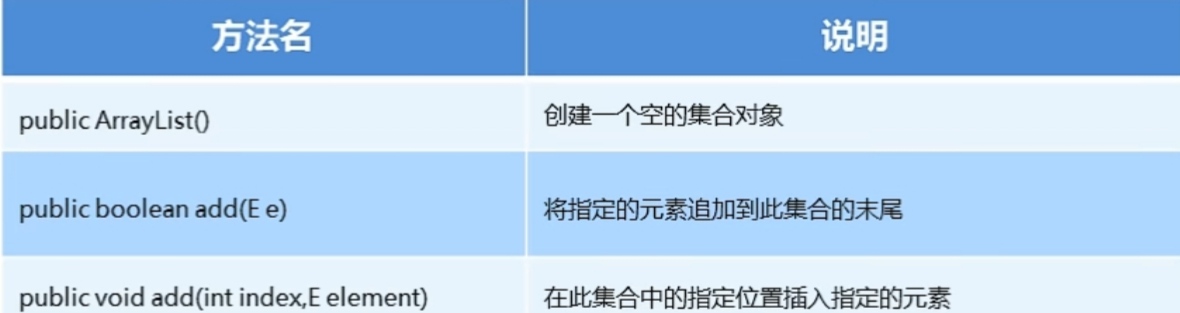
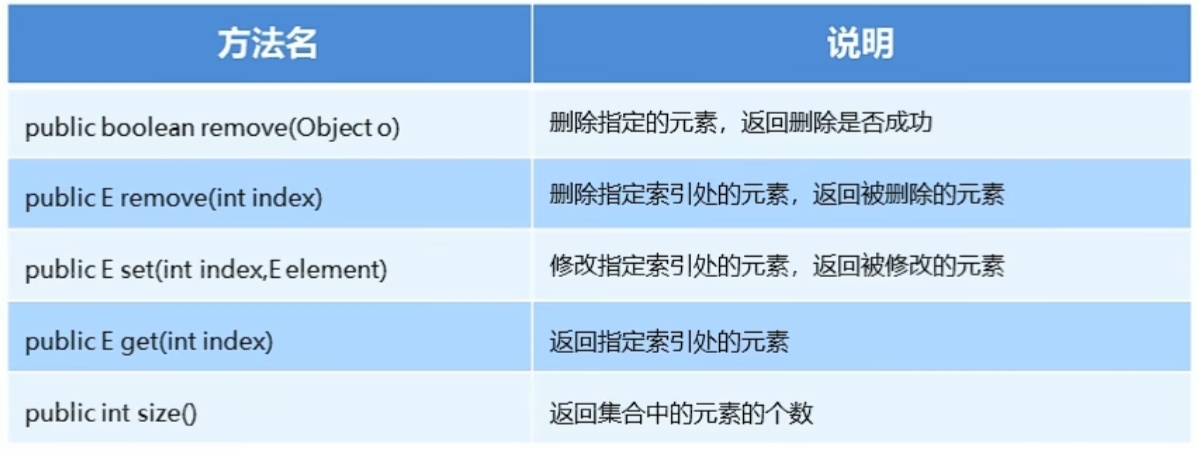
ArrayList集合常用方法:
//创建集合对象
ArrayList<String> array = new ArrayList<学生对象>();
//遍历集合的通用格式
for(int i =0; i<array.size();i++){
String s = array.get(i);
System.out.println(s);
继承:
继承是面向对象三大对象之一,可以使得子类具有父类的属性和方法,还可以在子类中重新定义,追加属性和方法
继承格式:
public class 子类名 extends 父类名{}
例如:public class Zi extends Fu{}
Fu:是父类,也被称为基类和超类
Zi:是子类,也被称为派生类
继承中子类的特点:
子类可以有父类的内容
子类还可以有自己特有的内容
继承的好处和弊端:
好处:
提高了代码的复用性(多个类相同的成员可以放到同一个类中)
提高了代码的维护性(如果方法的代码需要修改,修改一处即可)
弊端:
继承让类与类之间产生了关系,类的耦合性增强了,当父类发生变化时子类实现也不得不跟着变化,削弱了子类的独立性
什么时候使用继承?
继承体现的关系: is 啊
假设法:我有两个类A和B,如果他们满足A是B的一种,或者B是A的一种,就说明他们存在继承关系,这个时候就可以考虑使用继承来体现,否则就不能滥用继承
例如:苹果和水果、 猫和动物、 猫和狗(这个不是)
继承中变量的访问特点:
在子类方法中访问一个变量
先去子类的局部范围内找(也就是方法中寻找),再去子类成员范围内找(也就是子类中找),最后去父类成员范围内找(也就是父类中找),如果没有就报错(不考虑父亲的父亲)
super关键字:
super关键字的用法和this关键字的用法相似
this:代表本类对象的引用(this关键字指向调用该方法的对象,一般我们是在当前类中使用this关键字,so我们常说this代表本类对象的引用)
super:代表父类存储空间的标识(可以理解为父类对象引用)
构造方法中可以带有参数
继承中构造方法的访问特点:
子类中所有的构造方法默认都会访问父类中无参的构造方法
why?
因为子类会继承父类中的数据,可能还会使用父类的数据,所以,子类初始化之前,一定要先完成父类数据的初始化
每一个子类构造方法的第一条语句默认都是:super()
如果父类中没有无参构造方法,只有带参构造方法,该怎么办呢?
1.可以使用super关键字去显示的调用父类的带参构造方法
2.在父类中自己提供一个无参构造方法
推荐自己写一个无参构造方法
继承中成员方法的访问特点:
通过子类对象访问一个方法
先去子类的成员范围内找(也就是子类中寻找),再去父类成员范围内找(也就是父类中找),如果没有就报错(不考虑父亲的父亲)
方法重写
概述:子类中出现了和父类中一模一样的方法声明
方法重写的应用
当子类需要父类的功能,而功能主体子类有自己的特有内容时,可以重写父类中的方法,这样,即沿袭了父类的功能,又定义了子类特有的内容
@Override
是一个注解
可以帮助我们检查重写方法的方法声明的正确性
方法重写的两个注意事项:
私有方法不能被重写(父类私有成员子类是不能继承的)
子类方法访问权限不能更低(public > 默认 > 私有private)
Java中继承的注意事项:
Java中类只支持单继承,不支持多继承。(不能继承多个类(只能一个))
Java中类支持多层继承(可以继承爷爷类)
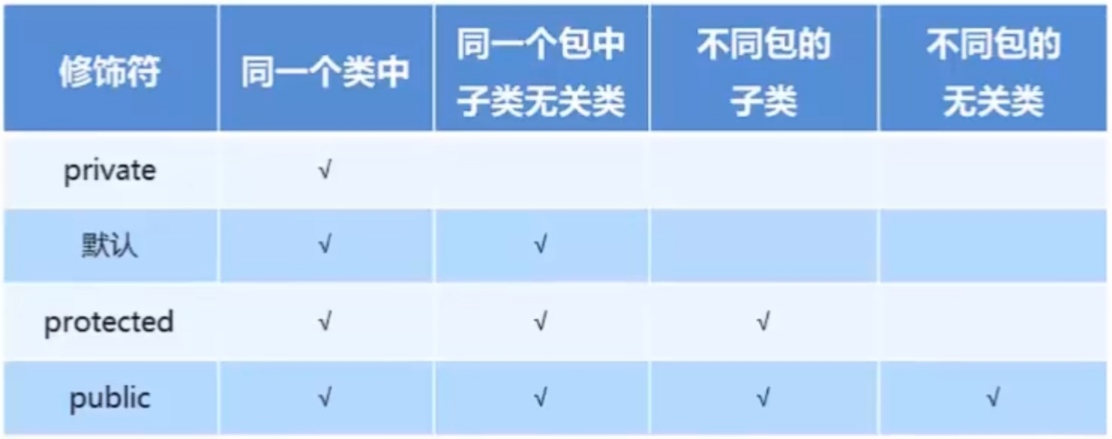
修饰符:
权限修饰符:
final:final关键字是最终的意思,可以修饰成员方法,成员变量,类
final修饰的特点:
修饰方法:表明该方法是最终方法,不能被重写
修饰变量:表明该变量是常量,不能再次赋值
修饰类:表明该类是最终类,不能被继承
final修饰局部变量:
变量是基本类型:final修饰指的是基本类型的数据值不能发生改变
变量是引用类型:final修饰指的是引用类型的地址值不能发生改变,但是地址值里面的内容可以发生改变
static关键字:
static关键字是静态的意思,可以修饰成员方法,成员变量
static修饰特点:
被类的所有对象共享
这也是我们判断是否使用静态关键字的条件
可以通过类名调用
当然,也可以通过对象名调用
推荐使用类名调用
static访问特点:
非静态的成员方法
能访问静态的成员变量
能访问非静态的成员变量
能访问静态的成员方法
能访问非静态的成员方法
静态的成员方法
能访问静态的成员变量
能访问静态的成员方法
总结:静态成员方法只能访问静态成员
多态:
概述:同一个对象,在不同时刻表现出来的不同形态
多态的前提和体现:
有继承/实现关系
有方法重写
有父类引用指向子类对象
多态中成员访问特点:
成员变量:编译看左边,执行看左边
成员方法:编译看左边,执行看右边
why不一样?
因为成员方法有重写,而成员变量没有
多态的好处和弊端:
好处:提高了程序的扩展性
具体体现:定义方法的时候,使用父类型做为参数,将来在使用的时候,使用具体的子类型参与操作
弊端:不能使用子类中特有功能
多态的转型:
向上转型:
从子到父
父类引用指向子类对象
向下转型:
从父到子
父类引用转为子类对象
抽象类:
抽象类概述:
在Java中,一个没有方法体的方法应该定义为抽象方法,而类中如果有抽象方法,该类必须定义为抽象类
抽象类特点:
抽象类和抽象方法必须使用abstract关键字修饰
public abstract class 类名()
public abstract void eat();
抽象类中不一定又抽象方法,有抽象方法的类一定是抽象类
抽象类没有使用多态就不能实例化
抽象类如何实现实例化呢?参照多态的方式,通过子类对象实例化,这叫抽象类多态
抽象类的子类
要么重写抽象类中所有抽象方法
要么是抽象类
抽象类的成员特点:
成员变量
可以是变量
也可以是常量
构造方法
有构造方法,但不能直接实例化
那么,构造方法的作用是什么呢? 是用于子类访问父类数据的初始化
成员方法
可以有抽象方法:限定子类必须完成某些动作
也可以有非抽象方法:提高代码的复用性
接口:
概述:接口就是一种公共的规范标准,只要符合规范标准,大家都可以使用
Java中的接口更多的体现在对行为的抽象
接口的特点:
接口使用关键字interface修饰
public interface 接口名{}
类实现接口用implements表示
public class 类名 implements 接口名{}
接口没有使用多态就不能实例化
参照多态的方式,通过实现类对象实例化,这叫接口多态
多态的形式:具有类多态,抽象类多态,接口多态
多态的前提:有继承或者实现关系;有方法重写;有父(类/接口)引用指向(子/实现)类对象
接口的实现类
要么重写接口中的所有抽象方法
要么是抽象类
接口的成员特点:
成员变量
只能是常量
默认修饰符:public static final
构造方法
接口没有构造方法,因为接口主要是对行为进行抽象的,是没有具体的存在
一个类如果没有父类,默认继承自Object类
成员方法
只能是抽象方法
默认修饰符:public abstract
类和接口的关系:
类和类的关系
继承关系,只能单继承,但是可以多层继承
类和接口的关系
实现关系,可以单实现,也可以多实现,还可以在继承一个类的同时实现多个接口
接口和接口的关系
继承关系,可以单继承,也可以多继承
抽象类和接口的区别:
成员区别
抽象类 变量,常量;有构造方法;有抽象方法,也有非抽象方法
接口 常量;抽象方法
关系区别
类与类 继承,单继承
类与接口 实现,也可以单实现,也可以多实现
接口与接口 继承,单继承,多继承
设计理念区别
抽象类 对类抽象,包括属性,行为
接口 对行为抽象,主要是行为
强调:抽象类是对事务的抽象,而接口是对行为的抽象
形参和返回值
类名作为形参和返回值
方法的形参是类名,其实需要的是该类的对象
方法的返回值是类名,其实返回的是该类的对象
抽象类名作为形参和返回值
方法的形参是抽象类名,其实需要的是该抽象类的子类对象
方法的返回值是抽象类名,其实返回的是该抽象类的子类对象
接口做为形参和返回值
方法的形参是接口名,其实需要的是该接口的实现类对象
方法的返回值是接口名,其实返回的是该接口的实现类对象
内部类:
概述:就是在一个类中定义一个类。举例:在一个类A的内部定义一个类B,类B就被称为内部类
内部类的定义格式:
public class 类名{
修饰符 class 类名{
}
}
范例:
public class Outer{
public class Inner{
}
}
内部类的访问特点:
内部类可以直接访问外部类的成员,包括私有
外部类要访问内部类的成员,必须创建对象
成员内部类:
按照内部类在类中定义的位置不同,可以分为如下两种形式
在类的成员位置:成员内部类
在类的局部位置:局部内部类
成员内部类,外界创建对象使用格式为(不是私有的):
外部类名.内部类名 对象名 = new 外部类对象().new 内部类对象();
例如: Outer.Inner oi = new Outer().new Inner();
注意:一般不是这么使用 而是间接调用
局部内部类:
局部内部类是在方法中定义的类,所以外界是无法直接使用的,需要在方法内部创建对象并使用
该类可以直接访问外部类成员,也可以访问方法内的局部变量
匿名内部类:
前提:存在一个类或者接口,这里的类可以是具体类也可以是抽象类
格式:
new 类名或者接口名(){
重写方法;
};
范例:
new Inter(){
public void show(){
}
}
本质:是一个继承了该类或者实现了该接口的子类匿名对象
Api:
Math类概述:
Math包含指向基本数字运算的方法
没有构造方法,如何使用类中的成员呢?
看类的成员是否都是静态的,如果是,通过类名就可以直接调用
Math类的常用方法

