TCPL 札记
2015-05-31 12:00 星星之火✨🔥 阅读(990) 评论(0) 收藏 举报1、函数原型符合设计要求,函数定义符合认知规律,做到见名知义,最少词汇量包含最大的信息量。
2、合理运用空行提高代码的可读性。从框架上来说有:
变量定义 初始化变量 处理 输出 返回值
3、采用伪码的方式简化问题,降低编程难度,如打印最长文本行的算法框架:
while(还有未处理的行)
if(该行比已处理的最长行还要长)
{
保存该行为最长行
保存该行的长度
}
打印最长的行
4、状态变量辅助字符串处理,如统计单词数中的
#define IN 1 #define OUT 0
初始化state = OUT;
5、注释:在函数定义处写上函数的功能,对变量范围有要求的注明范围;常量定义处写明常量用途;变量声明处写明变量用途;注释单行时,前后留有空格。注意不要画蛇添足了,一些显而易见的变量用途是不需要说明的,如最常用的循环变量i。
6、应该搞清楚字符常量与仅包含一个字符的字符串之间的区别:
'x' 与"x" 是不同的。前者是一个整数,其值是字母x 在机器字符集中对应的数值(内部表示值); 后者是一个包含一个字符(即字母x)以及一个结束符'\0' 的字符数组。
7、默认情况下,外部变量与静态变量将被初始化为零。未经显示初始化的自动变量的值为未定义值(即无效值)。
8、const 限定符指定变量的值不能被修改。对数组而言,const 限定符指定数组所有元素的值都不能被修改。
9、整数除法会截断结果中的小数部分。
10、如果某一年的年份能被4 整除但不能被100 整除,那么这一年就是闰年,此外,能被400 整除的年份也是闰年。
if((year % 4 == 0 && year % 100 !=0) || year % 400 == 0)
printf("%d is a leap year.\n", year);
else
printf("%d is not a leap year.\n", year);
取模运算符% 不能应用于float 或double 类型。
在有负操作数的情况下,整数除法截取的方向以及取模运算结果的符号取决于具体机器的实现,这和处理上溢或下溢的情况是一样的。
11、逻辑! 运算符的作用是将非0 操作数转换为0,将操作数0 转换为1。
12、C语言没有指定char 类型的变量是无符号变量还是带符号变量,但是int 是 signed int。
13、
// atoi: convert s to integer
int atoi(char s[])
{
int i, n;
n = 0;
for(i = 0; s[i] >= '0' && s[i] <= '9'; ++i)
n = 10*n + (s[i]-'0');
return n;
}
14、
// lower: convert c to lower case; ASCII only
int lower(int c)
{
if(c >= 'A' && c <= 'Z')
return c + 'a' - 'A';
else
return c;
}
注意这个函数是专门为ASCII字符集设计的,因为A~Z 之间只有字母,但对EBCDIC字符集不成立,因此该函数作用于EBCDIC字符集就不仅限于转换字母的大小写了。
此外,还需要注意的一点是,为什么形参是int?考虑到lower 的一个可能的应用场景:char c = lower(getchar()); 如果getchar() 返回EOF(即-1),而lower 接收char,如果该系统的char 是无符号的话,就会出现转换问题,这也是为什么C标准库(ctype.h)中的tolower 函数签名是 int tolower(int c) 而不是char tolower(char c) 的原因。
15、某些函数(如isdigit)在结果为真时可能返回任意的非零值,在if、while、for 等语句的测试部分中,"真"就意味着"非零"。
16、隐式算术类型转换:一般地,如果二元运算符的两个操作数具有不同的类型,那么在进行运算之前先要把"较低"的类型提升为"较高"的类型,运算结果为较高的类型。
-1L < 1U,因为unsigned int 的1U 将被提升为signed long 类型
-1L > 1UL,因为-1L 将被提升为unsigned long 类型
此外,赋值时也要进行类型转换。
(注意:浮点类型都是有符号的,有无符号只是对于整形变量而言,每个无符号类型都与对应的带符号类型相同,所以不能直接通过级数高低(long double > double > float > long long > long > int > short > char)来转换,但是如果带符号类型的值域包含了无符号类型所表示的值,就把无符号类型转化为有符号类型,否则,两个操作数都转化为对应的无符号类型)
17、表达式++n 先将n 的值递增1,然后再使用变量n 的值,而表达式n++ 则是先使用变量n 的值,然后再将n 的值递增1。
20、
// squeeze: delete all c from s
void squeeze(char s[], int c)
{
int i, j;
for(i = j = 0; s[i] != '\0'; i++)
if(s[i] != c)
s[j++] = s[i];
s[j] = '\0';
}
21、区分& 与&&:x = 1,y = 2,则x & y == 0, x && y == 1。
22、返回x 中从右边数第p 位开始向右数n 位的字段(假定最右边的一位是第0 位,n 与p 都是合理的正值)。例如:getbits(x, 4, 3) 返回x 中第4、3、2 三位的值。
// getbits: get n bits from position p
unsigned getbits(unsigned x, int p, int n)
{
return (x >> (p+1-n)) & ~(~0 << n); // x >> (p+1-n)将期望获得的字段移位到字的最右端,~(~0 << n)建立最右边n位全为1的屏蔽码
}
23、x *= y + 1 <-> x = x * (y+1)
这是因为在C语言中有:expr1 op= expr2 <-> expr1 = expr1 op (expr2)
24、统计整型参数的二进制表示中值为1 的个数
// bitcount: count 1 bits in x
int bitcount(unsigned x) // 这里将x声明为无符号类型是为了保证将x右移时,无论该程序在什么机器上运行,左边空出的位都用0(而不是符号位)填补
{
int b;
for(b = 0; x != 0; x >> 1)
if(x & 01)
b++;
return b;
}
25、条件表达式实际上就是一种表达式,其结果的类型由转换规则决定(详见第16条论述)。
例如:如果f 为float 类型,n 为int 类型,那么表达式 (n > 0) ? f : n 是float 类型,与n 是否为正值无关。
利用条件表达式可以编写出很简洁的代码:
for(i = 0; i < n; i++)
printf("%6d%c", a[i], (i%10 == 9 || i == n-1) ? '\n' : ' ');
这段代码用来打印一个数组的n 个元素,每行打印10 个,每列用一个空格隔开,每行用一个换行符结束(包括最后一行)。
另一个很好的例子是:
printf("You have %d item%s.\n", n, n == 1 ? "" : "s");
26、优先级:Unary &, +, - and * have higher precedence than the binary forms。
位运算符&、^、| 的优先级比==、!= 的低,这意味着位测试表达式如 if((x & MASK) == 0) 必须用圆括号括起来才能得到正确结果。
27、同大多数语言一样,C语言没有指定同一运算符中多个操作数的计算顺序(&&、||、?:、, 运算符除外)。例如:在形如x = f() + g(); 的语句中,f() 可以在g() 之前计算,也可以在g() 之后计算。因此,如果函数f 或g 改变了另一个函数使用的变量,那么x 的结果可能依赖于这两个函数的计算顺序。为了保证特定的计算顺序,可以把中间结果保存在临时变量中。
类似地,C语言也没有指定函数各参数的求值顺序。因此,语句printf("%d %d\n", ++n, power(2, n)); 在不同的编译器中可能会产生不同的结果,这取决于n 的自增运算在power 调用之前还是之后执行。解决办法是把该语句改写成:++n; printf("%d %d\n", n, power(2, n));
函数调用、嵌套赋值语句、自增与自减运算符都有可能产生"副作用"——在对表达式求值的同时,修改了某些变量的值。在有副作用影响的表达式中,其执行结果同表达式中的变量被修改的顺序之间存在着微妙的依赖关系,语句a[i] = i++; 就是一个典型的令人不愉快的情况,问题是:数组下标i 是引用旧值还是引用新值?对这种情况编译器的解释可能不同,并因此产生不同的结果。C语言标准对大多数这类问题有意未作具体规定。表达式何时会产生这种副作用(对变量赋值),将由编译器决定,因为最佳的求值顺序同机器结构有很大关系(ANSI C 标准明确规定了所有对参数的副作用都必须在函数调用之前生效,但是这对前面介绍的printf 函数调用没有什么帮助)。
在任何一种编程语言中,如果代码的执行结果与求值顺序有关,则都是不好的程序设计风格。很自然,有必要了解哪些问题需要避免,但是,如果不知道这些问题在各种机器上是如何解决的,就最好不要尝试运用某种特殊的实现方式。
28、
// binsearch: find x in v[0] <= v[1] <= ... <= v[n-1]
int binsearch(int x, int v[], int n)
{
int low, high, mid;
low = 0;
high = n - 1;
while(low <= high)
{
mid = (low+high) / 2;
if(x < v[mid])
high = mid - 1;
else if(x > v[mid])
low = mid + 1;
else // found match
return mid;
}
return -1; // no match
}
29、用switch 语句统计数字、空白符以及其它所有字符出现的次数。
#include<stdio.h>
int main(void)
{
int c, i, nwhite, nother, ndigit[10];
nwhite = nother = 0;
for(i = 0; i < 10; i++)
ndigit[i] = 0;
while((c = getchar()) != EOF)
{
switch(c)
{
case '0': case '1': case '2': case '3': case '4':
case '5': case '6': case '7': case '8': case '9':
ndigit[c-'0']++;
break;
case ' ':
case '\n':
case '\t':
nwhite++;
break;
default:
nother++;
break;
}
}
printf("digits = ");
for(i = 0; i < 10; i++)
printf(" %d", ndigit[i]);
printf(", white space = %d, other = %d\n", nwhite, nother);
return 0;
}
30、前面已经写了一个atoi 了,下面我们写一个更通用的版本:如有空白符,则跳过;如有符号,则处理符号;取整数部分,并执行转换。
#include<ctype.h>
// atoi: convert s to integer; version 2
int atoi(char s[])
{
int i, n, sign;
for(i = 0; isspace(s[i]); i++) // skip white space
;
sign = (s[i] == '-') ? -1 : 1;
if(s[i] == '+' || s[i] == '-') // skip sign
i++;
for(n = 0; isdigit(s[i]); i++)
n = 10*n + (s[i]-'0');
return sign * n;
}
31、原始希尔排序:
// shellsort: sort v[0] ... v[n-1] into increasing order
void shellsort(int v[], int n)
{
int gap, i, j, temp;
for(gap = n/2; gap > 0; gap /= 2)
{
for(i = gap; i < n; i++)
{
for(j = i - gap; j >= 0 && v[j] > v[j+gap]; j -= gap)
{
temp = v[j];
v[j] = v[j+gap];
v[j+gap] = temp;
}
}
}
}
32、合理运用逗号运算符的实例:
for(i = 0, j = strlen(s) - 1; i < j; i++, j--) c= s[i], s[i] = s[j], s[j] = c;
33、注意该函数不能处理整型所能表示的最大的负数,一个改进版本见Control Flow第三条。
// itoa: convert n to characters in s
void itoa(int n, char s[])
{
int i, sign;
if((sign = n) < 0) // record sign
n = -n; // make n positive
i = 0;
do{ // generate digits in reverse order
s[i++] = n % 10 + '0'; // get next digit
}while((n /= 10) > 0); // delete it
if(sign < 0)
s[i++] = '-';
s[i] = '\0';
reverse(s);
}
// reverse: reverse string s in place
void reverse(char s[])
{
int c, i, j;
for(i = 0, j = strlen(s) - 1; i < j; i++, j--)
{
c = s[i];
s[i] = s[j];
s[j] = c;
}
}
34、
// trim: remove trailing blanks, tabs, newlines
int trim(char s[])
{
int n;
for(n = strlen(s) - 1; n >= 0; n--)
if(s[n] != ' ' && s[n] != '\t' && s[n] != '\n')
break;
s[n+1] = '\0';
return n;
}
35、合理应用goto 语句的场合:跳出深度嵌套循环(两层或多层)
例子:使用goto 语句判定两数组a 与 b 是否具有相同元素
for(i = 0; i < n; i++) for(j = 0; j < m; j++) if(a[i] == b[j]) goto found; // didn't find any common element found: // got one: a[i] == b[j]
不使用goto 的话,当然也可以,不过略繁
found = 0; for(i = 0; i < n && !found; i++) for(j = 0; j < m && !found; j++) if(a[i] == b[j]) found = 1; if(found) // got one: a[i-1] == b[j-1] else // didn't find any common element
36、下面的程序将输入中包含特定"模式"的各行打印出来(UNIX程序grep的一个特例)
程序框架如下(注:细心体会用函数来进行模块化的好处):
while(还有未处理的行) if(该行包含指定的模式) 打印该行
详细代码:
#include <stdio.h>
#define MAXLINE 1000 // maximum input line length
int getline(char line[], int max);
int strindex(char source[], char searchfor[]);
char pattern[] = "ould"; // pattern to search for
// find all lines matching pattern
int main(void)
{
char line[MAXLINE];
int found = 0;
while(getline(line, MAXLINE) > 0)
{
if(strindex(line, pattern) >= 0)
{
printf("%s", line);
found++;
}
}
return found;
}
// getline: get line into s, return length
int getline(char s[], int lim)
{
int c, i;
i = 0;
while(--lim > 0 && (c = getchar()) != EOF && c != '\n')
s[i++] = c;
if(c == '\n')
s[i++] = c;
s[i] = '\0';
return i;
}
// strindex: return index of t in s, -1 if none
int strindex(char s[], char t[])
{
int i, j, k;
for(i = 0; s[i] != '\0'; i++)
{
for(j=i, k=0; t[k]!='\0' && s[j]==t[k]; j++, k++)
;
if(k > 0 && t[k] == '\0')
return i;
}
return -1;
}
37、atof 函数把字符串转换为相应的双精度浮点数,该函数需要处理可选的符号和小数点,并要考虑可能缺少整数部分或小数部分的情况:
#include <ctype.h>
// atof: convert string s to double
double atof(char s[])
{
double val, power;
int i, sign;
for(i = 0; isspace(s[i]); i++) // skip white space
;
sign = (s[i] == '-') ? -1 : 1;
if(s[i] == '+' || s[i] == '-')
i++;
for(val = 0.0; isdigit(s[i]); i++)
val = 10.0 * val + (s[i] - '0');
if(s[i] == '.')