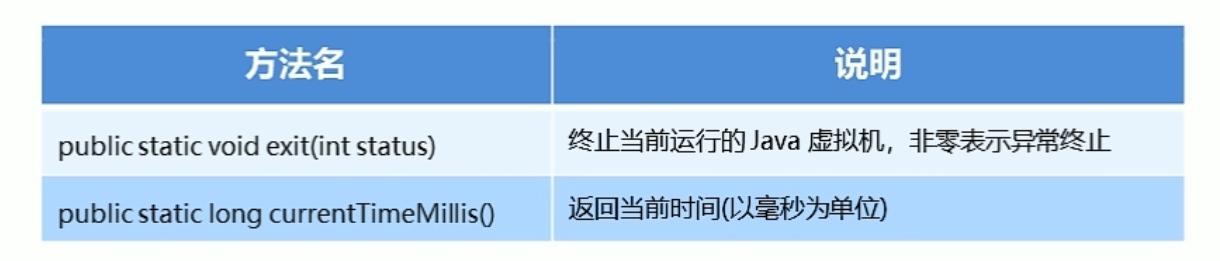
System类概述:
System包含几个有用的类字段和方法,它不能被实例化
System类的常用方法:
Object类的概述:
Object是类层次结构的根,每个类都可以将Object作为超类。所有类都直接或者间接的继承该类
构造方法: public Object()
回想面向对象中,为什么说子类的构造方法默认访问的是父类的无参构造方法?
因为它们的顶级父类中只有无参构造方法
看方法的原码:选中方法,按下Ctrl+B
Object类的常用方法

Arrays:
冒泡排序:
排序:将一组数据按照固定的规则进行排列
冒泡排序:一种排序的方式,对要进行排序的数据中相邻的数据进行两两比较,将较大的数据放在后面,依次对所有的数据
进行操作,直至所有数据按要求完成排序
如果有n个数据进行排序,总共需要比较n-1次
每一次比较完毕,下一次的比较就会少一个数据参与
Arrays类的概述和常用方法:
Arrays类包含用于操作数组的各种方法
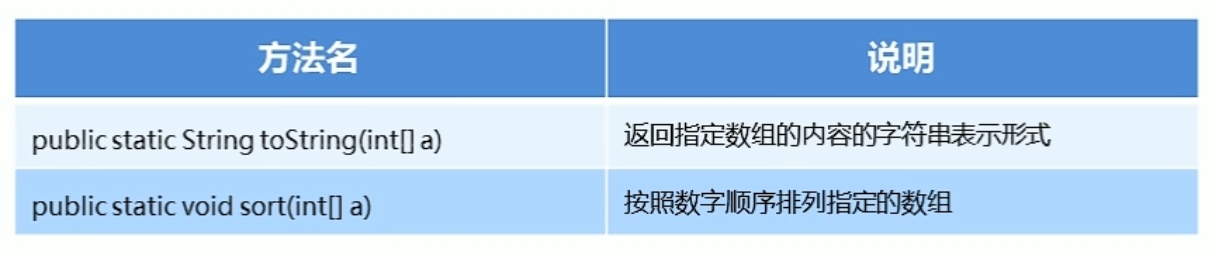
工具类的设计思想:
构造方法用private修饰
成员用public static 修饰
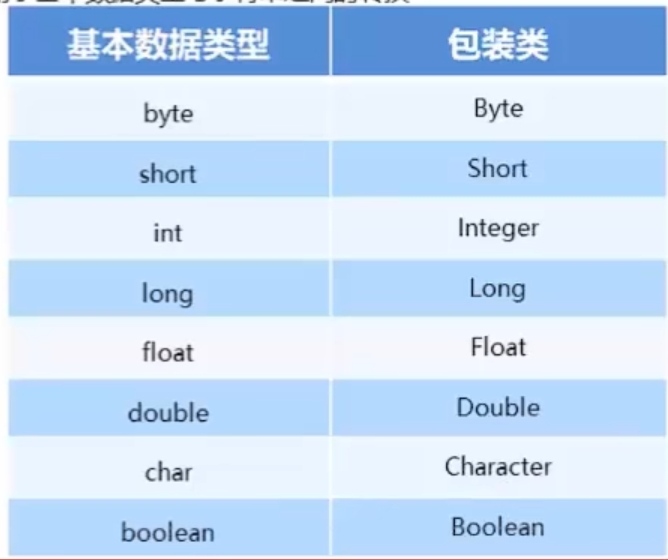
基本类型包装类:
将基本类型封装成对象的好处在于可以在对象中定义更多的功能方法操作该数据
常用的操作之一:用于基本数据类型与字符串之间的转换
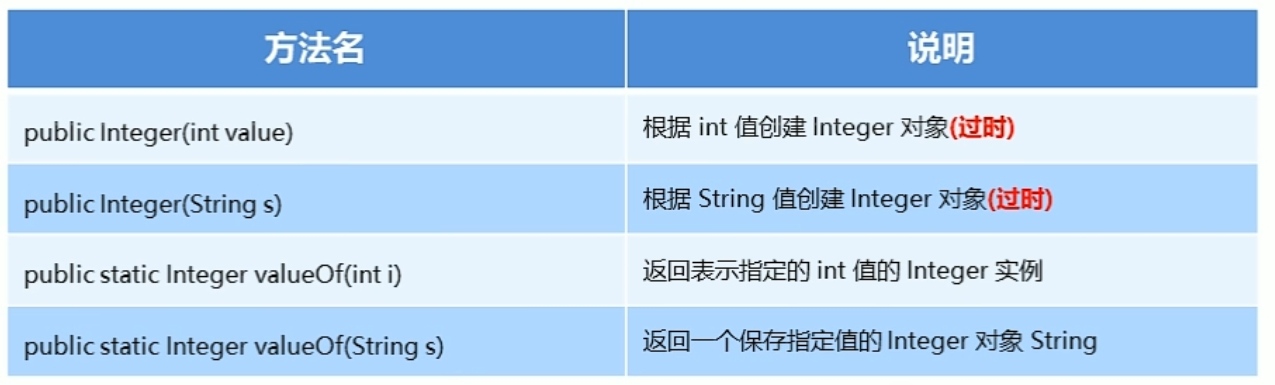
Integer类的概述和使用:
Integer:包装一个对象中的原始类型int的值
int和String的相互转换:
基本类型包装类的最常见操作就是:用于基本类型和字符串之间的相互转换
1、int转换为String
public static String valueOf(int i):返回int参数的字符串表现形式。该方法是String类中的方法
2、String转换为int
public static int parseInt(String s):将字符串解析为int类型。该方法是Integer类中的方法
自动装箱和拆箱:
装箱:把基本数据类型转换为对应的包装类类型
拆箱:把包装类类型转换为对应的基本数据类型

Date:
Date类概述和构造方法:
Date代表了一个特定的时间,精确到毫秒

Date类的常用方法

SimpleDateFormat:
SimpleDateFormat类概述:
SimpleDateFormat是一个具体的类,用于以区域设置敏感的方式格式和解析日期。我们重点学习日期格式化和解析。
日期和时间格式由日期和时间模式字符串指定,在日期和时间模式字符串中,从‘A’到‘Z’以及从‘a'到’z‘引号的字母被解释为表示日期或时间的字符串的组件的模式字母。

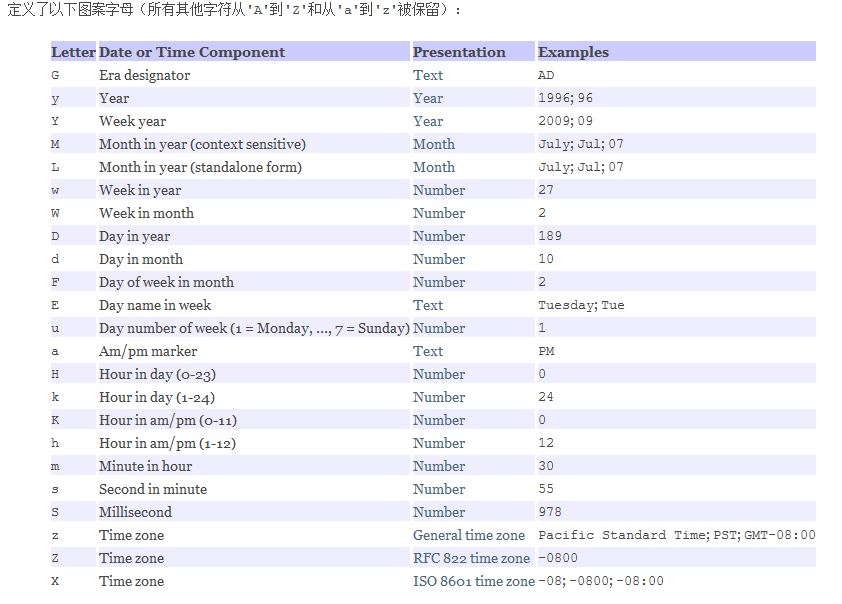
SimpleDateFormat的构造方法:

SimpleDateFormat格式化和解析日期:
1.格式化(从Date到String)
public final String format(Date date):将日期格式化成日期/时间字符串
2.解析(从String到Date)
public Date parse(String source):从给定字符串的开始解析文本以生成日期
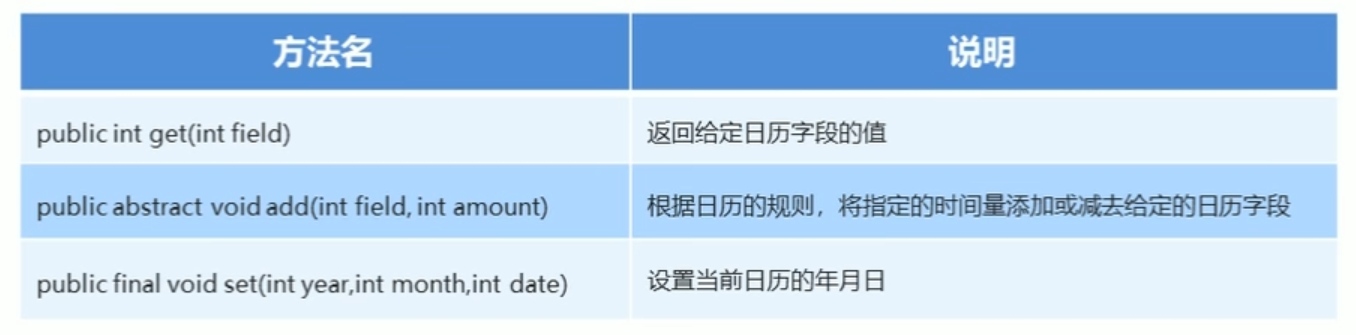
Calendar类概述:
Calendar为某一时刻和一组日历字段之间的转换提供了一些方法,并为操作日历字段提供了一些方法。
Calendar提供了一个类方法getlnstance用于获取Calendar对象,其日历字段已使用当前日期和时间初始化:
Calendar rightNow = Calendar.getlnstance();
Clendar的常用方法:
异常:
异常:就是程序出现了不正常的情况
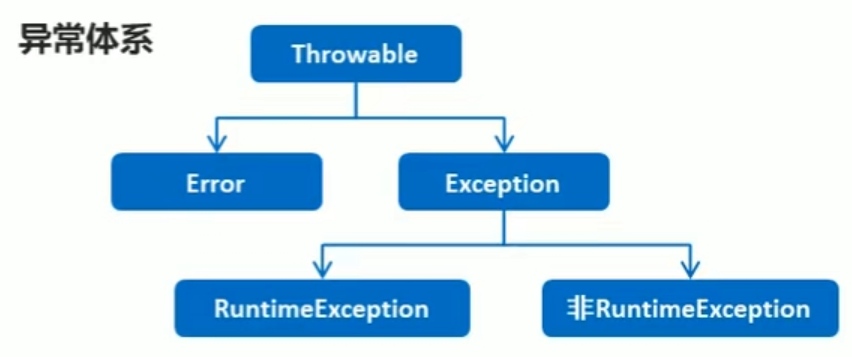
Error:严重问题,不需要处理
Exception:称为异常类,它表示程序本身可以处理的问题
RuntimeExceptiom:在编译期间是不检查的,出现问题后,需要我们回来修改代码
非RuntimeExceptiom:编译期间就必须处理的,否则程序不能通过编译,就更不能正常运行了
JVM的默认处理方案:
如果程序出现问题,我们没有做任何处理,最终JVM会做出默认的处理
会把异常的名称,异常的原因及异常出现的位置等信息输出在了控制台
把程序停止执行
异常处理:
如果程序出现问题,我们需要自己来处理,有两种方案:
try……catch……
throws
异常处理之try……catch……

执行流程:
程序从try里面的代码开始执行
出现异常,会自动生成一个异常类对象,该异常对象将被提交给Java运行时系统
当Java运行时系统接收到异常对象时,会到catch中去找匹配的异常类,找到后精选异常的处理
执行完毕之后,程序还可以继续往下执行
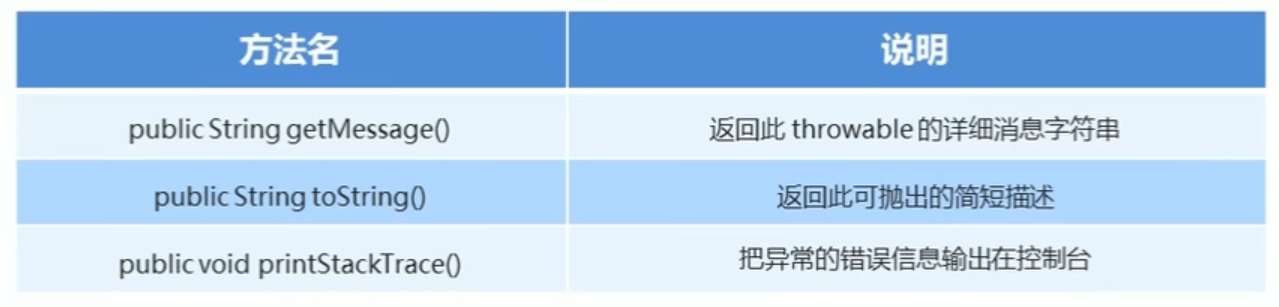
Throwable的成员方法(异常类):
编译时异常和运行时异常的区别
Java中的异常被分为两大类,编译时异常和运行时异常,也被称为受检异常和非受检异常
所有的RuntimeException类及其子类被称为运行时异常,其他的异常都是编译时异常
编译时异常:必须显示处理,否则程序就会发生错误,无法通过编译
运行时异常:无需显示处理,也可以和编译时异常一样处理
异常处理之throws
并不是所有的情况我们都有权限进行异常处理
针对这种情况,Java提供了throws的处理方案
格式:
throws 异常类名;
注意:这个格式是跟在方法的括号后面的
编译时异常必须要进行处理,两种处理方案:try……catch……或者throws,如果采用throws这种方案,将来谁调用谁处理
运行时异常可以不处理:出现问题后,需要我们回来修改代码
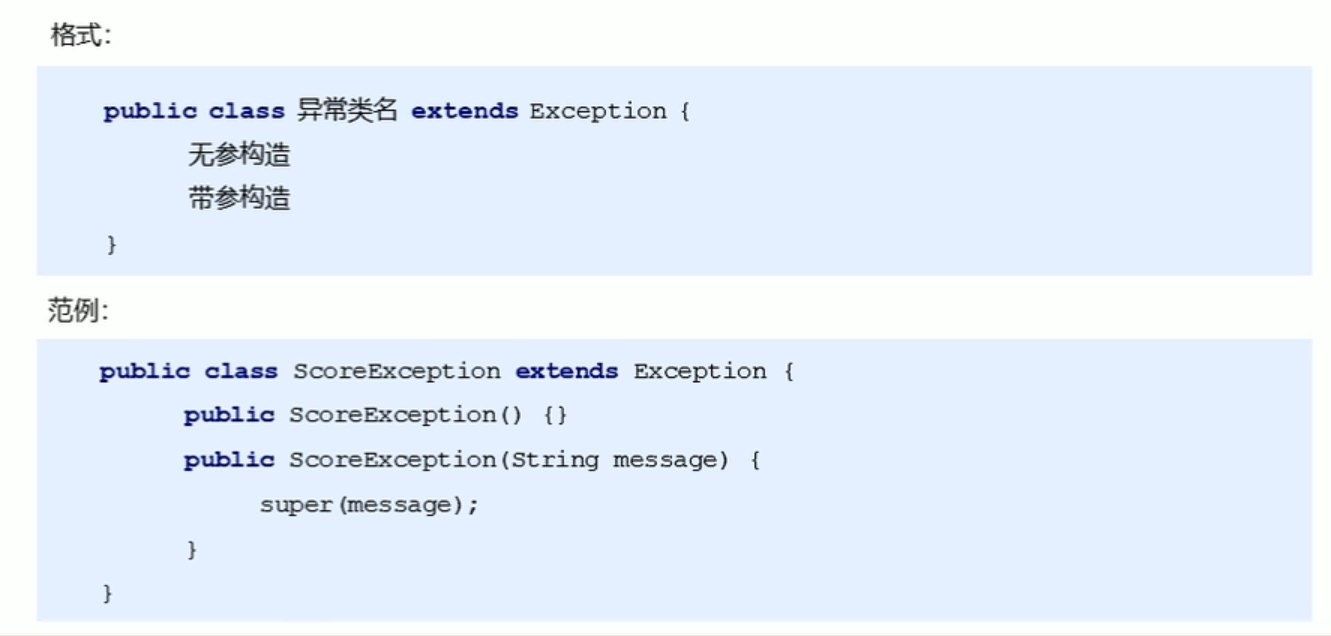
自定义异常:
throws和throw的区别:
throws throw
用在方法声明后面,根的是异常类名 用在方法体内,跟的是异常对象名
表示抛出异常,由该方法的调用者来处理 表示抛出异常,由方法体内的语句处理
表示出现异常的一种可能性,并不一定会发生这些异常
集合
集合类的特点:提供一种存储空间可变的存储模型,存储的数据容量可以随时发生改变。
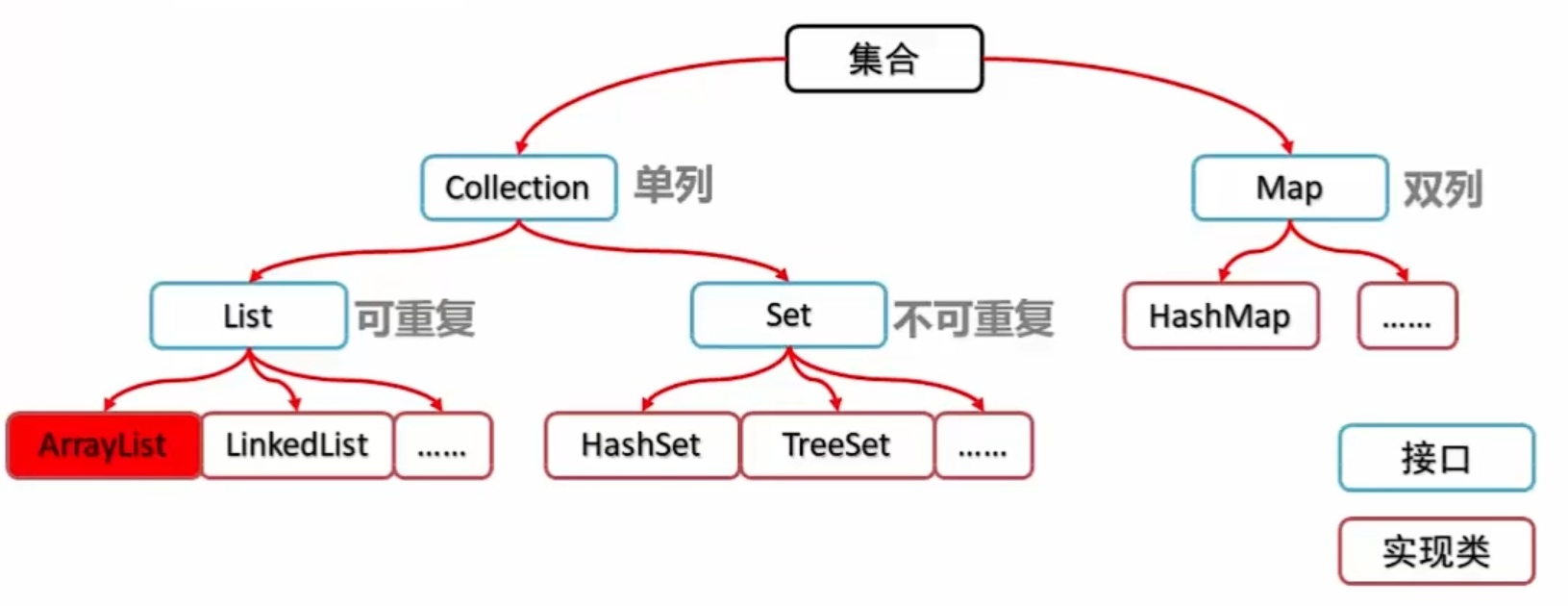
Collection集合概述和使用:
Collection集合概述:
是单例集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素。
创建Collection集合的对象:
多态的方式
具体的实现类ArrayList
Collection集合常用方法:
Collection集合的遍历:
Iterator:迭代器,集合的专用遍历方式
Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
迭代器是通过集合的iterator()方法得到的,所以我们说它是依赖于集合而存在的
Iterator中的常用方法:
E next():返回迭代中的下一个元素。
boolean hasNext():如果迭代具有更多元素,则返回true。
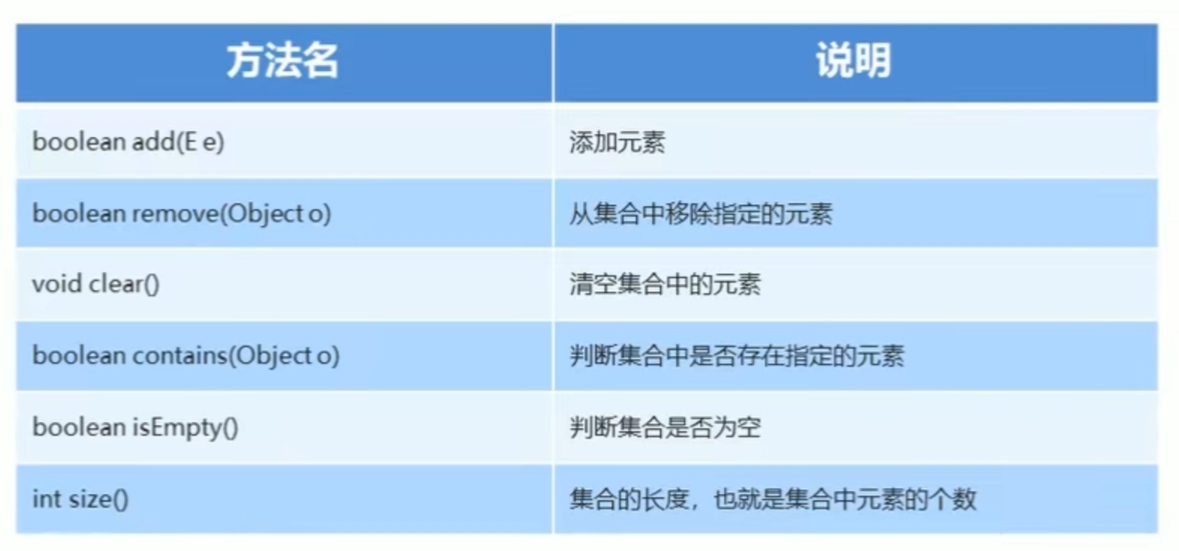
List
List集合概述和特点:
List集合概述:
有序集合(也称为序列),用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素。
与Set集合不同,列表通常允许重复的元素
List集合特点:
有序:存储和取出的元素顺序一致
可重复:存储的元素可以重复
List集合特有方法:
并发修改异常:
并发修改异常
ConcurrenModificationException
产生原因:
迭代器遍历的过程中,通过集合对象修改了集合中元素的长度,造成了迭代器获取元素中判断预期修改值和实际修改值不一致
解决方案:
用for循环遍历,然后用集合对象做对应的操作即可。
ListIterator
ListIterator:列表迭代器
通过List集合的listIterator()方法得到,所以说它是List集合特有的迭代器。
用于允许程序员沿任一方向遍历列表的列表的迭代器,在迭代期间修改列表,并获取列表中迭代器的当前位置。
ListIterator中的常用方法:
E next():返回迭代中的下一个元素
boolean hasNext():如果迭代具有更多元素,则返回true
E previous():返回列表中的上一个元素
boolean hasPrevious():如果此列表迭代器在相反方向遍历列表时具有更多元素,则返回true
void add(E e):将指定的元素插入列表
增强for循环
增强for:简化数组和Collection集合的遍历
实现terable接口的类允许其对象成为增强型for语句的目标
它是jdk5之后出现的,其内部原理是一个iterator迭代器
增强for的格式:
格式:
for(元素数据类型 变量名 : 数组或者Collection集合){
//在此处使用变量即可,该变量就是元素
}
常见的数据结构之栈
数据进入栈模型的过程称为:压/进栈 a,b,c,d
数据离开栈模型的过程称为:弹/出栈 d,c,b,a
最早一个进栈的数据称为栈底元素
最后一个进栈的数据称为栈顶元素
栈是一种数据先进后出的模型
![]()