i++;
for(power = 1.0; isdigit(s[i]); i++)
{
val = 10.0 * val + (s[i] - '0');
power *= 10.0;
}
return sign * val / power;
}
38、在上面的函数atof 的基础上,我们可以利用它编写出函数atoi:
// atoi: convert string s to integer using atof
int atoi(char s[])
{
double atof(char s[]);
return (int) atof(s);
}
39、外部变量与内部变量相比有更大的作用域和更长的生存期。自动变量只能在函数内部使用,从其所在的函数被调用时变量开始存在,在函数退出时变量消亡。而外部变量是永久存在的,它不属于哪个函数,它属于整个源文件,其作用域自然就是整个源文件。
40、下面我们编写一个具有加、减、乘、除四则运算功能的计算器程序。为了容易实现,我们在计算器程序中使用逆波兰(所有运算符都跟在操作数的后面。比如,中缀表达式:(1-2)*(4+5)采用逆波兰表示法为1 2 - 4 5 + *)表示法代替普通的中缀表示法。计算器程序的实现逻辑是:每个操作数都被依次压入栈中;当一个运算符到达时,从栈中弹出相应数目的操作数,把该运算符作用与相应数目的操作数,并把运算结果再压入栈中;到达输入行的末尾时,把栈顶的值弹出并打印。这样,程序的结构就构成一个循环,该循环根据运算符或操作数的类型控制程序的转移:
while(下一个运算符或操作数不是文件结束指示符) if(是数) 将该数压入到栈中 else if(是运算符) 弹出所需数目的操作符 执行运算 将结果压入到栈中 else if(是换行符) 弹出并打印栈顶的值 else 出错
栈的压入与弹出操作比较简单,但是,如果把错误检测与恢复操作都加进来,该程序就显得很长了,因此最好把它们设计成独立的函数,而不要把它们作为程序中重复的代码段使用。另外,还需要一个单独的函数来取下一个输入运算符或操作数。
设计中还有一个重要的问题需要考量:把栈放在哪儿?也就是说哪些例程可以直接访问它?一种可能是把它放在主函数main中,把栈及其当前位置作为参数传递给它执行压入或弹出操作的函数。但是,main 函数不需要了解控制栈的变量信息,它只进行压入与弹出操作。因此,可以把栈及相关信息放在外部变量中,并只供push 与pop 函数访问,而不能被main 函数访问。下面是完整代码:
#include <stdio.h>
#include <stdlib.h> // for atof()
#define MAXOP 100 // max size of operand or operator
#define NUMBER '0' // signal that a number was found
int getop(char []);
void push(double);
double pop(void);
// reverse Polish calculator
int main(void)
{
int type;
double op2;
char s[MAXOP];
while((type = getop(s)) != EOF)
{
switch(type)
{
case NUMBER:
push(atof(s));
break;
case '+':
push(pop() + pop());
break;
case '*':
push(pop() * pop());
break;
case '-':
op2 = pop();
push(pop() - op2);
break;
case '/':
op2 = pop();
if(op2 != 0.0)
push(pop() / op2);
else
printf("error: zero divisor");
break;
case '\n':
printf("\t%.8g\n", pop());
break;
default:
printf("error: unknown command %s\n", s);
break;
}
}
return 0;
}
#define MAXVAL 100 // maximum depth of val stack
int sp = 0; // next free stack position
double val[MAXVAL]; // value stack
// push: push f onto value stack
void push(double f)
{
if(sp < MAXVAL)
val[sp++] = f;
else
printf("error: stack full, can't push %g\n", f);
}
// pop: pop and return top value from stack
double pop(void)
{
if(sp > 0)
return val[--sp];
else
{
printf("error: stack empty\n");
return 0.0;
}
}
#include <ctype.h>
int getch(void);
void ungetch(int);
// getop: get next character or numeric operand
int getop(char s[])
{
int i, c;
while((s[0] = c = getch()) == ' ' || c == '\t')
;
s[1] = '\0';
if(!isdigit(c) && c != '.')
return c; // not a mumber
i = 0;
if(isdigit(c)) // collect integer part
while(isdigit(s[++i] = c = getch()))
;
if(c == '.') // collect fraction part
while(isdigit(s[++i] = c = getch()))
;
s[i] = '\0';
if(c != EOF)
ungetch(c);
return NUMBER;
}
#define BUFSIZE 100
char buf[BUFSIZE]; // buffer for ungetch
int bufp = 0; // next free position in buf
int getch(void) // get a (possibly pushed-back) character
{
return (bufp > 0) ? buf[--bufp] : getchar();
}
void ungetch(int c) // push character back on input
{
if(bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}
补充说明:
因为+ 与 * 两个操作符满足交换律,因此,操作数的弹出次序无关紧要。但是- 与/ 两个运算符的左右操作数必须加以区分。在函数调用push(pop() - pop()) 中并没有定义两个pop 调用的求值次序。为了保证正确的次序,必须像main 函数中一样把第一个值弹出到一个临时变量中。
这段程序中的getch 与ungetch 两个函数有什么用途呢? 程序中常常会出现这样的情况:程序不能确定它已经读入的输入是否足够,除非超前多读入一些输入。读入一些字符以合成一个数字的情况便是一例:在看到第一个非数字字符之前,已经读入的数的完整性是不能确定的。由于程序要超前读入一个字符,这样就导致最后有一个字符不属于当前所要读入的字符数。如果能"反读"不需要的字符,该问题就能解决。每当程序多读入一个字符时,就把它压回到输入中,对代码其余部分而言就好像没有读入该字符一样。我们可以编写一对互相协作的函数来比较方便地模拟反取字符操作。getch 函数用于读入下一个待处理的字符,而ungetch 函数则用于把字符放回到输入中,这样,以后在调用getch 函数时,在读入新的输入之前先返回ungetch 函数放回的那个字符。这两个函数之间的协同工作也很简单:ungetch 函数把要压回的字符放到一个共享缓冲区(字符数组)中,当该缓冲区不空时,getch 函数就从缓冲区中读取字符;当缓冲区为空时,getch 函数调用getchar 函数直接从输入中读字符。这里还需要增加一个下标变量来记住缓冲区中当前字符的位置。由于缓冲区与下标变量是供getch 与ungetch 函数共享的,且在两次调用之间必须保持值不变,因此它们必须是这两个函数的外部变量,被这两个函数所共享(注意:标准库中提供了ungetc 函数,用于将一个字符压回栈中。为了提供一种更通用的方法,我们在这里使用了一个数组而不是一个字符)。
41、作用域规则:
构成C语言程序的函数与外部变量可以分开进行编译。一个程序可以存放在几个文件中,原先已经编译过的函数可以从库中进行加载。这里我们感兴趣的问题有:
- 如何进行声明才能确保变量在编译时被正确声明?
- 如何安排声明的位置才能确保程序在加载时各部分能正确连接?
- 如何组织程序中的声明才能确保只有一份副本?
- 如何初始化外部变量?
外部变量或函数的作用域从声明它的地方开始,到其所在的(待编译的)文件的末尾结束。
如果要在外部变量的定义之前使用该变量,或者外部变量的定义与变量的使用不在同一个源文件中,则必须在相应的变量声明中强制性地使用关键字extern。
将外部变量的声明与定义严格区分开来很重要。变量声明用于说明变量的属性(主要是变量的类型),而变量定义除此以外还将引起存储器分配。
在一个源程序的所有源文件中,一个外部变量只能在某个文件中定义一次,而其它文件可以通过extern 声明来访问它(定义外部变量的源文件中也可以包含对该外部变量的extern 声明)。外部变量的定义中必须指定数组的长度,但extern 声明则不一定要指定数组的长度。
变量的初始化只能出现在其定义中。
42、头文件:下面我们针对第40 条的计算器程序,考虑如何将其分隔为若干个源文件。我们这样分隔:将主程序main 单独放在main.c 中;将push 与pop 函数以及它们使用的外部变量放在第二个文件stack.c中;将getop 函数放在第三个文件getop.c 中;将getch 与ungetch 函数放在第四个文件getch.c 中。之所以分隔成多个文件,主要是考虑在实际的程序中,它们分别来自于单独编译的库。
此外,还必须考虑定义和声明在这些文件之间的共享问题。我们尽可能把共享的部分集中在一起,这样就只需要一个副本,改进程序时也容易保证程序的正确性。我们把这些公共部分放置到头文件calc.h 中,在需要该头文件时通过#include 指令把它包含进来。如此分隔,程序形式如下:
calc.h:
#define NUMBER '0' // signal that a number was found void push(double); double pop(void); int getop(char[]); int getch(void); void ungetch(int);
main.c:
#include <stdio.h>
#include <stdlib.h> // for atof()
#include "calc.h"
#define MAXOP 100 // max size of operand or operator
// reverse Polish calculator
int main(void)
{
int type;
double op2;
char s[MAXOP];
while((type = getop(s)) != EOF)
{
switch(type)
{
case NUMBER:
push(atof(s));
break;
case '+':
push(pop() + pop());
break;
case '*':
push(pop() * pop());
break;
case '-':
op2 = pop();
push(pop() - op2);
break;
case '/':
op2 = pop();
if(op2 != 0.0)
push(pop() / op2);
else
printf("error: zero divisor");
break;
case '\n':
printf("\t%.8g\n", pop());
break;
default:
printf("error: unknown command %s\n", s);
break;
}
}
return 0;
}
getop.c
#include <stdio.h>
#include <ctype.h>
#include "calc.h"
// getop: get next character or numeric operand
int getop(char s[])
{
int i, c;
while((s[0] = c = getch()) == ' ' || c == '\t')
;
s[1] = '\0';
if(!isdigit(c) && c != '.')
return c; // not a mumber
i = 0;
if(isdigit(c)) // collect integer part
while(isdigit(s[++i] = c = getch()))
;
if(c == '.') // collect fraction part
while(isdigit(s[++i] = c = getch()))
;
s[i] = '\0';
if(c != EOF)
ungetch(c);
return NUMBER;
}
stack.c
#include <stdio.h>
#include "calc.h"
#define MAXVAL 100 // maximum depth of val stack
int sp = 0; // next free stack position
double val[MAXVAL]; // value stack
// push: push f onto value stack
void push(double f)
{
if(sp < MAXVAL)
val[sp++] = f;
else
printf("error: stack full, can't push %g\n", f);
}
// pop: pop and return top value from stack
double pop(void)
{
if(sp > 0)
return val[--sp];
else
{
printf("error: stack empty\n");
return 0.0;
}
}
getch.c
#include <stdio.h>
#define BUFSIZE 100
char buf[BUFSIZE]; // buffer for ungetch
int bufp ; // next free position in buf
int getch(void) // get a (possibly pushed-back) character
{
return (bufp > 0) ? buf[--bufp] : getchar();
}
void ungetch(int c) // push character back on input
{
if(bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}
我们对下面两个因素进行了折衷:一方面是我们期望每个文件只能访问它完成任务所需的信息;另一方面是现实中维护较多的头文件比较困难。我们可以得出这样一个结论:对于某些中等规模的程序,最好只用一个头文件存放程序中各部分共享的对象。较大的程序需要使用更多的头文件,我们需要精心地组织它们。
此外,如果采用#include <>的形式包含头文件calc.h ,则必须指定绝对路径。而用#include ""这种形式则是直接在当前目录下寻找。
编译命令:gcc main.c stack.c getop.c getch.c -Wall -o cal (注:-Wall参数告诉编译器打印所有警告信息)
43、静态变量:
用static 声明限定外部变量与函数,可以将其后声明的对象的作用域限定为被编译源文件的剩余部分。通过static 限定外部对象,可以达到隐藏外部对象的目的。比如,第42 条中的getch-ungetch 复合结构需要贡献buf 与bufp 两个变量,这样buf 与bufp 必须是外部变量,但这两个对象不应该给getch 与ungetch 函数的调用者访问。可以通过在正常的对象声明之前加上关键字static 作为前缀来实现对象的静态存储:
static char buf[BUFSIZE]; // buffer for ungetch
static int bufp = 0; // next free position in buf
int getch(void) {...}
void ungetch(int c) {...}
这样其他函数就不能访问变量buf 和bufp。
外部的static 声明通常多用于变量,当然,它也可用于声明函数。通常情况下,函数名字是全局可访问的,对整个程序的各个部分而言都可见。但是,如果把函数声明为static 类型,则该函数名除了对该函数声明所在的文件可见外,其他文件都无法访问。
此外,static 还可用于声明内部变量。它与函数中使用的自动变量的相同点是,只能在函数内部使用,不同的是,不管其所在函数是否被调用,它一直存在,不像自动变量那样,随着所在函数的被调用和退出而存在和消失。话句话说,static 类型的内部变量是一种只能在某个特定函数中使用但一直占据存储空间的变量。
44、寄存器变量
register 声明告诉编译器,它所声明的变量在程序中使用频率较高。将register 变量放在机器的寄存器中,可以使程序更小、执行速度更快。但编译器的寄存器有限,可以忽略此项。
register 声明只适用于自动变量以及函数的形式参数。
实际使用时,底层硬件的实际情况对寄存器变量的使用会有一些限制。每个函数中只有很少的变量可以保存在寄存器中,且只允许保存某些类型的变量。但是,过量的寄存器声明并没有什么害处,这是因为编译器可以忽略过量的或不支持的寄存器变量声明。另外,无论寄存器变量实际上是不是存放在寄存器中,它的地址都是不能访问的。在不同机器中,对寄存器变量的数目和类型的具体限制也是不同的。
45、程序块结构
下面的程序段中:
if(n > 0){
int i; // declare a new i
for(i = 0; i < n; i++)
...
}
变量i 的作用域是if 语句的真分支,这个i 与该程序块外声明的i 无关。每次进入程序块时,在程序块内声明以及初始化的自动变量都将被初始化。静态变量只在第一次进入程序块时被初始化一次。
自动变量(包括形式参数)也可以隐藏同名的外部变量与函数:
int x;
int y;
f(double x)
{
double y;
}
函数f 内的变量x 引用的是函数的参数,类型为double;而在函数f 外,x 是int 类型的外部变量。这段代码中的变量y 也是如此。
在一个好的程序设计风格中,应该尽量避免出现变量名隐藏外部作用域中相同名字的情况,否则,很可能引起混乱和错误。
46、各种存储类的初始化规则:
在不进行显式初始化的情况下,外部变量和静态变量都将被初始化为零,而自动变量和寄存器变量的初值则没有定义(即初值为无用的信息)。
对于外部变量与静态变量来说,初始化表达式必须是常量表达式,且只初始化一次(从概念上讲是在程序开始执行前进行初始化)。对于自动变量与寄存器变量,则在每次进入函数或程序块时都将被初始化。
对于自动变量与寄存器变量来说,初始化表达式可以不是常量表达式;表达式中可以包含任意在此表达式之前定义的值,包括函数调用。
数组的初始化可以在声明的后面紧跟一个用花括号括起来的初始化表达式列表,各表达式之间用逗号分隔。例如,如果要用一年中各月的天数初始化数组days,其变量的定义如下:int days[] = {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}; 当省略数组的长度时,编译器将把花括号中初始化表达式的个数作为数组的长度,在本例中的数组的长度为12。如果初始化表达式的个数比数组元素少,则对外部变量、静态变量和自动变量来说,没有初始化表达式的元素将被初始化为0,如果初始化表达式的个数比数组元素数多,则是错误的。不能一次将一个初始化表达式指定给多个数组元素,也不能跳过前面的元素而直接初始化后面的元素。
字符数组的初始化比较特殊,可以用一个字符串来代替用花括号括起来并用逗号分隔开的初始化表达式序列。例如:char pattern[] = "ould" 同 char pattern[] = {'o', 'u', 'l', 'd', '\0'} 是等价的。这种情况下,数组的长度时是5(4 个字符加上一个字符串结束符'\0')。
47、递归调用:函数直接或者间接调用自身。
考虑将一个数作为字符串打印的情况。数字是以反序生成的:低位数字先于高位数字生成。但它们必须以与此相反的次序打印。
我们提供解决该问题的两种方案:一种方法是将生成的各个数字存储到一个数组中,然后再以相反的次序打印它们。另一种方法则是使用递归,函数printf 首先调用它自身打印前面的(高位)数字,然后再打印后面的数字。这里编写的函数不能处理最大的负数。
// printd: print n in decimal
void printd(int n)
{
if(n < 0)
{
putchar('-');
n = -n;
}
if(n / 10)
printd(n / 10);
putchar(n % 10 + '0');
}
快排:从执行速度来讲,下面版本的快速排序函数可能不是最快的,但它是最简单的算法之一。在每次划分子集时,该算法总是选取各个子数组的中间元素。标准库中提供了一个qsort 函数,它可用于对任何类型的对象排序。
// qsort: sort v[left]...v[right] into increasing order
void qsort(int v[], int left, int right)
{
int i, last;
void swap(int v[], int i, int j);
if(left >= right) // do nothing if array contains
return; // fewer than two elements
swap(v, left, (left + right)/2); // move partition elem
last = left; // to v[0];
for(i = left + 1; i <= right; i++) // partition
if(v[i] < v[left])
swap(v, ++last, i);
swap(v, left, last); // restore partition elem
qsort(v, left, last-1);
qsort(v, last+1, right);
}
// swap: interchange v[i] and v[j]
void swap(int v[], int i, int j)
{
int temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
递归并不节省存储器的开销,因为递归调用过程必须在某个地方维护一个存储处理值的栈。递归的执行速度并不快,但递归代码比较紧凑,并且比相应的非递归代码更易于编写与理解。在描述树递归定义的数据结构时使用递归尤其方便。
48、C预处理器:从概念上将,预处理器是编译过程中单独执行的第一个步骤。
#include 指令:用于在编译期间把指定文件的内容包含进当前文件中,形如#include "文件名" 和 #include <文件名> 的行都将被替换为由文件名指定的文件的内容。如果文件名用引号引起来,则在源文件所在位置查找该文件;如果在该位置没有找到该文件,或者文件名是用<>括起来的,则根据相应的规则查找该文件,这个规则同具体的实现有关。很自然,如果某个包含文件的内容发生了变化,那么所有依赖于该包含文件的源文件都必须重新编译。
#define 指令:用任意字符序列代替一个标记,简单的形式有:#define 名字 替换文本,如 #define forever for(; ;) 为无限循环定义了一个新名字forever。宏定义也可以带参数,这样可以对不同的宏调用使用不同的替换文本。例如:#define max(A, B) ((A) > (B) ? (A) : (B)) 使用宏max 看起来很像是函数调用,但宏调用直接将替换文本插入到代码中。形式x = max(p+q, r+s) 将被替换成 x = ((p+q) > (r+s) ? (p+q) : (r+s)); 如果对各种类型的参数的处理是一致的,则可以用同一个宏定义应用于任何数据类型,而无需针对不同的数据类型需要定义不同的max 函数。仔细考虑一下max 的展开式,就会发现它存在一些缺陷。其中,作为参数的表达式要重复计算两次。如果表达式存在副作用(比如含有自增运算符或输入/输出),则会出现不正确的情况,例如:max(i++, j++) 其中最大的那个变量将增加2。其次,还要注意,要适当使用圆括号以保证计算次序的正确性。考虑宏定义:#define square(x) x * x 当用square(z+1) 调用该宏定义时会出现什么情况呢?不过,宏还是很有价值的。<stdio.h>头文件中的getchar 与putchar 函数在实际中常常被定义为宏,这样可以避免处理字符时调用函数所需的运行时开销。<ctype.h> 头文件中定义的函数也常常是通过宏实现的。可以通过#undef 指令取消名字的宏定义,这样做可以保证后续的调用是函数调用,而不是宏调用:#undef getchar int getchar(void) {...} 。替换对括在引号中的字符串不起作用。但是,如果在替换文本中,参数名以# 作为前缀则结果将被扩展为由实际参数替换该参数的带引号的字符串,如,可以将它与字符串连接运算结合起来编写一个调试打印宏:#define dprint(expr) printf(#expr " = %g\n", expr) 使用语句dprint(x/y) 调用该宏时,该宏将被扩展为:printf("x/y" " = %g\n", x/y) ; 其中的字符串被连接起来了,这样,该宏调用的效果等价于printf("x/y = %g\n", x/y);
条件包含:条件包含为在编译过程中根据计算所得的条件值选择性地包含不同代码提供了一种手段。#if 语句对其中的常量整型表达式进行求值,若该表达式的值不等于0,则执行其后的各行,知道遇到#endif、#elif(类似于else if)或#else 语句为止。在#if 语句中可以使用表达式defined (名字),该表达式的值遵循下列规则:当名字已经定义时,其值为1;否则,其值为0。例如,为了保证hdr.h 文件的内容只被包含一次,可以将该文件的内容包含在下列形式的条件语句中:
#if !defined(HDR) #define HDR // hdr.h 文件的内容放在这里 #endif
第一次包含头文件hdr.h 时,将定义名字HDR;以后再次包含该头文件时,会发现名字已经定义,这样将直接跳转到#endif 处。C语言专门定义了两个预处理语句#ifdef 与#ifndef,它们用来测试某个名字是否已经定义,因此上面这个例子可以改写成:
#ifndef HDR #define HDR // hdr.h 文件的内容放在这里 #endif
下面的预处理代码首先测试系统变量SYSTEM,然后根据变量的值确定包含哪个版本的头文件:
#if SYSTEM == SYSV #define HDR "sysv.h" #elif SYSTEM == BSD #define HDR "bsd.h" #elif SYSTEM == MSDOS #define HDR "msdos.h" #else #define HDR "default.h" #endif #include HDR
49、一元运算符* 是间接寻址或间接引用运算符。int *ip 声明了表达式*ip 的结果是int 类型。声明double *dp, atof(char *) 表明*dp 和atof(s) 的值都是double 类型,而atof 的参数是一个指向char 类型的指针.
50、C语言以传值方式将参数传递给被调函数,因此被调函数不能直接修改主调函数中变量的值。要想达到被调函数修改主调函数中变量的值这一目的,可以使用指针参数。
51、指向void 类型的指针可以存放指向任何类型的指针,但它不能间接引用其自身(我觉得技术上当然不存在实现难度,只是一块地址单元存放自己的地址不怎么有意义吧)。
52、一元运算符遵循从右到左的结合性,因此(*ip)++ 将ip 指向的对象的值加1(等同于++*ip)。而*ip++ 将对ip 进行加1 运算。
53、指针与函数参数:设计一个函数接受自由格式的输入,并执行转换,将输入的字符流分解成整数,且每次调用得到一个整数。
设计思路:将标识是否到达文件结尾的状态作为getint 函数得而返回值。同时,使用一个指针参数存储转换后得到的整数并传回给主调函数,scanf 的实现就采用了这种方法。下面这个版本的getint 函数在到达文件结尾时返回EOF,当下一个输入不是数字时返回0。当输入中包含一个有意义的数字时返回一个正值。程序核心如下:
#include <stdio.h>
#include <ctype.h>
int getch(void);
void ungetch(int);
// getint: get next integer from input into *pn
int getint(int *pn)
{
int c, sign;
while(isspace(c = getch())) // skip white space
;
if(!isdigit(c) && c != EOF && c != '+' && c != '-')
{
ungetch(c); // it is not a number
return 0;
}
sign = (c == '-') ? -1 : 1;
if(c == '+' || c == '-')
c = getch();
for(*pn = 0; isdigit(c); c = getch())
*pn = 10 * *pn + (c - '0');
*pn *= sign;
if(c != EOF)
ungetch(c);
return c;
}
#include <stdio.h>
#define BUFSIZE 100
char buf[BUFSIZE]; // buffer for ungetch
int bufp = 0; // next free position in buf
int getch(void) // get a (possibly pushed-back) character
{
return (bufp > 0) ? buf[--bufp] : getchar();
}
void ungetch(int c) // push character back on input
{
if(bufp >= BUFSIZE)
printf("ungetch: too many characters\n");
else
buf[bufp++] = c;
}
主调:
int n, array[SIZE], getint(int *); for(n = 0; n < SIZE && getint(&array[n]) != EOF; n++) ;
54、通过数组下标所能完成的任何操作都可以通过指针来实现,一般来说,用指针编写的程序的执行速度比用下标编写的程序快。但是,用指针编写的程序理解起来稍微困难些。
55、指针加1 意味着该指针指向它原先所指向的对象的下一个对象,可以利用该特性编写strlen 函数的另一个版本:
// strlen: return length of string s
int strlen(char *s)
{
int n;
for(n = 0; *s != '\0'; s++)
n++;
return n;
}
注意,对指针s 执行s++ 运算不会影响到strlen 函数的调用者中的字符串,它仅对该指针在strlen 函数中的私有副本进行自增运算。
56、数组名所代表的就是该数组首元素的地址,所以,当把数组名传递给一个函数时,实际上传递的该数组第一个元素的地址,也就是一个指针。
57、下标和指针之间有密切的对应关系。在计算数组a[i] 的值时,C语言实际上先将其转换为*(a+i) 的形式,然后再对其求值,因此在程序中这两种形式是等价的。如果对这两种等价的表示形式分别施加地址符&,便可得出结论:&a[i] 和 a+i 的含义也是相同的。相应地,如果pa 是个指针,那么在表达式中,也可以在它的后面加下标,pa[i] 与 *(pa+i) 是等价的。简言之,一个通过数组和下标实现的表达式可等价地通过指针和偏移量实现,两者是互通的。
58、数组名和指针的一个不同之处:指针是一个变量,但数组名不是。因此,类似于pa = a 和pa++ 形式的语句是合法的,但语句a = pa 和 a++就是非法的。
59、在函数定义中,形参char s[] 和char *s 是等价的,通常我们更习惯使用后一种形式,因为它比前者更直观地表明了该参数是一个指针。也可以将数组的一部分传递给函数,如f(&a[2]) 与 f(a+2) 都将把起始于a[2] 的子数组的地址传递给函数f。如果确信相应的元素存在,也可以通过下标访问数组第一个元素之前的元素,类似于p[-1]、p[-2] 这样的表达式在语法上都是合法的,它们分别引用位于p[0] 之前的两个元素。当然,引用数组边界之外的对象是非法的。
60、下面的程序展示了一个不完善的存储分配程序。
#define ALLOCSIZE 10000 // sizeof avaliable space
static char allocbuf[ALLOCSIZE]; // storage for alloc
static char *allocp = allocbuf; // next free position
char * alloc(int n) // return pointer to n characters
{
if(ALLOCSIZE - (allocp - allocbuf) >= n) // it fits
{
allocp += n;
return allocp-n; // old p
}
else // not enought room
return 0;
}
void afree(char *p) // free storage pointed to by p
{
if(p >= allocbuf && p < allocbuf + ALLOCSIZE)
allocp = p;
}
PS:第一个函数alloc(n) 返回一个指向n 个连续字符存储单元的指针,该函数的调用者可利用该指针存储字符序列。第二个函数afree(p) 释放已分配的存储空间,以便以后重用。这里alloc 与afree 以栈的方式对存储空间进行管理。此外,C语言保证,0 永远不是有效的数据地址,因此,返回值0 可以用来表示发生了异常事件。本例中,alloc(n) 的返回值0 表示没有足够的空间可供分配。