常见数据结构之队列
数据从后端进入队列模型的过程称为:入队列
数据从前端离开队列模型的过程称为:出队列
队列是一种数据先进先出的模型

常见数据结构之数组
查询数据通过索引定位,查询任意数据耗时相同,查询速度快
删除数据时,要将原始数据删除,同时后面每个数据前移,删除效率低
添加数据时,添加位置后的每个数据后移,再添加元素,添加效率低
由此可知:数组是一种查询快,增删慢的模型
常见数据结构之链表
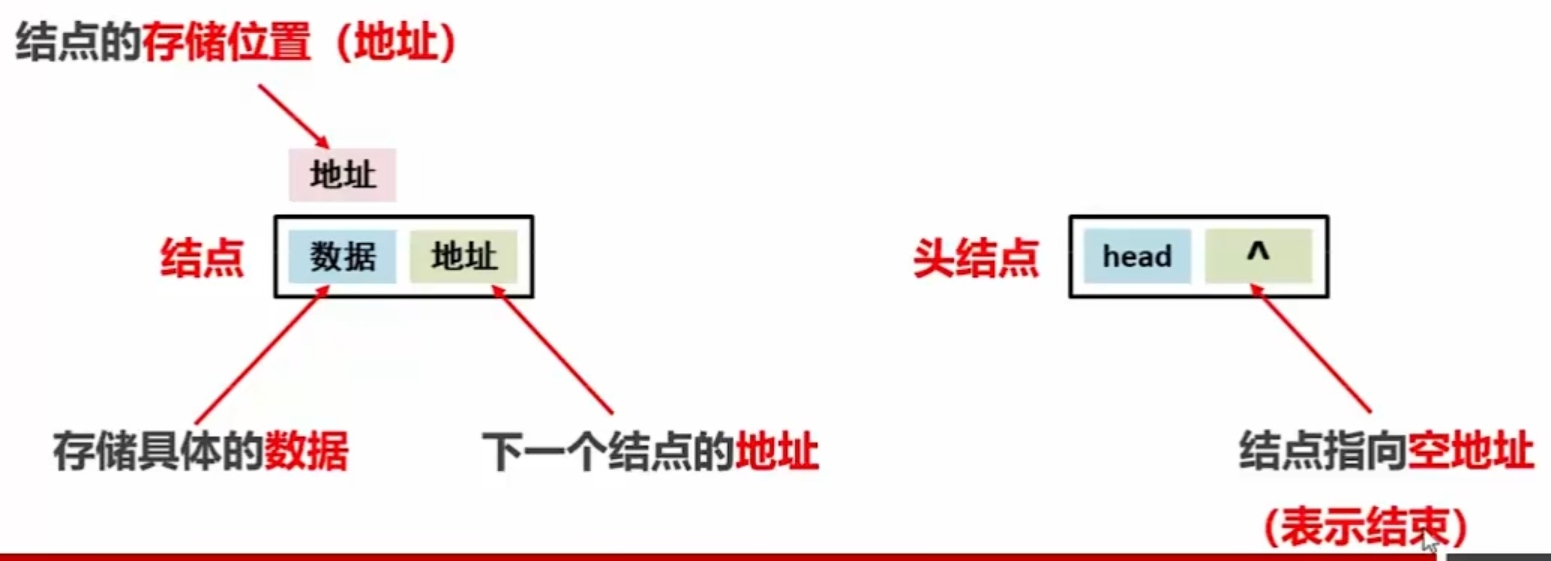
链表是一种增删快的模型(跟数组相比) 修改对应的地址值即可
链表是一种查询慢的模型(跟数组相比) 无论查多少位数 都得从头开始查
List集合子类特点
List集合常用子类:ArrayList\LinkedList
ArrayList:底层数据结构是数组,查询快,增删慢
LinkedList:底层数据结构是链表(双链表),查询慢,增删快
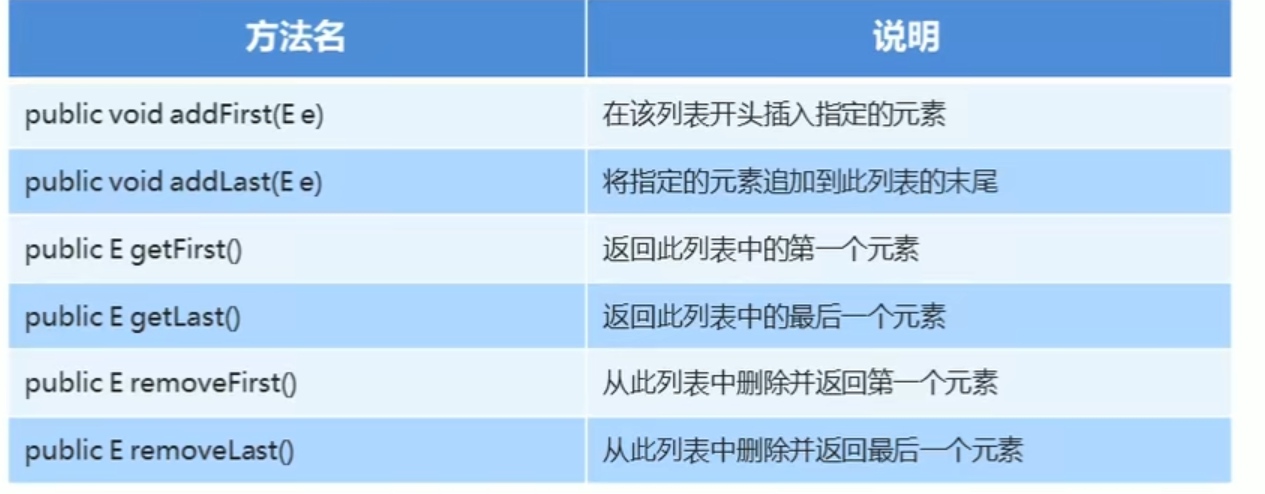
LinkedList集合的特有功能:
Set集合概述和特点
Set集合特点:
不包含重复元素的集合
没有带索引的方法,所以不能使用普通for循环遍历
哈希值
哈希值:是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
Object类中有一个方法可以获取对象的哈希值
对象哈希值的特点
同一个对象多次调用hashCode()方法返回的哈希值是相同的
默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
HashSet集合概述和特点
HashSet集合特点:
底层数据结构是哈希表
对集合的迭代顺序不作任何保证,二九四说不保证存储和取出的元素顺序一致
没有带索引的方法,所以不能使用普通for循环遍历
由于是Set集合,所以是不包含重复元素的集合
HashSet集合保证元素唯一性源码分析
HashSet集合添加一个元素的过程:
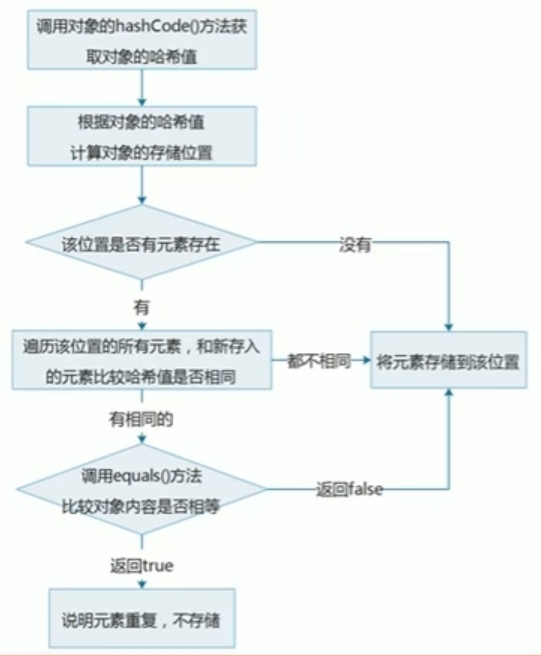
HashSet集合存储元素:
要保证元素唯一性,需要重写hashCode()和equals()
常见数据结构之哈希表
哈希表:
JDK8之前,底层采用数组+链表实现,可以说是一个元素位为链表的数组
JDK8之后,再长度比较长的时候,底层实现了优化
LinkedHashSet集合概述和特点
LinkedHashSet集合特点
哈希表和链表实现的Set接口,具有可预测的迭代次序
由链表保证元素有序,也就是说元素的存储和取出顺序是一致的
由哈希表保证元素的唯一,也就是说没有重复元素
TreeSet集合概述和特点
TreeSet集合特点
元素有序,这里的顺序不是指存储和取出的顺序,而是按照一定的规则进行排序,具体排序方式取决于构造方法
TreeSet():根据其元素的自然排序进行排序
TreeSet(Comparator comparator):根据指定的比较器进行排序
没有带索引的方法,所以不能使用普通for循环遍历
由于是Set集合,所以不包含重复元素
自然排序Comparable的使用
存储学生对象并遍历,创建TreeSet集合使用无参构造方法
要求:按照年龄从小到大排序、年龄相同时,按照名字的字母顺序排序
结论:
用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(To)方法
重写方法时,一定注意排序规则必须按照要求的主要条件和次要条件来写
比较器排序Comparator的使用
存储学生对象遍历,创建TreeSet集合使用带参构造方法
要求:按照年龄从小到大排序、年龄相同时,按照名字的字母顺序排序
结论:
用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(To1 To2)方法
重写方法时,一定注意排序规则必须按照要求的主要条件和次要条件来写
泛型
泛型概述:
泛型:是JDK5中引入的特性,它提供了编译时类型安全检测机制,该机制允许在编译时检测到非法的类型
它的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数
一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?
顾名思义,就是将类型由原来的具体的类型参数化,然后在使用/调用时传入具体的类型
这种参数类型可以用在类、方法和接口中,分别被称为泛型类、泛型方法、泛型接口
泛型定义格式:
<类型>:指定一种类型的格式,这里的类型可以看成是形参
<类型1,类型2,……>:指定多种类型的格式,多种类型之间用逗号隔开。这里的类型可以看成是形参
将来具体调用时候给定的类型可以看成是实参,并且实参的类型只能说引用数据类型
泛型好处:
把运行时期的问题提前到了编译期间
避免了强制类型转换
泛型类的定义格式:
格式:修饰符 Class 类名 <类型>{}
范例:public class Generic<T>{}