61、指针与整数之间不能相互转换,但0 是唯一的例外:常量0 可以赋值给指针,指针也可以和常量0 进行比较。程序中经常用符号常量NULL 代替常量0,这样便于更清晰地说明常量0 是指针的一个特殊值。符号常量NULL 定义在标准头文件<stddef.h> 中。
62、有效的指针运算包括相同类型指针之间的赋值运算;指针同整数之间的加法或减法运算,指向相同数组中两个元素的两个指针之间的减法或比较运算。将指针赋值为0 或指针与0 之间的比较运算。其它所有形式的指针运算都是非法的。例如两个指针间的加法、乘法、除法、移位或屏蔽运算;指针同float 或double 类型之间的加法运算;不经强制类型转换而直接将指向一种类型对象的指针赋值给指向另一种类型对象的指针的运算(两个指针之一是void 类型的情况除外)。
63、指针的算术运算中可以使用数组最后一个元素的下一个元素的地址。
64、计算p+n 时,n 将根据p 指向的对象的长度按比例缩放(例如:如果某机器上int 类型占4 个字节的存储空间,那么int 类型的计算中,对应的n 将按4 的倍数来计算,即:所有的指针运算都会自动考虑它所指向的对象的长度);而p 指向的对象的长度则取决于p 的声明。可以借此编写函数strlen 的另一个版本:
// strlen: return length of string s
int strlen(char *s)
{
char *p = s;
while(*p != '\0')
p++;
return p-s;
}
65、下面两个定义之间有很大的差别:
char amessage[] = "now is the time"; // 定义一个数组 char *pmessage = "now is the time"; // 定义一个指针
上述声明中,amessage是一个仅仅足以存放初始化字符串以及空字符'\0' 的一维数组。数组中的单个字符可以进行修改,但amessage 始终指向同一个存储位置。另一方面,pmessage 是一个指针,其初值指向一个字符串常量,之后它可以修改以指向其它地址,但如果试图修改字符串的内容,结果是没有定义的。
66、让我们来研究一下strcpy 函数的几个不同的实现版本:
// strcpy: copy t to s; array subscript version
void strcpy(char *s, char *t)
{
int i;
i = 0;
while((s[i] = t[i]) != '\0')
i++;
}
// strcpy: copy t to s; pointer version
void strcpy(char *s, char *t)
{
while((*s=*t) != '\0')
{
s++;
t++;
}
}
实际中,strcpy函数并不会按上面这些方式编写。经验丰富的程序员更喜欢将它编写成下列形式:
// strcpy: coty t to s; pointer version 2
void strcpy(char *s, char *t)
{
while((*s++ = *t++) != '\0')
;
}
为了进一步精炼程序,注意到,表达式同'\0'的比较是多余的,因为只需要判断表达式的值是否为0即可。因此函数可进一步写成:
// strcpy: copy t to s; pointer version 3
void strcpy(char *s, char *t)
{
while((*s++ = *t++))
;
}
注1:标准库<string.h> 中提供的函数strcpy 把目标字符串作为函数值返回。以便于进行链式编程。
注2:该函数初看起来不太容易理解,但这种表示方法是有很大好处的,我们应该掌握这种方法,C语言程序中经常会采用这种写法。
67、再来研究一下字符串比较函数strcmp(s, t) 。该函数比较字符串s 和t,并且根据s 按照字典顺序小于、等于或大于t 的结果分别返回负整数、0或正整数。该返回值是s 和t 由前向后逐字符比较时遇到的第一个不相等字符处的字符的差值。
// strcmp: return <0 if s<t, 0 if s==t, >0 if s>t
int strcmp(char *s, char *t)
{
int i;
for(i = 0; s[i] == t[i]; i++)
if(s[i] == '\0')
return 0;
return s[i] - t[i];
}
// implements strcmp use pointer
int strcmp(char *s, char *t)
{
for(; *s == *t; s++, t++)
if(*s == '\0')
return 0;
return *s - *t;
}
68、下面两个表达式是进栈和出栈的标准用法(注意一元运算符的优先级和结合性):
*p++ = val; // 将val压栈
val = *--p; // 将栈顶元素弹到val中
69、指针数组以及指向指针的指针
下面的程序是Unix 中sort 程序的一个简化版,该程序对由文本行组成的集合进行排序。因为所需要处理的是长度不一的文本行。并且与整数不同的是,它们不能在单个运算中完成比较或移动操作。我们需要一个能够高效、方便地处理可变长度文本行的数据表示方法。于是引入指针数组处理这类问题。如果带排序的文本行首尾相连地存储在一个长字符数组中,那么每个文本行可通过指向它的第一个字符的指针来访问。这些指针本身可以存储在一个数组中。这样,两个文本行的比较通过strcmp 来实现,而交换次序颠倒的两个文本行实际上交换的是指针数组中与这两个文本行所对应的指针,而不是这两个文本行本身——这种实现方法消除了因移动文本行本身所带来的复杂的存储管理和巨大的开销这两个孪生问题。排序过程包括三个步骤:读取所有输入行;对文本行进行排序;按次序打印文本行。
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 // max lines to be sorted
char *lineptr[MAXLINES]; // pointer to text lines
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void qsort(char *lineptr[], int left, int right);
// sort input lines
int main(void)
{
int nlines; // number of input lines read
if((nlines = readlines(lineptr, MAXLINES)) >= 0)
{
qsort(lineptr, 0, nlines-1);
writelines(lineptr, nlines);
return 0;
}
else
{
printf("error: input too big to sort\n");
return 1;
}
}
#define MAXLEN 1000 // max length of any input line
int getline(char *, int);
char *alloc(int);
// readlines: read input lines
int readlines(char *lineptr[], int maxlines)
{
int len, nlines;
char *p, line[MAXLEN];
nlines = 0;
while((len = getline(line, MAXLEN)) > 0)
if(nlines >= maxlines || (p = alloc(len)) == NULL)
return -1;
else
{
line[len-1] = '\0'; // delete newline
strcpy(p, line);
lineptr[nlines++] = p;
}
return nlines;
}
// getline: read a line into s, return length
int getline(char s[], int lim)
{
int c, i;
for(i = 0; i < lim-1 && (c=getchar()) != EOF && c != '\n'; i++)
s[i] = c;
if(c == '\n')
{
s[i] = c;
++i;
}
s[i] = '\0';
return i;
}
// writelines: write output lines
void writelines(char *lineptr[], int nlines)
{
/* 数组方式:
int i;
for(i = 0; i < nlines; i++)
printf("%s\n", lineptr[i]);
*/
while(nlines-- > 0)
printf("%s\n", *lineptr++); // 注意这里的数组变量可以改变值
}
// qsort: sort v[left]...v[right] into increasing order
void qsort(char *v[], int left, int right)
{
int i, last;
void swap(char *v[], int i, int j);
if(left >= right) // do nothing if array contains
return; // fewer than two elements
swap(v, left, (left+right) / 2);
last = left;
for(i = left+1; i <= right; i++)
if(strcmp(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1);
qsort(v, last+1, right);
}
// swap: interchange v[i] and v[j]
void swap(char *v[], int i, int j)
{
char *temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
补充说明:输入函数收集和保存每个文本行中的字符,并建立一个指向这些文本行的指针数组。它同时还必须统计输入的行数,因为在排序和打印时要用到这一信息。由于输入函数只能处理有限数目的输入行,所以在输入行数过多而超过限定的最大行数时,该函数返回某个用于表示非法行数的数值,例如-1。
这个程序中,出现了一个很重要的概念:指针数组。指针数组lineptr的声明:char *lineptr[MAXLINES]; 表示lineptr 是一个具有MAXLINES 个元素的一维数组,其中数组的每个元素是一个指向字符类型对象的指针。即:lineptr[i] 是一个字符指针,*lineptr[i]是该指针指向的第i 个文本行的首字符。
70、多维数组
考虑一个日期转换问题:把某月某日这种日期表示形式与某年中第几天的表示形式相互转化。这两个函数都要用到一张记录每月天数的表。对闰年和非闰年来说,每个月的天数不同,所以,将这些天数分别存放到一个二维数组的两行中比在计算中判断2 月有多少天更容易:
static char daytab[2][13] = {
{0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},
{0, 31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}
};
// day_of_year: set day of year from month & day
int day_of_year(int year, int month, int day)
{
int i, leap;
leap = year%4 == 0 && year%100 != 0 || year%400 == 0;
for(i = 1; i < month; i++)
day += daytab[leap][i];
return day;
}
// month_day: set month, day from day of year
void month_day(int year, int yearday, int *pmonth, int *pday)
{
int i, leap;
leap = year%4 == 0 && year%100 != 0 || year%400 == 0;
for(i = 1; yearday > daytab[leap][i]; i++)
yearday -= daytab[leap][i];
*pmonth = i;
*pday = yearday;
}
这里之所以将daytab 的元素声明为char 类型,是为了说明char 类型的变量中存放较小的非字符整数也是合法的。二维数组实际上是一种特殊的一维数组,它的每一个元素也是一个一维数组。数组可以用花括号括起来的初值表进行初始化,二维数组的每一行由相应的子列表进行初始化。本例中,我们将数组daytab 的第一列元素设置为0,这样,每个月份包含天数对应的下标值为1-12,而不是0-11,由于在这里存储空间并不是主要问题,所以这种处理方式比在程序中调整数组的下标更加直观。
此外,如果将二维数组作为参数传递给函数,那么在函数的参数声明中必须指明数组的列数(一般来说,除数组的第一维(下标)可以不指定大小外,其余各维都必须明确指定大小)。因此,如果将数组daytab 作为参数传递给函数f,那么f 的声明应该改写成:f(int daytab[2][13]) {...} 或 f(int daytab[][13]) {...}。因为数组的行数无关紧要,所以,该声明还可以写成:f(int (*daytab)[13]) {...},注意,这种声明形式表明参数是一个指针,它指向具有13 个整形元素的一维数组。因为[] 的优先级高于* 的优先级,所以上述声明必须使用圆括号。如果去掉圆括号,声明变成 int *daytab[13],这相当于声明了一个数组,该数组有13 个元素,其中每一个元素都是一个指向整形对象的指针。
71、指针数组的初始化
考虑问题:编写一个函数month_name(n),它返回一个指向第n 个月名字的字符串的指针。这是内部static 类型数组的一种理想的应用。函数内部包含一个私有的字符串数组,当它被调用时,返回一个指向正确元素的指针:
// month_name: return name of n-th month
char *month_name(int n)
{
static char *name[] = {
"Illegal month",
"January", "February", "March",
"April", "May", "June",
"July", "August", "September",
"October", "November", "December"
};
return (n < 1 || n > 12) ? name[0] : name[n];
}
注意,这里name 是一个一维数组,数组的元素为字符指针。第i 个字符串的所有字符存储在存储器中的某个位置,指向它的指针存储在name[i] 中。由于上述声明中没有指明name 的长度,因此,编译器编译时将对初值个数进行统计,并将这一准确数字填入数组的长度。
72、指针与多维数组
对于C 语言的初学者而言,很容易混淆二维数组与指针数组之间的区别。以字符型为例,它们最大的区别是,二维数组存储空间是固定的,长度不可变。而指针数组最频繁的用处是存放不同长度的字符串,它的每一个元素所指向的字符串的长度可以不同。
73、命令行参数
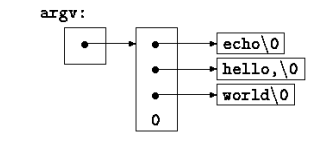
在C 语言中,调用主函数main 时,它带有两个参数。第一个是参数用于计数,其值表示运行程序时命令行中参数的数目,习惯上称为argc;第二个参数用于参数向量,是一个指向字符串数组的指针,其中每个字符串对应一个参数,习惯上称之为argv。我们用下面的程序echo.c 作为一个示例:
#include <stdio.h>
// echo command-line arguments; 1st version
int main(int argc, char *argv[])
{
int i;
for(i = 1; i < argc; i++)
printf("%s%s", argv[i], (i < argc-1) ? " " : "");
printf("\n");
return 0;
}
命令echo hello, world 将会打印输出:hello, world。