此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
泛型方法
泛型方法的定义格式:
格式:修饰符 <类型> 返回值类型 方法名(类型 变量名){}
范例: public <T> void show(T t){}
泛型接口
泛型接口的定义格式:
格式:修饰符 interface 接口名<类型>{}
范例:public interface Generic<T>{}
类型通配符
为了表示各种泛型List的父类,可以使用类型通配符
类型通配符:<?>
List<?>:表示元素类型未知的List,它的元素可以匹配任何类型
这种带通配符的List仅表示它是各种泛型List的父类,并不能把元素添加到其中
如果说我们不希望List<?>是任何泛型List的父类,只希望它代表某一类泛型List的父类,可以使用类型通配符的上限
类型通配符上限:<?extends 类型>
List<?extends Number>:它表示的类型是Number或者其子类对象
除了可以指定类型通配符的上限,我们也可以指定类型通配符的下限
类型通配符下限:<?super 类型>
List<?super Number>:它表示的类型是Number或者其父类型
可变参数
可变参数又称参数个数可边,用作方法的形参出现,那么方法参数个数就是可变的了
格式: 修饰符 返回值类型 方法名(数据类型…变量名){}
范例: public static int sum(int…a){}
可变参数注意事项
这里的变量其实是一个数组
如果一个方法有多个参数,包括可变参数,可变参数要放在最后
可变参数的使用
Arrays工具类中有一个静态方法:
public static<T> List<T> asList(T...a):返回由指定数组支持的固定大小的列表
返回的集合不能做增删操作,可以做修改操作
List接口中有一个静态方法:
public static<E> List<E> of(E...elements):返回包含任意数量元素的不可变列表
返回的集合不饿能做增删改操作
Set接口中有一个静态方法:
public static<E> Set<E> of(E...elements):返回一个包含任意数量元素的不可变集合
返回的集合不能做增删操作,没有修改的方法
Map
Map集合概述和使用
Map集合概述:
Interface Map<K,V> K:键的类型 V:值的类型
将键映射到值的对象,不能包含重复的键,每个键可以映射到最多一个值
举例:学生的学号和姓名
itheima001 林青霞
itheima002 张曼玉
itheima003 王祖贤
创建Map集合的对象
多态的方式
具体的实现类HashMap
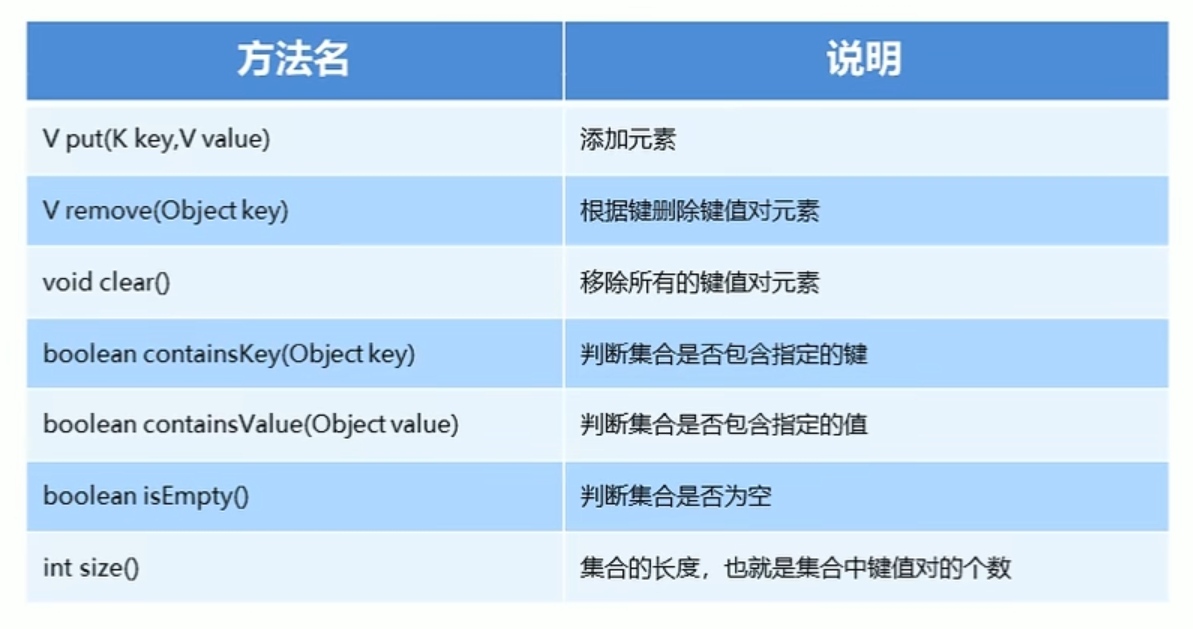
Map集合的基本功能
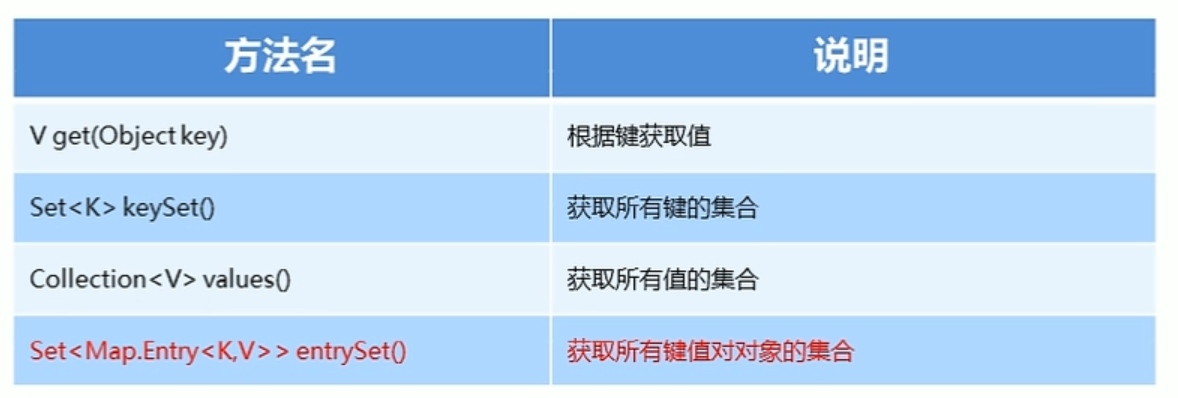
Map集合的获取功能
Map集合的遍历(方法一:我们刚才存储的元素都是成对出现的,所以我们把Map看成是一个夫妻对的集合
遍历思路:
把所有的丈夫给集中起来
遍历丈夫的集合,获取到每一个丈夫
根据丈夫去找对应的妻子
转换为Map集合中的操作:
获取所有键的集合,用keySet()方法实现
遍历键的集合,获取到每一个键,用增强for实现
根据键去找值,用get(Object key)方法实现
Map集合的遍历(方法2)
我们刚才存储的元素都是成对出现的,所以我们把Map看成是一个夫妻对的集合
遍历集合
获取所有结婚证的集合
遍历结婚证的集合,得到每一个结婚证
根据结婚证获取丈夫和妻子
转为Map集合中的操作:
获取所有键值对对象的集合
Set<Map.Entry<K,V>> entrySet():获取所有键值对对象的集合
遍历键值对对象的集合,得到每一个键值对对象
用for实现,得到每一个Map.Entry
根据键值对对象获取键和值
用getKey()得到键
用getValue()得到值
Collections
Collections概述和使用:
Collections类的概述:
是针对集合操作的工具类
Collections类的常用方法:
public static <T extrnds Comparable<?super T>> void sort(List<T> list):将指定的列表按升序排序
public static void reverse(List<?> list):反转指定列表中元素的顺序
public static void shuffle(List<?> list):使用默认的随机源随机排列指定的列表
File
File类概述和构造方法
File:它是文件和目录路径名的抽象表示
文件和目录是可以通过File封装成对象的
对File而言,其封装的并不是一个真正存在的文件,仅仅是一个路径名而已,它可以是存在的,也可以是不存在的。
将来是要通过具体的操作把这个路径的内容转换为具体存在的
构造方法:
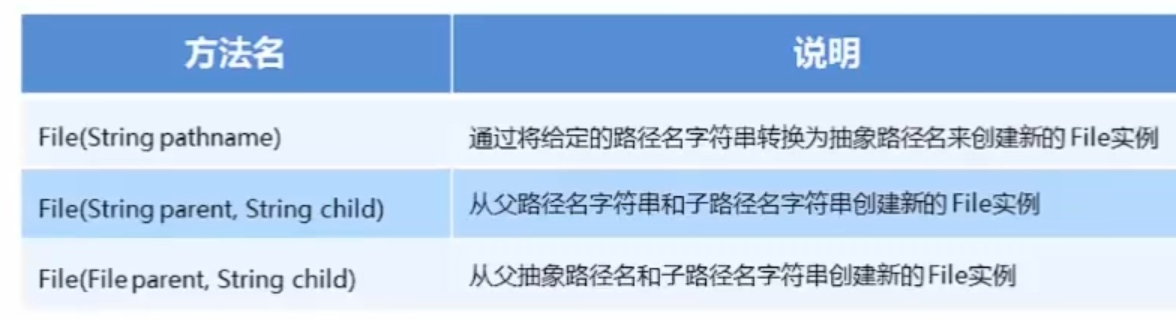
File类创建功能:

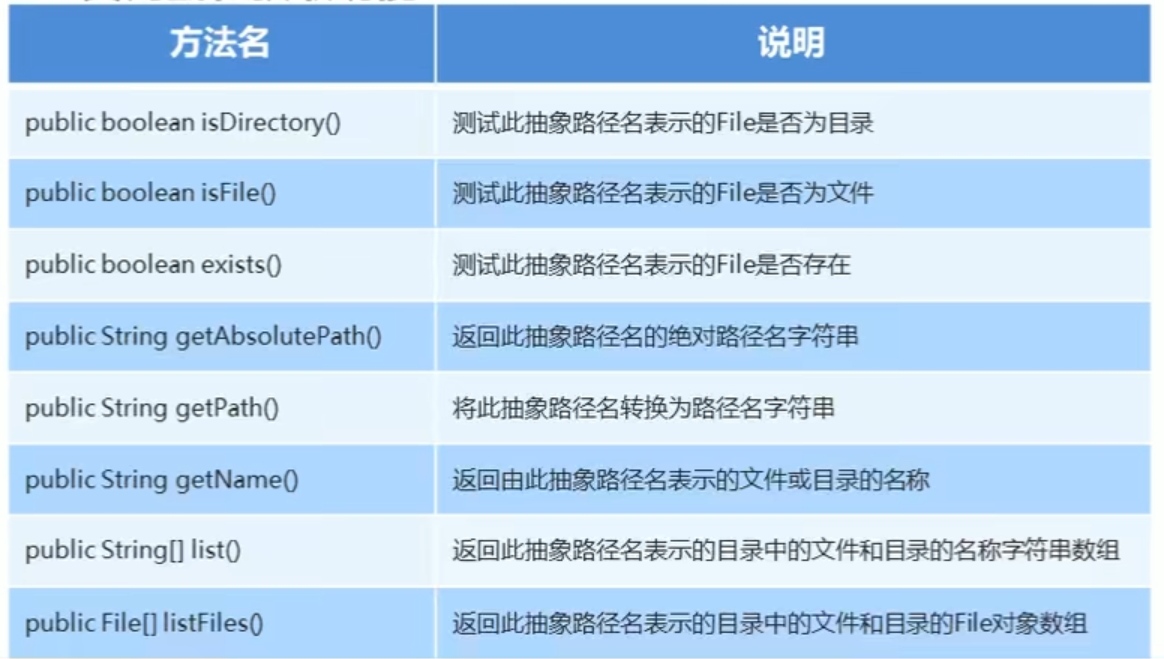
File类判断和获取功能

绝对路径和相对路径的区别:
绝对路径:完整的路径名,不需要任何其他信息就可以定位它所表示的文件。例如:E:\\leidian\\java.txt
相对路径:必须使用取自其他路径名的信息进行解释。例如:项目名\\java.txt
删除目录时的注意事项:
如果一个目录中有内容(目录、文件),不能直接删除。应该先删除目录中的内容,最后才能删除目录
递归
递归概述:以编程的角度来看,递归指的是方法定义中调用方法本身的现象
递归解决问题的思路:
把一个复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解
递归策略只需要少量的程序就可描述出解题过程所需要的多少次重复计算
递归解决问题要找到两个内容:
递归出口:否则会出现内存溢出
递归规则:与问题相似的规模较小的问题
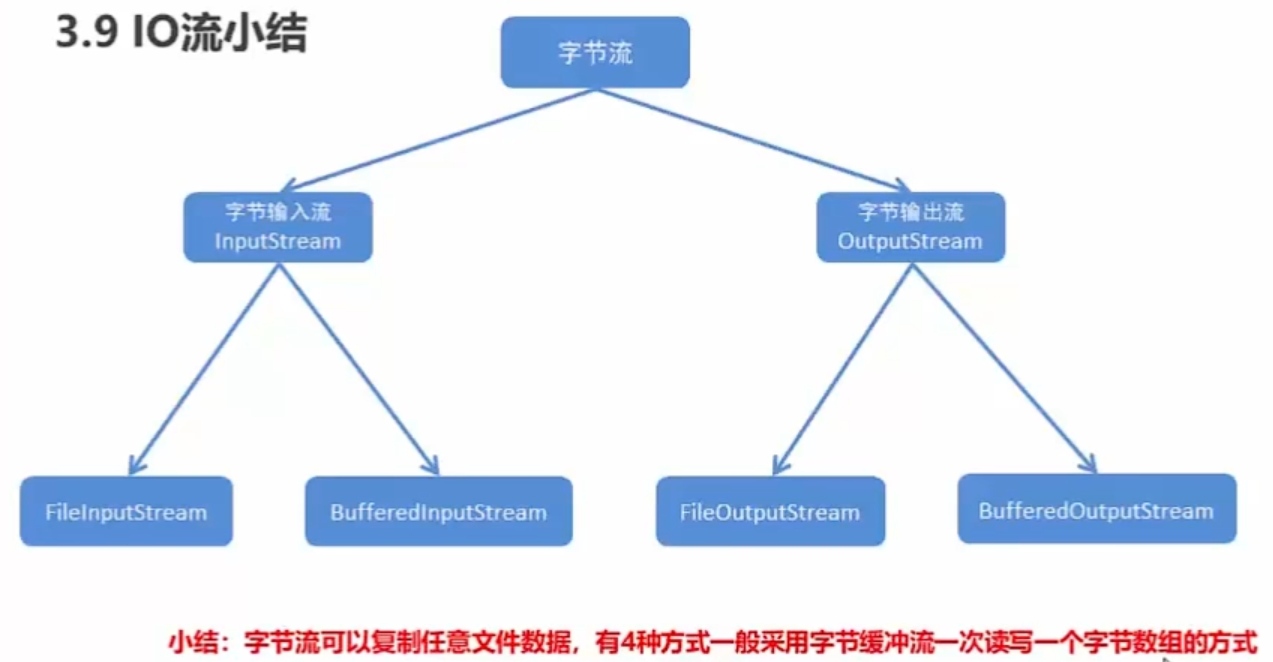
字节流
IO流概述和分类
IO概述:
IO:输入/输出(Input/Output)
流:是一种抽象概念,是对数据传输的总称。也就是说数据在设备间的传输为流,流的本质是数据传输。
IO流就是用来处理设备间数据传输问题的
常见的应用:文件复制;文件上传;文件下载
IO流分类:
按照数据的流向
输入流:读数据
输出流:写数据
按照数据类型来分
字节流
字节输入流;字节输出流
字符流
字符输入流;字节输出流
一般来说,我们说IO流的分类是按照数据类型来分的
那么这两种流都在什么情况下使用呢?
如果数据通过Window自带的记事本软件打开,我们还可以读懂里面的内容,就使用字符流,
否则使用字节流。如果你不知道该使用哪种类型的流,就使用字节流
字节流写数据
字节流抽象类
InputStream:这个抽象类是表示字节输入流的所有类的超类
OutputStream:这个抽象类是表示字节输出流的所有类的超类
子类名特点:子类名称都是以其父类作为子类名的后缀
FileOutputStream:文件输出流用于将数据写入File
FileOutputStream(String name):创建文件输出流以指定的名称写入文件
使用字节输出流写数据的步骤:
创建字节输出流对象(调用系统功能创建了文件,创建字节输出流对象,让字节输出流对象指向文件)
调用字节输出流对象的写数据方法
释放资源(关闭此文件输出流并释放与此流相关联的任何系统资源)【重要】
字节流写数据的3种方式