C 语言规定,argv[0] 是启动该程序的程序名。因此argc 是一个大于等于1 的整数,如果它的值恰好为1,说明程序名后面没有命令行参数。在上面的例子中,argc 的值为3,argv[0]、argv[1]、argv[2]的值如下图所示。这里,第一个可选参数是argv[1],最后一个可选参数是argv[argc-1]。另外,ANSI 标准要求argv[argc] 的值必须为一个空指针。
echo.c 程序的第二个版本如下:
#include <stdio.h>
// echo command-line arguments; 1st version
int main(int argc, char *argv[])
{
while(--argc > 0)
printf("%s%s", *++argv, argc > 1 ? " " : "");
return 0;
}
它通过指针而非数组下标的方式处理命令行参数。其中,打印命令行参数语句也可以改写成:
printf((argc > 1) ? "%s " : "%s", *++argv); 这说明,printf 的格式化参数也可以是表达式。
74、利用命令行参数增强36 中的模式查找程序的功能。原先的程序将查找模式内置到程序中,这种方法显然不能令人满意,而我们接下来改写的模式查找程序模仿UNIX的grep 实现方法,通过命令行的第一个参数指定待匹配的模式。
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
// find: print lines that match pattern from 1st arg
int main(int argc, char *argv[])
{
char line[MAXLINE];
int found = 0;
if(argc != 2)
printf("Usage: find pattern\n");
else
while(getline(line, MAXLINE) > 0)
if(strstr(line, argv[1]) != NULL)
{
printf("%s", line);
found++;
}
return found;
}
UNIX 系统的C 语言程序有一个公共的约定:以负号开头的参数表示一个可选标志或参数。为了进一步改进上面的模式查找程序,假定允许程序带两个可选的参数,用-x(除...之外)表示打印所有与模式不匹配的文本行,用-n(行号)表示打印行号,那么命令 find -x -n 模式 将打印所有与模式不匹配的行,并在每个打印行的前面加上行号。
可选参数应该允许以任意次序出现,同时,程序的其余部分应该与命令行中参数的数目无关。此外,如果可选参数能够组合使用,将会给使用者带来更大的方便,比如 find -nx 模式,改写后的程序如下:
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
int main(int argc, char *argv[])
{
char line[MAXLINE];
long lineno = 0;
int c, except = 0, number = 0, found = 0;
while(--argc > 0 && (*++argv)[0] == '-')
while(c == *++argv[0])
switch(c)
{
case 'x':
except = 1;
break;
case 'n':
number = 1;
break;
default:
printf("find: illegal option %c\n", c);
argc = 0;
found = -1;
break;
}
if(argc != 1)
printf("Usage: find -x -n pattern\n");
else
while(getline(line, MAXLINE) > 0)
{
lineno++;
if((strstr(line, *argv) != NULL) != except)
{
if(number)
printf("%ld:", lineno);
printf("%s", line);
found++;
}
}
return found;
}
这个程序可以帮助你很好地理解指针结构,如果遇到更复杂(很少有人使用比这更复杂的指针表达式)的指针表达式,可以将它们分为两步或三步来理解,这样会更直观一些。
在处理每个可选参数之前,argc 执行自减运算,argv 执行自增运算。循环语句结束时,如果没有错误,则argc 的值表示还没有处理的参数数目(我们期望这个数目是1,即未处理的参数是查找模式),而argv 则指向这些这些未处理参数中的第一个参数。因此,这是argc 的值应为1,而*argv 应该指向模式。注意,*++argv 是一个指向参数字符串的指针,因此(*++argv)[0] 是它的第一个字符(另一种有效形式是**++argv)。因为[] 与操作数的结合优先级比* 和++ 高,所以在上述表达式中必须使用圆括号,否则编译器将会把该表达式当作*++(argv[0])。实际上,我们在内层循环中就使用了表达式*++argv[0],其目的是遍历一个特定的参数串。在内层循环中,表达式*++argv[0] 对指针argv[0] 进行了自增运算。
75、指向函数的指针
C 语言中,函数本身不是变量,但可以定义指向函数的指针。这种类型的指针可以被赋值、传递给函数以及作为函数的返回值等等。我们通过修改前面的排序函数,来说明指向函数的指针的用法。在给定可选参数-n 的情况下,该函数将按值大小而非字典顺序对输入行进行排序。新版本的排序函数通过在排序算法中调用不同的比较和交换函数,便可以实现按照不同的标准排序。strcmp 按字典顺序比较两个输入行,我们还需要一个以数值为基础来比较两个输入行,并返回与strcmp 同样的比较结果的函数numcmp。这些函数在main 函数之前声明,并且,指向恰当函数的指针将被传递给qsort 函数。
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 // max #lines to be sorted
char *lineptr[MAXLINES]; // pointers to text lines
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void qsort(void *lineptr[], int left, int right, int (*comp)(void *, void *));
int numcmp(char *, char *);
// sort input lines
int main(int argc, char *argv[])
{
int nlines; // number of input lines read
int numeric = 0; // 1 if numeric sort
if(argc > 1 && strcmp(argv[1], "-n") == 0)
numeric = 1;
if((nlines = readlines(lineptr, MAXLINES)) >= 0)
{
qsort((void **)lineptr, 0, nlines-1, (int (*)(void*, void*))(numeric ? numcmp : strcmp));
writelines(lineptr, nlines);
return 0;
}
else
{
printf("input too big to sort\n");
return 1;
}
}
strcmp 和numcmp 是函数的地址。因为它们是函数,所以在调用函数qsort 的语句中,前面不需要加上取地址运算符&,这和数组名前面也不需要& 运算符一个道理。
注意,改写后的程序能够处理任何数据类型,而不仅仅限于字符串。从函数qsort 的原型中可以看出,它的参数表包括一个指针数组、两个整数和一个由两个指针参数的函数。其中,指针数组参数的类型为通用指针类型void *。由于任何类型的指针都可以转换为void * 类型,并且在它转换回原来的类型时不会丢失信息,所以,调用qsort 函数时可以将参数强制转换为void * 类型。比较函数的参数也要执行这种类型的转换。这种转换通常不会影响数据的实际表示,但要确保编译器不会报错。
// qsort: sort v[left]...v[right] into increasing order
void qsort(void *v[], int left, int right, int (*comp)(void *, void *))
{
int i, last;
void swap(void *v[], int, int);
if(left >= right) // do nothing if array contains
return; // fewer than two elements
swap(v, left, (left+right)/2);
last = left;
for(i = left+1; i <= right; i++)
if((*comp)(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1, comp);
qsort(v, last+1, right, comp);
}
仔细研究qsort 函数的第四个参数的声明:int (*comp)(void *, void *) ,它表明comp 是一个指向函数的指针,该函数有两个void * 类型的参数,其返回值类型为int。而语句 if((*comp)(v[i], v[left]) < 0) 的使用和其声明是一致的,comp 是一个指向函数的指针,*comp 代表一个函数。语句中的圆括号是必须的,这样才能保证其中的各个部分正确结合。如果没有括号,比如写成:int *comp(void *, void *) 则表明comp 是一个函数,该函数返回一个指向int 类型的指针,这显然违背了我们的本意。
以前介绍的strcmp 用于比较两个字符串的字典序。numcmp 也是比较两个字符串,但它通过调用atof 计算字符串对应的数值,然后在此基础上进行比较:
#include <stdlib.h>
// numcmp: compare s1 and s2 numerically
int numcmp(char *s1, char *s2)
{
double v1, v2;
v1 = atof(s1);
v2 = atof(s2);
if(v1 < v2)
return -1;
else if(v1 > v2)
return 1;
else
return 0;
}
void swap(void *v[], int i, int j)
{
void *temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
76、复杂声明
如何创建复杂的声明?下面的两个程序一个用于将正确的C 语言声明转换为文字描述,另一个完成相反的转换。程序dcl 基于声明符的语法编写,其简化语法形式为:
dcl: optional *'s direct-dcl direct-dcl name (dcl) direct-dcl() direct-dcl[optional size]
简言之,声明符dcl 就是前面可以带有多个* 的direct-dcl。direct-dcl 可以是name、由一对圆括号括起来的dcl、后面跟有一对圆括号的direct-dcl、后面跟有用方括号括起来表示可选长度的direct-dcl。使用该语法对C 语言的声明进行分析,如声明符(*pfa[])(),则pfa 将被识别为一个name,从而被认为是一个direct-dcl。于是,pfa[] 也是一个direct-dcl。接着,*pfa[] 被识别为一个dcl,因此判定(*pfa[]) 是一个direct-dcl。接着,(*pfa[])() 被识别为一个direct-dcl,因此也是一个dcl。可以用下图所示的语法分析树来说明分析的过程(其中direct-dcl 缩写为dir-dcl):
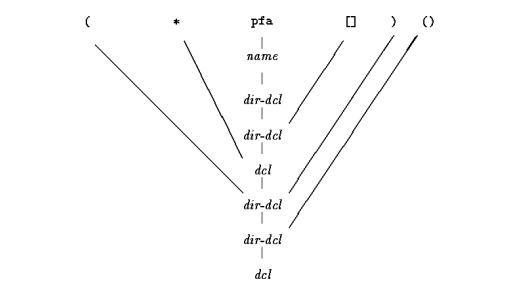
第一个程序dcl 复杂一些,它要做的事情就是将C 语言的声明转换为文字描述。如:
char ** argv argv: pointer to char int (*daytab)[13] daytab: pointer to array[13] of int int *daytab[13] daytab: array[13] of pointer to int void *comp() comp: function returning pointer to void void (*comp)() comp: pointer to function returning void void (*(*x[]())[])() x: function returning pointer to array[] of pointer to function returning char char (*(*x[3])())[5] x: array[3] of pointer to function returning pointer to array[5] of char
程序dcl 的核心是两个函数:dcl 与dirdcl,它们根据声明符的语法对声明进行分析。因为语法是递归定义的,所以在识别一个声明的组成部分时,这两个函数是相互递归调用的。我们称该程序是一个递归下降语法分析程序:
#include <stdio.h>
#include <string.h>
#include <ctype.h>
#define MAXTOKEN 100
enum { NAME, PARENS, BRACKETS };
void dcl(void);
void dirdcl(void);
int gettoken(void);
int tokentype; // type of last token
char token[MAXTOKEN]; // last token string
char name[MAXTOKEN]; // identifier name
char datatype[MAXTOKEN]; // data type = char, int, etc.
char out[1000];
int main(void)
{
while(gettoken() != EOF) // 1st token on line
{
strcpy(datatype, token); // is the datatype
out[0] = '\0';
dcl(); // parse rest of line
if(tokentype != '\n')
printf("syntax error\n");
printf("%s: %s %s\n", name, out, datatype);
}
return 0;
}
// dcl: parse a declarator
void dcl(void)
{
int ns;
for(ns = 0; gettoken() == '*'; ) // count *'s
ns++;
dirdcl();
while(ns-- > 0)
strcat(out, " pointer to");
}
// dirdcl: parse a direct declarstor
void dirdcl(void)
{
int type;
if(tokentype == '(') // (dcl)
{
dcl();
if(tokentype != ')')
printf("error: missing )\n");
}
else if(tokentype == NAME) // variable name
strcpy(name, token);
else
printf("error: expected name or (dcl)\n");
while((type=gettoken()) == PARENS || type == BRACKETS)
if(type == PARENS)
strcat(out, " function returning");
else
{
strcat(out, " array");
strcat(out, token);
strcat(out, " of");
}
}
// the function gettoken skips blanks and tabs, then finds the next token in the input; a "token" is a name, a pair of parentheses, a pair of brackets including a number, or any other single character.