字节流写数据的两个小问题
字节流写数据如何实现换行呢?
写完数据后,加换行符
windows:\r\n
linux:\n
mac:\r
字节流写数据如何实现追加写入呢?
public FileOutputStream(String name,boolean append)
创建文件输出流以指定的名称写入文件,如果第二个参数为true,则字节将写入文件的末尾而不是开头
字节流写数据加异常处理
finally:在异常处理时提供finally块来执行所有清除操作。比如说IO流中的释放资源
特点:被finally控制的语句一定会执行,除非JVM退出
字节流读数据(一次读一个字节数据)
FileInputStream:从文件系统中的文件获取输入字节
FileInputStream(String name):通过打开与实际文件的连接来创建一个FileInputStream,该文件由文件系统中的路径名name命名
字节流缓冲流
字节流缓冲流:
BufferOutputStream:该类实现缓冲输出流,通过设置这样的输出流,应用程序可以向底层输出流写入字节,而不必为写入的每个字节导致底层系统的调用
BufferedInputStream:创建BufferedInputStream将创建一个内部缓冲区数组。当从流中读取或跳过字节时,内部缓冲区将根据需要从所包含的输入流中重新填充,一次很多个字节
构造方法:
字节缓冲输出流:BufferedOutputStream(OutputStream out)
字节缓冲输入流:BufferedInputStream(InputStream in)
为什么构造方法需要的是字节流,而不是具体的文件或者路径呢?
字节缓冲流仅仅提供缓冲区,而真正的读写数据还得依靠基本的字节流对象进行操作
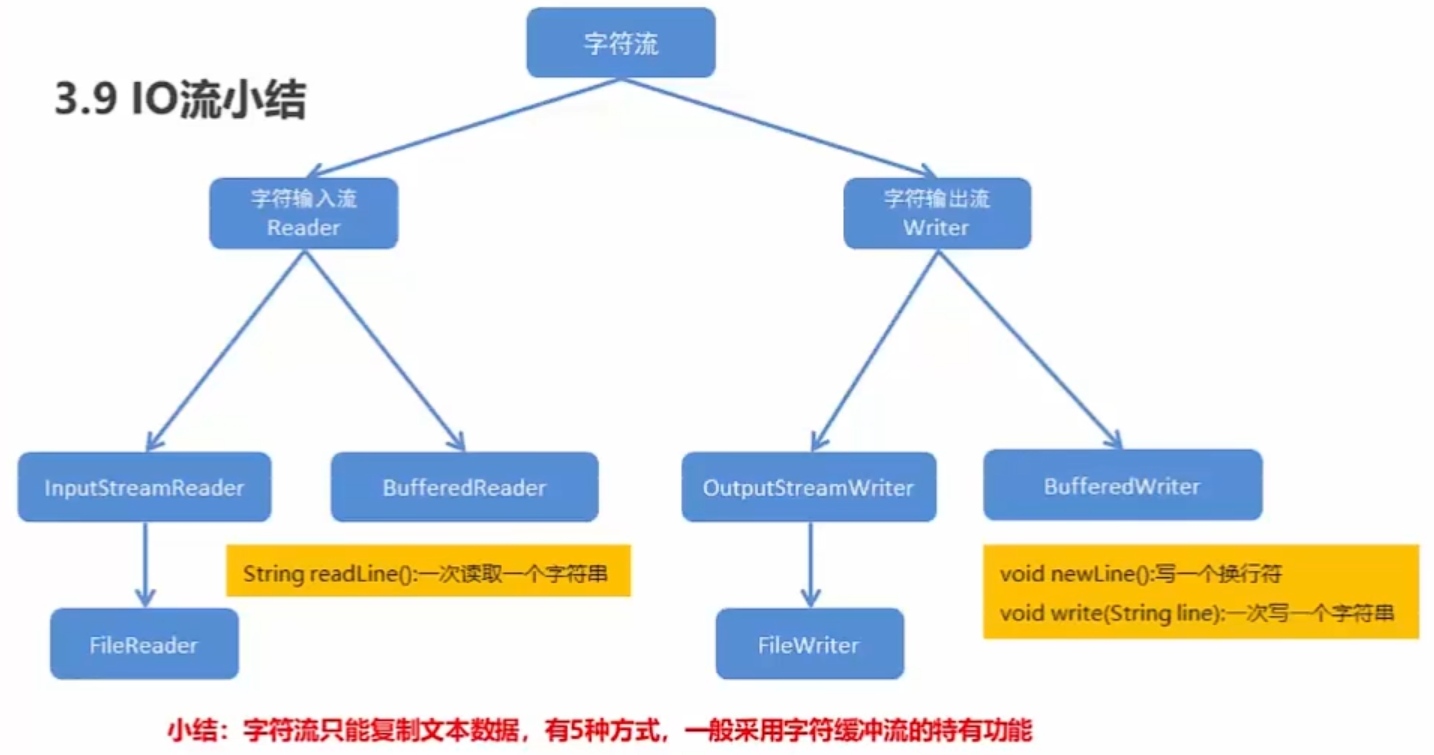
字符流
为什么会出现字符流?
由于字节流操作中文不死特别的方便,所以Java就提供字符流
字符流 = 字节流 + 编码表
用字节流复制文本文件时,文本文件也会有中文,但是没有问题,原因是最终底层操作会自动进行字节拼接成中文,如何识别是中文的呢?
汉字在存储的时候,无论选择哪种编码存储,第一个字节都是负数
编码表
基础知识:
计算机种存储的信息都是用二进制数表示的;我们在屏幕是看到的英文、汉字等字符是二进制数转换之后的结果
按照某种规则,将字符存储到计算机种,称为编码。反之,将存储在计算机中的二进制数按照某种规则解析出来,称为解码。
强调一下:按照A编码存储,必须按照A编码解析,这样才能显示正确的文本符号,否则就会导致乱码现象。
字符编码:就是一套自然语言的字符与二进制数之间的对应规则(A-65)
字符集
是一个系统支持的所有字符的集合,包括各个国家的文字、标点符号、图形符号、数字等
计算机要准确的存储和识别各种字符集符号,就需要进行字符编码,一套字符集必然至少有一套字符编码。
常见字符集有ASCII字符集、GBXXX字符集、Unicode字符集等
ASCII字符集
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):是基于拉丁字母的一套电脑编码系统,
用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)
基本的ASCII字符集,使用7位表示一个字符,共128字符。ASCII的扩展字符集使用8位表示一个字符,共2566字符,方便支持欧洲常用字符。
是一个系统支持的所有字符的集合,包括各个国家文字、标点符号、图形符号、数字等
GBKXXX字符集:
GB2312:简体中文码表。一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了
包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名等都编进去了,连ASCII里本来就有的数字、标点、字母都统统重新编了
两个字节长的编码,这就是常说的”全角“字符,而原来在127号以下的那些就叫”半角“字符了
GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等
GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等
Unicode字符集:
为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的是UTF-8编码
UTF-8编码:可以用来表示Unicode标准中任意字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。它使用一至四个字节为每个字符编码
编码规则:
128个US-ASCII字符,只需一个字节编码
拉丁文等字符,需要二个字节编码
大部分常用字(含中文),使用三个字节编码
其他极少使用的Unicode辅助字符,使用四字节编码
小结:采用何种规则编码,就要采用对应规则解码,否则就会出现乱码
字符串中的编码解码问题
编码:
byte[] getBytes():使用平台的默认字符集将该String编码为一系列字节,将结果存储到新的字节数组中
byte[] getBytes(String charsetName):使用指定的字符集将该String编码为一系列字节,将结果存储到新的字节数组中
解码:
String(byte[] bytes):通过使用平台的默认字符集解码指定的字节数组来构造新的String
String(byte[] bytes,String charsetName):通过指定的字符集解码指定的字节数组来构造新的String
字符流中的编码解码问题
字符流抽象基类
Reader:字符输入流的抽象类
Writer:字符输出流的抽象类
字符流中和编码解码问题相关的两个类:
InputStreamReader:是从字节流到字符流的桥梁
它读取字节,并使用指定的编码将其解码为字符
它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集
OutPutStreamWriter:是字符流到字节流的桥梁
是从字符流到字节流的桥梁,使用指定的编码将写入的字符编码为字节
它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集
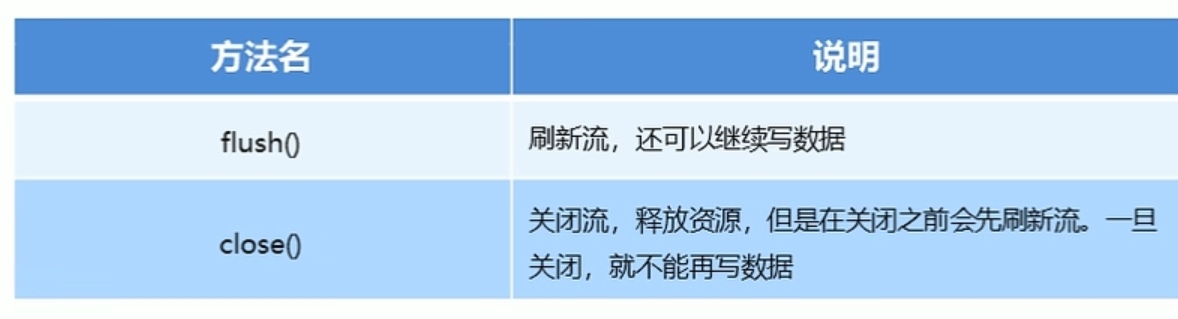
字符流写数据的5种方式