int gettoken(void) // return next token
{
int c, getch(void); // getch and ungetch are discussed in the front of this essay
void ungetch(int);
char *p = token;
while((c = getch()) == ' ' || c == '\t')
;
if(c == '(')
{
if((c = getch()) == ')')
{
strcpy(token, "()");
return tokentype = PARENS;
}
else
{
ungetch(c);
return tokentype = '(';
}
}
else if(c == '[')
{
for(*p++ = c; (*p++ = getch()) != ']'; )
;
*p = '\0';
return tokentype = BRACKETS;
}
else if(isalpha(c))
{
for(*p++ = c; isalnum(c = getch()); )
*p++ = c;
*p = '\0';
ungetch(c);
return tokentype = NAME;
}
else
return tokentype = c;
}
另一个方向的转化要容易一些,为了简化输入,我们将"x is a function returning a pointer to an array of pointers to functions returning char"(x 是一个函数,它返回一个指针,该指针指向一个一维数组,该一维数组的元素为指针,这些指针分别指向多个函数,这些函数的返回值为char 类型)的描述用下列形式表示:x () * [] * () char,程序undcl 将把该形式转换为:char(*(*x())[])()。由于对输入的语法进行了简化,所以可以重用上面定义的gettoken 函数。undcl 和dcl 使用相同的外部变量:
// undcl: convert word descriptions to declarations
int main(void)
{
int type;
char temp[MAXTOKEN];
while(gettoken() != EOF)
{
strcpy(out, token);
while(type == gettoken() != '\n')
if(type == PARENS || type == BRACKETS)
strcat(out, token);
else if(type == '*')
{
sprintf(temp, "(*%s)", out);
strcpy(out, temp);
}
else if(type == NAME)
{
sprintf(temp, "%s %s", token, out);
strcpy(out, temp);
}
else
printf("invalid input at %s\n", token);
}
return 0;
}
77、结构的基本知识
我们可以用结构存放直角坐标系中一个点的坐标,关键字struct 引入结构声明:
struct point{
int x;
int y;
}
struct 后面的结构标记point 是可选的。结构标记用于为结构命名,在定义之后,结构标记就代表花括号内的声明,可以用它作为该声明的简写形式。结构成员(结构中定义的变量)、结构标记和普通变量可以采用相同的名字,因为可以通过上下文分析对它们进行区分,因此它们之间不会有冲突。
struct 声明定义了一种数据类型。struct { ... } x, y, z; 从语法角度来说,与基本类型的变量声明如 int x, y, z; 具有类似的意义。这两个声明都将x、y、z 声明为指定类型的变量,并且为它们分配存储空间。注意,如果结构声明的就后面不跟变量表,则不会为它分配存储空间,它仅仅描述了一个结构的模板或轮廓。但是,如果结构声明中带有结构标记,那么在以后定义结构实例时便可以使用该结构标记来定义。例如,对于上面给出的结构声明point,语句struct point pt; 定义了一个struct point 类型的变量pt。
结构可以嵌套。我们可以用对角线上的两个点来定义矩形。相应的结构定义为:
struct rect{
struct point pt1;
struct point pt2;
}
78、结构与函数
来看一个例子,函数prinrect 判断一个点是否在给定的矩形内部。我们采用这样一个约定:矩形包括其左侧边和底边,但不包括顶边和右侧边。程序如下:
// ptinrect: return 1 if p in r, 0 if not
int ptinrect(struct point p, struct rect r)
{
return p.x >= r.pt1.x && p.x < r.pt2.x
&& p.y >= r.pt1.y && p.y < r.pt2.y;
}
这里假设矩形是用标准形式表示的,其中pt1 的坐标小于pt2 的坐标。下列函数将返回一个规范形式的矩形:
#define min(a, b) ((a) < (b) ? (a) : (b))
#define max(a, b) ((a) > (b) ? (a) : (b))
// canonrect: canonicalize coordinates of rectangle
struct rect canonrect(struct rect r)
{
struct rect temp;
temp.pt1.x = min(r.pt1.x, r.pt2.x);
temp.pt1.y = min(r.pt1.y, r.pt2.y);
temp.pt2.x = max(r.pt1.x, r.pt2.x);
temp.pt2.y = max(r.pt1.y, r.pt2.y);
return temp;
}
如果传递给函数的结构很大,使用指针方式的效率通常比复制整个结构的效率要高。声明 struct point *pp; 将pp 定义为一个指向struct point 类型对象的指针。在所有运算符中,结构运算符"." 和"->"、用于函数调用的"()" 以及用于下标的"[]" 这四个运算符的优先级最高。例如,对于结构声明:
struct {
int len;
char *str;
} *p;
因为表达式++p->len 隐含的括号关系是++(p->len),所以++p->len 将增加len 而不是p 的值。可以通过使用括号改变结合次序。例如:(++p)->len 将先执行p 的加1 操作,在对len 执行操作;而(p++)->len 则先对len 执行操作,然后再将p 加1(该表达式中的括号可以省略)。
同样的道理,*p->str 读取的是指针str 所指向的对象的值:*p->str++ 先读取指针str 所指向的对象的值,然后再将str 加1(与*s++ 相同);(*p->str)++ 将指针str 指向的对象的值加1;*p++->str 先读取指针str 指向的对象的值,然后再将p 加1。
79、结构数组
考虑编写一个用来统计输入中各个C 语言关键字出现次数的程序,我们需要用一个字符串数组存放关键字名,一个整型数组存放相应关键字的出现次数。一种实现方法是使用两个独立的数组分别存放它们,如:char *keyword[NKEYS]; int keycount[NKEYS]; 考虑到两个数组之间联系密切,大小相同的特点,可以采用另一种不同的组织方式——结构数组:
struct key {
char *word;
int count;
} keytab[NKEYS];
因为结果keytab 包含一个固定的名字集合,因此最好将它声明为外部变量,这样,只需要初始化一次,所有的地方都可以使用:
struct key {
char *word;
int count;
} keytab[] = {
{ "auto", 0 },
{ "break", 0 },
{ "case", 0 },
{ "char", 0 },
{ "const", 0 },
{ "continue", 0 },
{ "default", 0 },
/* ... */
{ "unsigned", 0 },
{ "void", 0 },
{ "volatile", 0 },
{"while", 0 }
};
通常情况下,如果初值存在并且方括号[] 中没有数值,编译程序将计算数组keytab 中的项数。
在统计关键字出现次数的程序中,我们首先定义了keytab。主程序反复调用函数getword 读取输入,每次读取一个单词。每个单词将通过折半查找函数在keytab 中进行查找。注意,关键字列表必须按升序存储在keytab 中。程序核心如下:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
int getword(char *, int);
int binsearch(char *, struct key *, int);
// count C keywords
int main(void)
{
int n;
char word[MAXWORD];
while(getword(word, MAXWORD) != EOF)
if(isalpha(word[0]))
if((n = binsearch(word, keytab, NKEYS)) >= 0)
keytab[n].count++;
for(n = 0; n < NKEYS; n++)
if(keytab[n].count > 0)
printf("%4d %s\n", keytab[n].count, keytab[n].word);
return 0;
}
// binsearch: find word in tab[0]...tab[n-1]
int binsearch(char *word, struct key tab[], int n)
{
int cond;
int low, high, mid;
low = 0;
high = n - 1;
while(low <= high)
{
mid = (low+high) / 2;
if((cond = strcmp(word, tab[mid].word)) < 0)
high = mid -1;
else if(cond > 0)
low = mid + 1;
else
return mid;
}
return -1;
}
// getword: get next word or character from input
int getword(char *word, int lim)
{
int c, getch(void); // there have concreate implements in the front of this essay
void ungetch(int);
char *w = word;
while(isspace(c = getch()))
;
if(c != EOF)
*w++ = c;
if(!isalpha(c))
{
*w = '\0';
return c;
}
for(; --lim > 0; w++)
if(!isalnum(*w = getch()))
{
ungetch(*w);
break;
}
*w = '\0';
return word[0];
}
NKEYS 代表keytab 中关键字的个数。尽管可以手工计算,但无疑由机器实现会更简单且安全,当列表可能变更时尤其如此。一种解决办法是,在初值表的结尾处加上一个空指针,然后循环遍历keytab,直到读到尾部的空指针为止。但实际上并不需要这样做,因为数组的长度在编译时已经完全确定,它等于数组项的长度除以项数(Keytab 的长度 / struct key 的长度),因此我们可以利用C 语言提供的一个编译时(compile-time)一元运算符sizeof,它可用来计算任一对象的长度。表达式sizeof 对象 以及 sizeof(类型名) 将返回指定对象(变量、数组或结构)或类型(可以是基本类型,如:int、double,也可以是派生类型,如结构类型或指针类型)占用的存储空间字节数,它是一个无符号整型值,类型为size_t(在<stddef.h> 中定义)。 我们可以用以下两种方法设置NKEYS 的值:
#define NKEYS (sizeof keytab / sizeof(struct key)) #define NKEYS (sizeof keytab / sizeof(keytab[0]))
使用第二种方法,即使类型名改变了,也不需要改动程序。
再来看一下getword 函数。这里给出的是一个更通用的getword 函数。getword 从输入读取下一个单词,单词可以是以字母开头的字母和数字串,也可以是一个非空白字符。函数返回值可能是单词的第一个字符,文件结束符EOF 或字符本身(如果该字符不是字母字符的话)。getword 函数除了使用了前文中定义的getch 和ungetch 函数之外,还使用了头文件<ctype.h> 中的一些函数:用isspace 函数跳过空白符,isalpha 函数来识别字母,isalnum 识别字母和数字。
80、指向结构的指针
为了说明指向结构的指针的用法,我们采用指针而不是数组下标的方式重新编写79 中的关键字统计程序:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
int getword(char *, int);
struct key *binsearch(char *, struct key *, int);
// count C keywords; pointer version
int main(void)
{
char word[MAXWORD];
struct key *p;
while(getword(word, MAXWORD) != EOF)
if(isalpha(word[0]))
if((p = binsearch(word, keytab, NKEYS)) != NULL)
p->count++;
for(p = keytab; p < keytab + NKEYS; p++)
if(p->count > 0)
printf("%4d %s\n", p->count, p->word);
return 0;
}
// binsearch: find word in tab[0]...tab[n-1]
struct key * binsearch(char *word, struct key *tab, int n)
{
int cond;
struct key *low = &tab[0];
struct key *high = &tab[n];
struct key *mid;
while(low < high)
{
mid = low + (high-low) / 2;
if(cond = strcmp(word, mid->word) < 0)
high = mid;
else if(cond > 0)
low = mid + 1;
else
return mid;
}
return NULL;
}
这里,binsearch 函数返回与输入单词匹配的指向struct key 类型的相应元素的指针,不匹配返回NULL。keytab 的元素在这里通过指针访问。low 和high 的初值分别是指向表头元素的指针和指向表尾元素后面的一个元素的指针。这样,因为指针之间的加法运算是非法的,所以我们就无法通过mid = (low+high) / 2 来计算中间元素的位置。但是,指针的减法运算却是合法的,high-low 的值就是数组元素的个数,因此可以通过表达式mid = low + (high-low) / 2 将mid 设置为指向high 和low 之间的中间元素的指针。
对算法的最重要的修改要确保不会生成非法的指针,或者试图访问数组范围之外的元素。问题在于,&tab[-1] 和&tab[n] 都超出了数组tab 的范围。前者是绝对非法的,而后者的间接引用也是非法的。但是C 语言的定义保证数组末尾之后的第一个元素(即&tab[n])的指针算术运算可以正确执行。
此外,不要认为结构的长度等于各成员长度的和。因为不同的对象有不同的对齐要求。所以,结构中可能会出现未命名的"空穴"(hole)。这样,假设char 类型占用一个字节,int 类型占用四个字节,那么结构struct {char c; int i;}; 可能需要8 个字节的存储空间,而不是5 个。使用sizeof 运算符可以返回正确的对象长度。
81、自引用结构(词频统计)
考虑一个更一般化的问题:统计输入中所有单词的出现次数。因为预先不知道出现的单词列表,所以无法方便地排序,并使用折半查找;也不能分别对输入中的每个单词都执行一次线性查找,看它在前面是否已经出现,这样做,程序的执行将花费太长的时间(O(n^2))。那么问题的关键就是,我们该如何组织数据,才能有效处理一系列任意的单词呢?
一种解决方案是,在读取输入中任意单词的同时,就把它放置到正确的位置,从而始终保证所有单词是按顺序排列的。虽然这可以不用通过在线性数组中移动单词来实现,但它仍然会导致程序执行的时间过长。我们可以使用一种称为二叉树的数据结构来取而代之。每个不同的单词在树中都是一个节点,每个节点包含:
- 一个指向该单词内容的指针
- 一个统计出现次数的计数值
- 一个指向左子树的指针
- 一个指向右子树的指针
任何节点最多有两个子树,也可能只有一个子树或一个都没有。对节点的所有操作要保证,任何节点的左子树只包含按字典序小于该节点中单词的那些单词,右子树只包含按字典序大于该节点中单词的那些单词。要查找一个新单词是否已经在树中,可以从根节点开始,比较新单词与该节点中的单词。若匹配,则得到肯定的答案。若新单词小于该节点中的单词,则在左子树中继续查找,否则在右子树中查找。如在搜寻方向上无子树,则说明新单词不在树中,并且,当前的空位置就是存放新加入单词的正确位置。因为从任意节点出发的查找都要按照同样的方式查找它的一个子树,所以该过程是递归的。相应地,在插入和打印操作中使用递归过程也是很自然的事情。
再来看节点的表示方法,最方便的无疑是表示为包括4 个成员的结构:
struct tonde { // the tree node:
char *word; // points to the text
int count; // number of occurrences
struct tnode *left; // left child
struct tnode *right; // right child
};
包含实例自身的结构是非法的,但是struct tnode *left; 是合法的,它将left 声明为指向tnode 的指针,而不是tnode 实例本身。主程序main 的代码非常短小,通过getword(前面编写过)读入单词,并通过addtree 函数将它们插入到树中:
#include <stdio.h>
#include <ctype.h>
#include <string.h>
#define MAXWORD 100
struct tnode *addtree(struct tnode *, char *);
void treeprint(struct tnode *);
int getword(char *, int);
// word frequency count
int main(void)
{
struct tnode *root;
char word[MAXWORD];
root = NULL;
while(getword(word, MAXWORD) != EOF)