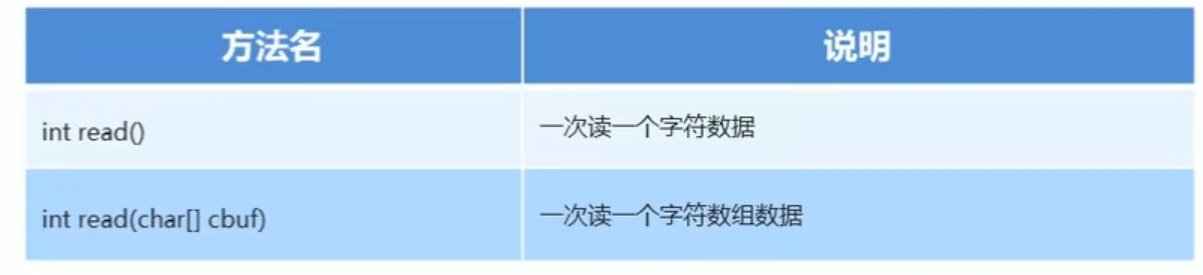
字符流读取数据的2种方式
字符缓冲流
BufferedWriter:将文本写入字符输出流,缓冲字符,以提供单个字符,数组和字符串的高效写入,可以指定缓冲区大小,或者可以接受默认大小。默认值足够大,可用于大多数用途
BufferedReader:从字符输入流读取文本,缓冲字符,以提供字符,数组和行的高效读取,可以指定缓冲区大小,或者可以使用默认大小。默认值足够大,可用于大多数用途
构造方法:
BufferedWriter(Writer out)
BufferedReader(Reader in)
字符缓冲流特有功能
BufferedWriter:
void newLine():写一个行行分隔符,行分隔符字符串由系统属性定义
BufferedReader:
public String readLine():读一行文字。结果包含行的内容的字符串,不包括任何行终止字符,如果流的结尾已到达,则为null
复制文件的异常处理:
try{
可能出现异常的代码;
}catch(异常类名 变量名){
异常的处理代码;
}finally{
执行所有清除操作;
}
标准输入输出流
System类中有两个静态的成员变量:
public static final InputStream in:标准输入流。通常该流对应于键盘输入或由主机环境或用户指定的另一个输入源
public static final PrintStream out:标准输出流。通常该流对应于显示输出或由主机环境或用户指定的另一个输出目标
打印流
打印流分类:
字节打印流:PrintStrean
字符打印流:PrintWriter
打印流的特点:
只负责输出数据,不负责读取数据
有自己的特有方法
字节打印流
PrintStream(String fileName):使用指定的文件名创建新的打印流
使用继承父类的方法写数据,查看的时候会转码,使用自己的特有方法写数据,查看的数据原样输出
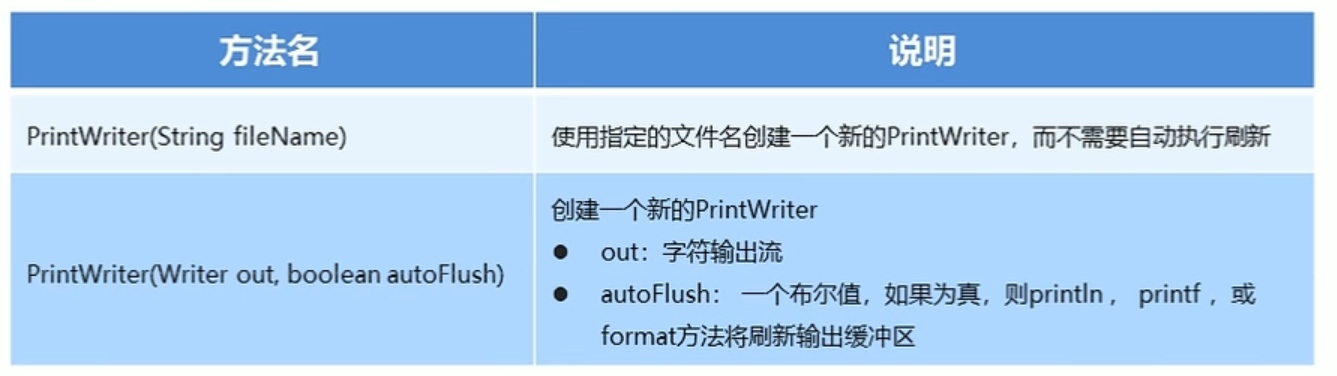
字符打印流
PrintWriter的构造方法:
对象序列化
对象序列化:就是将对象保存到磁盘中,或者在网络中传输对象
这种机制就是使用一个字节序列表示一个对象,该字节序列包含:对象的类型、对象的数据和对象中存储的属性等信息
字节序列写到文件之后,相当于文件中持久保存了一个对象的信息
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化
要实现序列化和反序列化就要使用序列化流和对象反序列化流:
对象序列化流:ObjectOutputStream
将Java对象的原始数据类型和图形写入OutputStream。可以使用ObjectInputStream读取(重构)对象。
可以通过使用流的文件来实现对象的持久存储。如果流是网络套接字流,则可以在另一个主机上或另一个进程中重构对象
构造方法
ObjectOutputStream(OutputStream out):创建一个写入指定的OutputStream的ObjectOutputStream
序列化对象的方法:
void writeObject(Object obj):将指定的对象写入ObjectOutputStream
注意:
一个对象要想被序列化,该对象所属的类必须实现Serializable接口
Serializable是一个标记接口,实现该接口,不需要重写任何方法
对象反序列化流:ObjectInputStream
ObjectInputStream反序列化先前使用ObjectOutputStream编写的原始数据和对象
构造方法:
ObjectInputStream(InputStream in):创建从指定的InputStream读取的ObjectInputStream
反序列化对象的方法:
Object readObject():从ObjectInputStream读取一个对象
用对象序列化流序列化了一个对象后,假如我们修改了对象所属的类文件,读取数据是否会出问题?
会出现问题,抛出InvalidClassException异常
如果出现问题了,如何解决?
给对象所属类加一个serialVersionUID
一个可序列化的类可以通过声明一个名为"serialVersionUID"的字段来显式地声明它自己的serialVersionUID,该字段必须是静态的,最终的,类型是long:(最好使用)
private static final long serialVersionUID = 42L;
如果一个对象中的某个成员变量的值不想被序列化,又该如何实现?
给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程
Properties
Properties概述:
是一个Map体系的集合类
Properties可以保存到流中加载
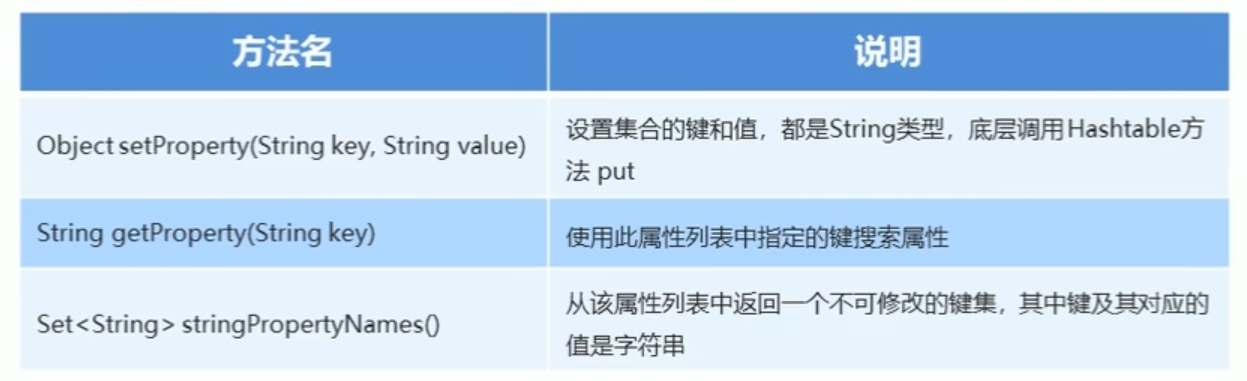
Properties作为集合的特有方法:
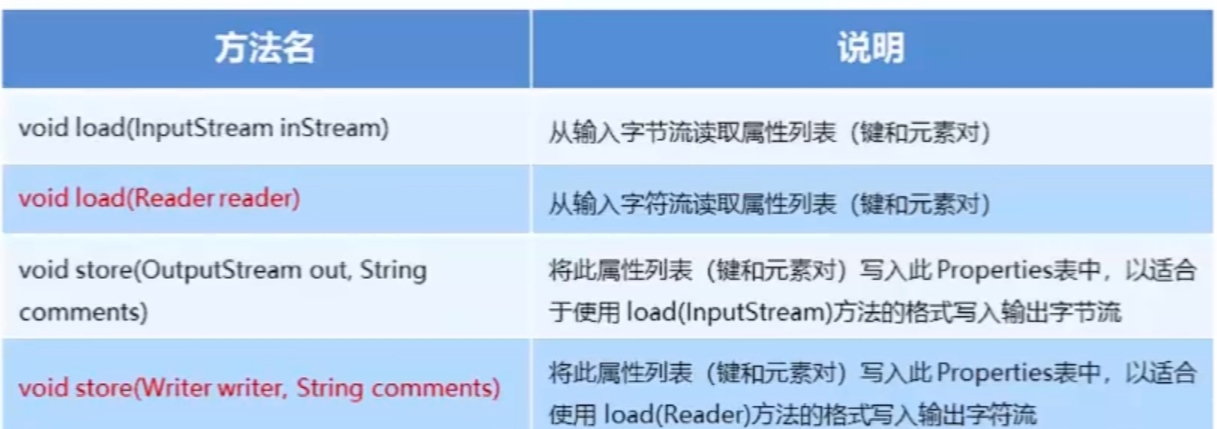
Properties和IO流结合的方法:
多线程
进程:
是正在运行的程序
是系统进行资源分配和调用的独立单位
每一个进程都有它自己的内存空间和系统资源
线程:
是进程中的单个顺序控制流,是一条执行路径
单线程:一个进程如果只有一条执行路径,则称为单线程程序
多线程:一个进程如果有多条执行路径,则称为多线程程序
多线程的实现方式:
方式1:继承Thread类
定义一个类MyThread继承Thread类
在MyThread类中重写run()方法
创建MyThread类的对象
启动线程
两个小问题:
为什么要重写run()方法?
因为run()是用来封装被线程执行的代码
run()方法和start()方法的区别?
run():封装线程执行的代码,直接调用,相当于普通方法的调用
start():启动线程;然后由JVM调用此线程的run()方法
设置和获取线程名称
Thread类中设置和获取线程名称的方法
void setName(String name):将此线程的名称更改为等于参数name
String getName():返回此线程的名称
通过构造方法也可以设置线程名称
如何获取main()方法所在的线程名称?
public static Thread currentThread():返回对当前正在执行的线程对象的引用
线程调度
线程有两种类型
分时调度模型:所有线程轮流使用CPU的使用权,平均分配每个线程占用CUP的时间片
抢占式调度模型:优先让优先级高的线程使用CPU,如果线程的优先级相同,那么会随机选择一个,优先级高的线程获取的CPU时间片相对多一些
Java使用的是抢占式调度模型
假如计算机只有一个CPU,那么CPU在某一个时刻只能执行一条指令,线程只有得到CPU时间片,也就是使用权,才可以执行指令,所以说多线程程序的执行是有随机性,因为谁抢到CPU的使用权是不一定的
Thread类中设置和获取线程优先级的方法:
public final int getPriorty():返回此线程的优先级
public final void setPriority(int newPriority):更改此线程的优先级
线程默认优先级是5;线程优先级范围是:1-10
线程优先级高仅仅表示线程获取的CPU时间片的几率高,但是要在次数比较多,或者多次运行的时候才能看到你想要的效果
线程控制:

线程的生命周期:

方式2:实现Runnable接口:
定义一个类MyRunnable实现Runnable接口
在MyRunnable类中重写run方法
创建MyRunnable类的对象
创建Thread类的对象,把MyRunnable对象作为构造方法的参数
启动线程
多线程的实现方式:
继承Thread类
实现Runnable接口
相比继承Thread类,实现Runnable接口的好处
避免了Java单继承的局限性
适合多个相同程序的代码去处理同一个资源的情况,把线程和程序的代码,数据有效分离,较好的体现了面向对象的设计思想
线程同步
卖票案例
卖票出现了问题:
相同的票出现了多次
出现了负数票
问题原因
线程执行的随机性导致的
为什么会出现问题?(这也是我们判断多线程程序是否会有数据安全问题的标准)
是否有多线程环境
是否有共享数据
是否有多条语句操作共享数据
如何解决多线程安全问题呢?
基本思想:让程序没有安全问题的环境
怎么实现呢?
把多条语句操作共享数据的代码给锁起来,让任意时刻只能有一个线程执行即可
同步代码块
锁多条语句操作共享数据,可以使用同步代码块来实现
格式:
synchronized(任意对象){
多条语句操作共享数据的代码
}
同步的好处和弊端:
好处:解决了多线程的数据安全问题
弊端:当线程很多时,因为每个线程都会去判断同步上的锁,这是很耗费资源的,无形中会降低程序的运行效率
同步方法
同步方法:就是把synchronizaed关键字加到方法上
格式:
修饰符synchronizaed 返回值类型方法(方法参数){}
同步方法的锁对象是什么呢?
this
同步静态方法:就是把synchronizaed 关键字加到静态方法上
格式:
修饰符 static synchronizaed 返回值类型 方法名(方法参数){}
同步静态方法的锁对象是什么呢?
类名.class
线程安全的类
StringBuffer(一般使用)
-
线程安全,可变的字符序列。
-
从版本JDK 5开始,被
StringBuilder替代。通常应该使用StringBuilder类,因为它支持所有相同的操作,但它更快,因为它不执行同步。
Vector(一般不使用 被Collections中的synchronizaed()方法替代,所以直接用此方法即可)
-
从Java 2平台v1.2,该类被改造为实现
List接口,使其成为Java Collections Framework的成员 。 与新的集合实现不同,Vector是同步的。 如果不需要线程安全的实现,建议使用ArrayList代替Vector
Hashtable()
-
该类实现了一个哈希表,它将键映射到值。 任何非
null对象都可以用作键值或值。
-
从Java 2平台v1.2,这个类被改进,实现了
Map接口,使其成为成员Java Collections Framework 。 与新的集合实现不同,Hashtable是同步的。 如果不需要线程安全的实现,建议使用HashMap代替Hashtable。 如果需要线程安全的并发实现,那么建议使用ConcurrentHashMap代替Hashtable。
Lock锁
Lock锁实现提供比使用synchronized方法和语句可以获得更广泛的锁定操作
Lock中提供了获得锁和释放锁的方法
void lock():获得锁
void lock():释放锁
Lock是接口,所以不能直接实例化,这里采用它的实现类ReentrantLock来实例化
ReentrantLock的构造方法
ReentrantLock():创建一个ReentrantLock的实例
生产者消费者模式概述:
生产者消费者模式是一个释放经典的多线程协作的模式,弄懂生产者消费者问题能够让我们对多线程编程的理解更加深刻
所谓生产者消费者问题,实际上主要是包含了两类线程:
一类是生产者线程用于生产数据
一类是消费者线程用于消费数据
为了解耦生产者和消费者的关系,通常会采用共享的数据区域,就像是一个仓库
生产者生产数据之后直接放置在共享数据区中,并不需要关系消费者的行为
消费者只需要从共享数据区中获取数据,并不需要关系生产者的行为

为了体现生产和消费构成在的等待和唤醒,Java就提供了几个方法供我们使用,这几个方法在Object类中
Object类的等待和唤醒方法:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号