if(isalpha(word[0]))
root = addtree(root, word);
treeprint(root);
return 0;
}
函数addtree 是递归的。主程序以参数的方式传递给该函数的第一个单词将作为树的最顶层(即树的根)。在每一步中,新单词与节点中存储的单词进行比较,随后,通过函数调用addtree 而转向左子树或右子树。该单词最终将与树中的某节点匹配(这种情况下计数值加1)或遇到一个空指针(表明必须创建一个节点并加入到树中)。若生成了新节点,则addtree 返回一个指向新节点的指针,该指针保存在新节点的父节点中。程序的剩余部分如下:
struct tnode *talloc(void);
char *strdup(char *);
// addtree: add a node with w, at or below p
struct tnode *addtree(struct tnode *p, char *w)
{
int cond;
if(p == NULL) // a new word has arrived
{
p = talloc(); // make a new node
p->word = strdup(w);
p->count = 1;
p->left = p->right = NULL;
}
else if((cond = strcmp(w, p->word)) == 0)
p->count++; // repeated word
else if(cond < 0) // less than into left subtree
p->left = addtree(p->left, w);
else // greater than into right substree
p->right = addtree(p->right, w);
return p;
}
#include <stdlib.h>
// talloc: make a tnode
struct tnode *talloc(void)
{
return (struct tnode *)malloc(sizeof(struct tnode));
}
char *strdup(char *s) // make a duplicate of s
{
char *p;
p = (char *)malloc(strlen(s)+1); // +1 for '\0'
if(p != NULL)
strcpy(p, s);
return p;
}
// treeprint: in-order print of tree p
void treeprint(struct tnode *p)
{
if(p != NULL)
{
treeprint(p->left);
printf("%4d %s\n", p->count, p->word);
treeprint(p->right);
}
}
新节点的存储空间由子程序talloc 获得。函数strdup 将新单词复制到某个特殊位置。增加新节点时,代码只在树叶部分执行,计数值被初始化为1,两个子树被置空。此外,addtree 程序忽略了对strdup 和talloc 返回值得出错检查(显然是不完善的)。
treeprint 函数按顺序打印树。在每个节点上,它先打印左子树(小于该单词的所有单词),然后是该单词本身,最后是右子树(大于该单词的所有单词)。这里有一点值得注意:如果单词不是随机分布的,树将变得不平衡,这种情况下,程序的运行时间将大大增加。最坏的情况下,若单词已经排好序,则程序模拟线性查找的开销将非常大。某些广义二叉树不受这种最坏情况的影响,在此我们不予讨论。
在C 语言中,malloc 函数(在标准头文件<stdlib.h> 中声明)的返回值声明为一个指向void 类型的指针(这种设计方案使得该函数能够返回不同类型的指针),然后我们需要做的事情就是将该指针显式地转换为所需类型。在没有可用空间时,malloc 函数返回NULL,同时,strdup 函数也将返回NULL,strdup 函数的调用者负责出错处理。调用malloc 函数得到的存储空间可以通过调用free 函数释放以重用。
82、散列表查找
下面的表查找程序包的核心部分代码可便于我们对结构的更多方面进行深入的探讨。这部分典型的代码可以在宏处理器或编译器的符号表管理例程中找到。例如,考虑#define 语句,当遇到# define IN 1 之类的语句时,就需要把名字IN 和替换文本1 存入到某个表中。此后,当名字IN 出现在某些语句中时,如:state = IN 就必须用1 来替换IN。
函数install 和lookup 分别用来处理名字和替换文本。install(s, t) 函数将名字s 和替换文本t 记录到某个表中,其中s 和t 均为字符串。lookup(s) 函数在表中查找s,若找到,则返回指向该处的指针;若没找到,则返回NULL。
算法采用散列查找方法——将输入的名字转换为一个小的非负整数,该整数随后将作为一个指针数组的下标。数组的每个元素指向某个链表的表头,链表中的各个块用于描述具有该散列值的名字。如果没有名字散列到该值,则数组元素的值为NULL。
链表中的每个块都是一个结构,它包含一个指向名字的指针、一个指向替换文本的指针以及一个指向该链表后继块的指针。如果指向链表后继块的指针为NULL,则表明链表结束。程序核心如下:
struct nlist { // table entry:
struct nlist *next; // next entry in chain
char *name; // defined name
char *defn; // replacement text
};
#define HASHSIZE 101
static struct nlist *hashtab[HASHSIZE]; // pointer table
// hash: from hash value for string s
unsigned hash(char *s)
{
unsigned hashval;
for(hashval = 0; *s != '\0'; s++)
hashval = *s + 31 * hashval;
return hashval % HASHSIZE;
}
// lookup: look for s in hashtab
struct nlist *lookup(char *s)
{
struct nlist *np;
for(np = hashtab[hash(s)]; np != NULL; np = np->next)
if(strcmp(s, np->name) == 0)
return np; // found
return NULL; // not found
}
char *strdup(char *);
// install: put (name, defn) in hashtab
struct nlist *install(char *name, char *defn)
{
struct nlist *np;
unsigned hashval;
if((np = lookup(name)) == NULL) // not found
{
np = (struct nlist *)malloc(sizeof(*np));
if(np == NULL || (np->name = strdup(name)) == NULL)
return NULL;
hashval = hash(name);
np->next = hashtab[hashval];
hashtab[hashval] = np;
}
else // already there
free((void *)np->defn); // free previous defn
if((np->defn = strdup(defn)) == NULL)
return NULL;
return np;
}
// strdup: make a duplicate of s
char *strdup(char *s)
{
char *p;
p = (char *)malloc(strlen(s)+1); // +1 for '\0'
if(p != NULL)
strcpy(p, s);
return p;
}
散列函数hash 在lookup 和install 函数中都被用到,它通过一个for,每次循环将上一次循环计算得到的结果值经过变换(乘以31)后得到的新值同字符串中当前字符的值相加,然后将该结果值同数组长度执行取模操作,其结果作为该函数的返回值。这可能不是最好的散列函数,但是简短有效。同时,无符号算术运算保证了散列值非负。
散列过程生成了在数组hashtab 中执行查找的起始下标。如果该字符串可以被查找到,则它一定位于该起始下标指向的链表的某个块中。具体查找过程由lookup 函数实现。如果lookup 函数发现表项已存在,则返回指向该表项的指针,否则返回NULL。lookup 函数中的for 循环是遍历一个链表的标准方法。
install 函数借助lookup 函数判断待加入的名字是否已经存在。如果已存在,则用新的定义取代;否则,创建一个新表项。如无足够空间创建一个新表项,则install 函数返回NULL。
83、类型定义:typedef
C 语言提供了一个称为typedef 的功能,它用来建立新的数据类型名。例如,声明typedef char* String 将String 定义为与char* 具有同等意义的名字。类型String 可用于类型声明、类型转换等,它和类型char* 完全相同。这里我们以大写字母作为typedef 定义的类型名的首字母,以示区别。用typedef 定义前面介绍的树节点:
typedef struct tnode *Treeptr;
typedef struct tnode { // the tree node:
char *word; // points to the text
int count; // number of occurrences
struct tnode *left; // left child
struct tnode *right; // right child
} Treenode;
这个类型定义创建了两个新类型关键字:Treenode(一个结构)和Treeptr(一个指向该结构的指针)。这样,函数talloc 可相应地修改为:
Treeptr talloc(void)
{
return (Treeptr)malloc(sizeof(Treenode));
}
需要强调的一点是,从任何意义上来说,typedef 声明并没有创建一个新类型,它只是为某个已存在的类型增加了一个新的名称而已,它与通过普通声明方式声明的变量具有完全相同的属性。实际上,typedef 类似于#define 语句,但由于typedef 是由编译器解释的,因此它的文本替换功能要超过预处理器的能力。例如:typedef int (*PEI)(char *, char *); 定义了类型PEI 是"一个指向函数的指针,该函数具有两个char * 类型的参数,返回值类型为int"。
除了表达方式更简洁之外,使用typedef 还有两个重要原因:首先,它可以是程序参数化,以提高程序的可移植性。如果typedef 声明的数据类型同机器有关,那么当程序移植到其它机器上时,只需要改变typedef 类型定义就可以了。一个经常用到的情况是,对于各种不同大小的整型值来说,都使用通过typedef 定义的类型名,然后,分别为各个不同的宿主机选择一组合适的short、int 和long 类型大小即可。标准库中有一些例子,例如size_t 和ptrdiff_t 等;其次,它为程序提供更好的说明性,Treeptr 类型显然比一个声明为指向复杂结构的指针更容易让人理解。
84、联合
联合提供了一种在单块存储区中管理不同类型数据的方式,而不需要在程序中嵌入任何同机器有关的信息,编译器负责跟踪对象的长度和对齐要求。其语法基于结构,如:
union u_tag {
int ival;
float fval;
char *sval;
} u;
变量u 必须足够大,以保存这3 种类型中最大的一种,具体长度同具体的实现有关。虽然这些类型中的任何一种类型的对象都可以赋值给u,但必须保证保存的类型与读取的类型一致,程序员负责跟踪当前保存在联合中的类型。如果不一致,其结果取决于具体的实现。访问联合中的成员与访问结构的方式相同。如果用变量utype 跟踪保存在u 中的当前数据类型,则可以像下面这样使用联合:
if(utype == INT)
printf("%d\n", u.ival);
if(utype == FLOAT)
printf("%f\n", u.fval);
if(utype == STRING)
printf("%s\n", u.sval);
else
printf("bad type %d in utype\n", utype);
联合可以使用在结构和数组中,反之亦可。如结构数组定义为:
struct {
char *name;
int flags;
int utype;
union {
int ival;
float fval;
char *sval;
} u;
} symtab[NSYM];
则可以使用symtab[i].u.ival 来引用成员ival,也可以通过*symtab[i].u.sval 或symtab[i].u.sval[0] 来引用字符串sval 的第一个字符。
实际上,联合就是一个结构,它的所有成员相对于基地址的偏移量都为0,此结构空间要大到足够容纳最"宽"的成员,并且,对齐方式要适合于联合中所有类型的成员。需要注意的一点:联合只能用其第一个成员类型的值进行初始化,因此,上述联合u 只能用整数值进行初始化。
85、输入输出基本概念
- 输入/输出功能并不是C 语言本身的组成部分。如果程序的系统交互部分仅仅使用了标准库提供的功能,则可以不经修改地从一个系统移植到另一个系统中。
- 标准库实现了简单的文本输入/输出模式。文本流由一系列行组成,每一行的结尾是一个换行符。如果系统没有遵循这种模式,则标准库将通过一些措施使得该系统适应这种模式。例如,标准库可以在输入端将回车和换行符都转换为换行符,而在输出端进行反向转换。
- 在许多环境中,可以使用符号< 来实现输入重定向,它将把键盘输入替换为文件输入,如果程序prog 中使用了函数getchar,则命令行prog < infile 将使得程序prog 从输入文件infile 而不是从键盘中读取字符。实际上,程序prog 本身并不在意输入方式的改变,并且,字符串"<infile" 也并不包含在argv 的命令行参数中。也可以使用">filename" 将输出重定向到某个文件中。
- 如果输入通过管道机制来自于另一个程序,那么这种输入切换也是不可见的。比如,在某些系统中,命令行:otherprog | prog 将运行两个程序otherprog 和prog,并将otherprog 的标准输出通过管道重定向到程序prog 的标准输入上。
- 函数printf 和putchar 均向标准输出设备(默认为屏幕)输出数据。我们可以在程序中交叉调用两者,输出将按照函数调用的先后顺序依次产生。
使用输入/输出库函数的每个源程序文件必须在引用这些函数之前包含语句:#include <stdio.h>。考虑程序lower,它用于将输入转换为小写字母的形式:
#include <stdio.h>
#include <ctype.h>
// lower: convert input to lower case
int lower()
{
int c;
while((c = getchar()) != EOF)
putchar(tolower(c));
return 0;
}
函数tolower 在头文件<ctype.h> 中定义,它把大写字母转换为小写形式,并把其它字符原样返回。tolower "函数"和头文件<stdio.h> 中的getchar、putchar "函数"一般都是宏,这样就避免了对每个字符进行函数调用的开销。
86、格式化输出
输出函数printf 将内部数值转换为字符的形式。原型声明如下:
int printf(char *format, arg1, arg2, ...);
该函数在输出格式format 的控制下,将其参数进行转换与格式化,并在标准输出设备上打印出来。它的返回值为打印的字符数。
在转换说明中,宽度或精度可以用星号* 表示,这时,宽度或精度的值通过转换下一参数(必须为int 类型)来计算。例如,为了从字符串s 中打印最多max 个字符,可以使用语句:printf("%.*s", max, s);
下表说明了在打印字符串"hello, world"(12 个字符)时根据不同的转换说明产生的不同结果。我们在每个字段的左边和右边加上冒号,这样可以清晰地表示出字段的宽度。

显示的结果中需要解释的有以下几点:
负号:用于指定被转换的参数按照左对齐的形式输出;小数点:用于将字段宽度和精度分开;小数点前面的数:用于指定最小字段宽度,转换后的参数将打印不小于最小字段宽度的字段。如果有必要,字段左边(如果使用左对齐的方式,则为右边)多余的字符位置用空格填充以保证最小字段宽度;小数点后面的数:用于指定精度,即指定字符串中要打印的最大字符数、浮点数小数点后的位数、整型最小输出的数字数目。
注意:函数printf 使用第一个参数判断后面参数的个数及类型。如果参数的个数不够或者类型错误,则将得到错误的结果。请注意下面两个函数调用之间的区别(你可以自己写个程序验证一下):
printf(s); // FAILS if s contains %
printf("%s", s); // SAFE
函数sprintf 执行的转换和函数printf 相同,但它将输出保存到一个字符串中,而不是输出到标准输出中。当然,这个字符串必须足够大以存放输出结果:
int sprintf(char *string, char *format, arg1, arg2, ...);
87、变长参数表
我们以实现printf 函数的一个最简单版本为例,介绍如何以可移植的方式编写可处理变长参数表的函数。因为这里我们的重点在于参数的处理,所以,函数minprintf 只处理格式字符串和参数,格式转换则通过函数printf 实现。函数printf 的正确声明形式为:int printf(char *fmt, ...),其中省略号表示参数的数量和类型是可变的。省略号表示参数表中的参数的数量和类型是可变的。省略号只能出现在参数表的尾部。因为minprintf 函数不需要像printf 函数一样返回实际输出的字符数。因此,我们将它声明为:void minprintf(char *fmt, ...)。
编写函数minprintf 的关键在于如何处理一个甚至连名字都没有的参数表。标准头文件<stdarg.h> 中包含一组宏定义,它们对如何遍历参数表进行了定义。该头文件的实现因不同的机器而不同,但提供的接口是一致的。
va_list 类型用于声明一个变量,该变量将依次引用各参数。在函数minprintf 中,我们将该变量称为ap,意思是"参数指针"。宏va_start 将ap 初始化为指向第一个无名参数的指针。在使用ap 之前,该宏必须被调用一次。参数表必须至少包含一个有名参数。
每次调用va_arg,该函数都将返回一个参数,并将ap 指向下一个参数,va_arg 使用一个类型名来决定返回的对象类型、指针移动的步长。最后,必须在函数返回之前调用va_end,以完成一些必要的清理工作。
基于以上讨论,我们实现的简化printf 函数如下:
#include <stdarg.h>
// minprintf: minimal printf with variable argument list
void minprintf(char *fmt, ...)
{
va_list ap; // points to each unnamed arg in turn
char *p, *sval;
int ival;
double dval;
va_start(ap, fmt); // make an point to 1st unamed arg
for(p = fmt; *p; p++)
{
if(*p != '%')
{
putchar(*p);
continue;
}
switch(*++p)
{
case 'd':
ival = va_arg(ap, int);
printf("%d", ival);
break;
case 'f':
dval = va_arg(ap, double);
printf("%f", dval);
break;
case 's':
for(sval = va_arg(ap, char *); *sval; sval++)
putchar(*sval);
break;
default:
putchar(*p);
break;
}
}
va_end(ap); // clean up when done
}
88、格式化输入
输入函数scanf 对应于输出函数printf,在与后者相反的方向上提供同样的转换功能。具有变长参数表的函数scanf 的声明为:int scanf(char *format, ...),该函数从标准输入中读取字符序列,按照format 中的格式说明对字符序列进行解释,并把结果保存到其余的参数中,所有的参数都必须是指针,用于指定经格式转换后的相应输入保存的位置。
当scanf 函数扫描完其格式串,或者碰到某些输入无法与格式控制说明匹配的情况时,该函数终止,同时,成功匹配并赋值的输入项的个数将作为函数值返回。没有匹配项的话,scanf 将返回0,下一次调用scanf 将从上一次转换的最后一个字符的下一个字符开始继续搜索。如果到达文件结尾,该函数将返回EOF。
输入函数sscanf 从一个字符串中读取字符序列:
int sscanf(char *string, char *format, arg1, arg2, ...)
scanf 越过空白符(空白符包括空格符、横向制表符、换行符、回车符、纵向制表符、换页符)读取输入。
假设我们要读取包含这种日期格式的输入行,即:25 Dec 1998,相应的scanf 语句可以这样编写:
int day, year;
char monthname[20];
scanf("%d %s %d", &day, monthname, &year);
使用scanf 语句读入形如 mm/dd/yy 的日期数据:
int day, month, year;
scanf("%d/%d/%d", &month, &day, &year);
如果要读取格式不固定的输入,最好每次读入一行,然后再用sscanf 将合适的格式分离出来读入。例如,假定我们需要读取一些包含日期数据的输入行,日期的格式可能是上述任一种形式。我们可以这样编写程序:
while(getline(line, sizeof(line)) > 0)
{
if(sscanf(line, "%d %s %d", &day, monthname, &year) == 3)
printf("valid: %s\n", line); // 25 Dec 1988 form
else if(sscanf(line, "%d%d%d", &month, &day, &year) == 3)
printf("valid: %s\n", line); // mm/dd/yy form
else
printf("invalid: %s\n", line); // invalid form
}
scanf 函数可以和其它输入函数混合使用。无论调用哪个输入函数,下一个输入函数的调用将从scanf 没有读取的第一个字符处开始读取数据。
注意,scanf 和sscanf 函数的所有参数必须都是指针。最常见的错误是将输入语句写成scanf("%d", n); 正确的形式应该为scanf("%d", &n); 编译器在编译时一般检测不到这类错误。
89、文件访问
考虑编写一个访问文件的程序cat,它把一批命名文件串联后输出到标准输出上。例如,命令行cat x.c y.c 将在标准输出上打印文件x.c 和y.c 的内容。问题是,如何设计命名文件的读取过程呢?方法很简单,在读写一个文件之前,必须通过库函数fopen 打开该文件。fopen 用文件的文件名与操作系统进行某些必要的通信(我们不必关心这些细节),并返回一个随后可以用于文件读写操作的文件指针,它指向一个包含文件信息的结构,这些信息包括:缓冲区的位置、缓冲区中当前字符的位置、文件的读或写状态、是否出错、是否已到达文件结尾等等。我们不必关系这些细节,因为<stdio.h> 中已经定义了一个包含这些信息的结构FILE。在程序中只需要声明一个文件指针(FILE *fp),然后调用fopen 函数(FILE *fopen(char *name, char *mode))即可。fopen 的第一个参数是一个包含文件名的字符串。第二个参数也是字符串,代表访问模式。允许的模式有:读("r")、写("w")及追加("a")。某些系统还区分文本文件和二进制文件,对后者的访问需要在模式字符串中增加字符"b"。
如果打开一个不存在的文件用于写或追加,给文件将被创建(如果可能的话)。当以写的方式打开一个已经存在的文件时,该文件原来的内容将被覆盖。但是,如果以追加方式打开一个文件,则该文件原来的内容保留不变。读一个不存在的文件会导致错误,其它一些操作也可能导致错误,比如试图读取一个无读取权限的文件。如果发生错误,fopen 将返回NULL。
文件打开后,有多种方法可以对其进行读写。最简单的是getc 和putc 函数。getc 从文件中返回下一个字符,他需要知道文件指针,以确定对哪个文件执行操作:int getc(FILE *fp),getc 函数返回指向的输入流中的下一个字符。如果到达文件尾或出现错误,该函数将返回EOF。putc 是一个输出函数:int puts(int c, FILE *fp) 该函数将字符c 写到fp 指向的文件中,并返回写入的字符。如果发生错误,返回EOF。类似于getchar 和putchar,getc 和putc 是宏而不是函数。
启动一个C 语言程序时,操作系统环境负责打开3 个文件,并将这3 个文件的指针提供给该程序。这三个文件分别是标准输入、标准输出和标准错误,相应的文件指针分别为stdin、stdout 和stderr,它们在<stdio.h> 中声明。在大多数环境中,stdin 指向键盘,而stdout 和stderr 指向显示器。stdin 和stdout 都可以被重定向到文件或管道。
getchar 和putchar 函数可以通过getc、putc、stdin 及stdout 定义如下:
#define getchar() getc(stdin) #define putchar(c) putc(c, stdout)
函数fscanf 和fprintf 对文件进行格式化输入或输出。它们与scanf 和printf 函数的区别仅仅在于它们的第一个参数是一个指向所要读写的文件的指针。
掌握以上预备知识之后,我们现在就可以编写出将多个文件连接起来的cat 程序了。改程序的设计思路和其它许多程序类似。如果有命令行参数,参数将被解释为文件名,并按顺序逐个处理。如果没有参数,则处理标准输入。
#include <stdio.h>
// cat: concatenate files, version 1
int main(int argc, char *argv[])
{
FILE *fp;
void filecopy(FILE *, FILE *);
if(argc == 1) // no args; copy standard input
filecopy(stdin, stdout);
else
while(--argc > 0)
if((fp = fopen(*++argv, "r")) == NULL)
{
printf("cat: can't open %s\n", *argv);
return 1;
}
else
{
filecopy(fp, stdout);
fclose(fp);
}
return 0;
}
// filecopy: copy file ifp to file ofp
void filecopy(FILE *ifp, FILE *ofp)
{
int c;
while((c = getc(ifp)) != EOF)
putc(c, ofp);
}
注意:文件指针stdin 和stdout 都是FILE* 类型的对象。但它们是常量,而非变量(可以看一下它们在头文件<stdio.h> 中是如何定义的)。因此不能对它们赋值。
函数int fclose(FILE *fp) 执行和fopen 相反的操作,它断开由fopen 函数建立的文件指针和外部名之间的连接,并释放文件指针以供其它文件使用。因为大多数操作系统都限制了一个程序可以同时打开的文件数,所以,当文件指针不再需要时就应该释放,这是一个好的编程习惯。对输出文件执行fclose 还有另外一个原因:它将把缓冲区中由putc 函数正在收集的输出写到文件中。当程序正常终止时,程序会自动为每个打开的文件调用fclose 函数(如果不需要使用stdin 和stdout,可以把它们关闭掉。也可以通过库函数freopen 重新指定它们)。
90、错误处理:stderr 和exit
89 条中的cat 程序的错误处理功能并不完善。问题在于,如果因为某种原因造成其中一个文件无法访问,相应地诊断信息要在该连接的输出的末尾才能打印出来。当输出到屏幕时,这种处理方法尚可以接受,但如果输出到一个文件或通过管道输出到另一个程序时,就无法接受了,这时候我们需要另一个以与stdin 和stdout 相同的方式分配给程序的输出流——stderr。即使对标准输出进行了重定向,写到stderr 中的输出通常也会显示在屏幕上。
下面是改写的cat 程序,将其出错信息写到标准错误文件上:
#include <stdio.h>
#include <stdlib.h>
// cat: concatenate files, version 2
int main(int argc, char *argv[])
{
FILE *fp;
void filecopy(FILE *, FILE *);
char *prog = argv[0]; // program name for errors
if(argc == 1) // no args; copy standard input
filecopy(stdin, stdout);
else
while(--argc > 0)
if((fp = fopen(*++argv, "r")) == NULL)
{
fprintf(stderr, "%s: can't open %s\n", prog, *argv);
exit(1);
}
else
{
filecopy(fp, stdout);
fclose(fp);
}
if(ferror(stdout))
{
fprintf(stderr, "%s: error writing stdout\n", prog);
exit(2);
}
exit(0);
}
诊断信息中包含argv[0] 中的程序名,因此,当该程序和其它程序一起运行时,可以识别错误的来源。程序使用了标准库函数exit,当该函数被调用时,它将终止调用程序的执行。按照惯例,返回值0 表示一切正常,而非0 返回值通常表示出现了异常情况。exit 为每个已打开的输出文件调用fclose 函数,以将缓冲区中的所有输出写到相应的文件中。
如果流fp 中出现错误,则函数ferror (int ferror(FILE *fp))返回一个非0 值。尽管输出错误很少出现,但还是存在的(比如,磁盘满时)。因此,成熟的产品程序应该检查这种类型的错误。
函数feof(int feof(FILE *fp)) 与ferror 类似。如果指定的文件到达文件结尾,它将返回一个非0 值。在上面的小程序中,我们的目的是为了说明问题,因此并不关心程序的退出状态,但对于任何重要的程序来说,都应该让程序返回有意义且有用的值。
91、行输入和行输出
标准库提供了一个输入函数fgets:char *fgets(char *line, int maxline, FILE *fp),fgets 函数从fp 指向的文件中读取下一个输入行(包括换行符),并将它存放在字符数组line 中,它最多可读取maxline-1 个字符。读取的行将以'\0' 结尾保存到数组中。通常情况下,fgets 返回line,但如果遇到了文件结尾或发生了错误,则返回NULL。
输出函数将一个字符串(不需要包含换行符)写入到一个文件中:int fputs(char *line, FILE *fp) 如果发生错误,该函数将返回EOF,否则返回一个非负值。
库函数gets 和puts 的功能与fgets 和fputs 函数类似,但它们是对stdin 和stdout 进行操作。有一点要注意:gets 函数在读取字符串时将删除结尾的换行符('\n'),而puts 函数在写入字符串时将在结尾添加一个换行符。
下面的代码是标准库中fgets 和fputs 函数的代码:
// fgets: get at most n chars from iop
char *fgets(char *s, int n, FILE *iop)
{
register int c;
register char *cs;
cs = s;
while(--n > 0 && (c = getc(iop)) != EOF)
if((*cs++ = c) == '\n')
break;
*cs = '\0';
return (c == EOF && cs == s) ? NULL : s;
}
// fputs: put string s on file iop
int fputs(char *s, FILE *iop)
{
int c;
while(c = *s++)
putc(c, iop);
return ferror(iop) ? EOF : 0;
}
ANSI 标准规定,ferror 在发生错误时返回非0 值,而fputs 在发生错误时返回EOF,其它情况返回一个非负值。
使用fgets 函数很容易实现getline 函数:
// getline: read a line, return length
int getline(char *line, int max)
{
if(fgets(line, max, stdin) == NULL)
return 0;
else
return strlen(line);
}
92、释放存储空间
free 函数用于释放通过malloc 或calloc 函数申请的存储空间,使用free 需要注意两点:一,使用free 函数释放不是通过调用malloc 或calloc 函数得到的指针所指向的存储空间是错误的。二:使用已经释放的存储空间是错误的。关于第二点,有一个关于释放链表中各个存储项的典型的错误代码段:
for(p = head; p != NULL; p = p->next) // WRONG free(p);
正确的做法是,在释放每个存储项之前将所需信息保存起来:
for(p = head; p != NULL; p = q)
{
q = p->next;
free(p);
}
93、伪随机数发生器
一个遵循标准的可移植的实现伪随机数发生器的函数rand 以及一个初始化种子数的函数srand,如下:
unsigned long int next = 1;
// rand: return pseudo-random integer on 0...32767
int rand(void)
{
next = next * 1103515245 + 12345;
return (unsigned int)(next/65536) % 32768;
}
// srand: set seed for rand()
void srand(unsigned int seed)
{
next = seed;
}
在实际的函数库中,函数rand() 生成介于0 和RAND_MAX 之间的伪随机整数序列。RAND_MAX 是在头文件<stdlib.h> 中定义的符号常量(查看了一下某机器中的stdlib.h文件中相应的行:#define RAND_MAX 2147483647)。下面是一种生成大于等于0 但小于1 的随机浮点数的方法:
#define frand() ((double) rand() / (RAND_MAX+1.0))
94、Unix 系统接口
C 语言标准库中有一些功能的实现是依赖系统调用的。其中最为典型的便是输入/输出,由于这些功能的实现需要与系统底层进行交互,所以标准库中I/O 部分的库函数大多是对底层系统调用进行了一次封装。举两个例子:
在C 语言中,可以直接访问read 和write 这两个系统调用。通过对这两个函数进行封装,便可以构造类似于getchar 和putchar 这样的高级函数。
系统调用open 用于打开文件,creat 用于创建文件。open 与标准库中的fopen 类似,不同的是,前者返回一个int 类型的非负整数,代表文件描述符。而后者返回一个文件指针。如果发生错误,open 将返回-1,而fopen 返回NULL。
(完)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号