函数练习
1.把一个字典扁平化,源字典为{'a':{'b':1,'c':2}, 'd':{'e':3,'f':{'g':4}}} 。
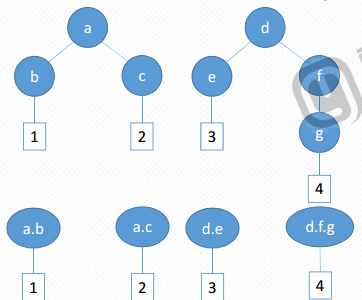
上面字典的扁平化可以转化为下面的字典:{“a.c”:2,"d.e":3,"d.f.g":4,"a.b":1}
source = {'a':{'b':1,'c':2}, 'd':{'e':3,'f':{'g':4}}}
target = {}
#recursion
def flatmap(src,prefix = ""):
for k,v in src.items():
if isinstance(v,(list,tuple,set,dict)):
flatmap(v,prefix=prefix+k+".")#递归调用
else:
target[prefix+k]=v
flatmap(source)
print(target)
结果为:
{'a.b': 1, 'a.c': 2, 'd.e': 3, 'd.f.g': 4}
像一般这样的函数都会生成一个新的字典,上面的代码借用了外部的变量,破坏了函数的封装,因此可以对上面的函数稍微改造下,dest字典可以由内部来创建,当然也可以外部提供。
source = {'a':{'b':1,'c':2}, 'd':{'e':3,'f':{'g':4}}}
#recursion
def flatmap(src,dest=None,prefix = ""):
if dest ==None:
dest = {}
for k,v in src.items():
if isinstance(v,(list,tuple,set,dict)):
flatmap(v,dest,prefix=prefix+k+".")#递归调用
else:
dest[prefix+k]=v
return dest
print(flatmap(source))
结果为:
{'a.b': 1, 'a.c': 2, 'd.e': 3, 'd.f.g': 4}
上面的函数有一个缺点,那就是将内部的字典暴露给了外部,能否函数提供一个参数源字典,返回一个新的扁平化字典?递归的时候要把目标字典的引用传递多层,这个时候应该怎么处理?
source = {'a':{'b':1,'c':2}, 'd':{'e':3,'f':{'g':4}}}
#recursion
def flatmap(src):
def _flatmap(src,dest=None,prefix=""):
for k,v in src.items():
key = prefix+k
if isinstance(v,(list,tuple,set,dict)):
_flatmap(v,dest,key+".")#递归调用
else:
dest[key]=v
dest = {}
_flatmap(src,dest)
return dest
print(flatmap(source))
结果为:
{'a.b': 1, 'a.c': 2, 'd.e': 3, 'd.f.g': 4}
2.实现base64编码,要求自己实现算法,不用库。
将输入每3个字节断开,拿出一个3个字节,每6个bit断开成4段。2**6=64,因此有了base64的编码表。每一段当做一个8bit看它的值,这个值就是base64编码表的索引值,找到对应字符。再取出3个字节,同样处理,直到最后。
举例:
abc对应的ASCII码为:0x61 0x62 0x63
01100001 01100010 01100011#abc
011000 010110 001001 100011
00011000 00010110 00001001 00100011 #每6位补齐为8位
24 22 9 35
末尾的处理?
- 正好3个字节,处理方式同上。
- 剩1个字节或2个字节,用0补满3个字节。
- 补0的字节用=表示。
# 自己实现对一段字符串进行base64编码 alphabet = b"ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwsyz0123456789+/" teststr = "abcd" tsetstr ="Manma" def base64(src): ret = bytearray() length = len(src) #用r记录补0的个数 r = 0 for offset in range(0,length,3): if offset+3<=length: triple = src[offset:offset+3] else: triple = src[offset:] r = 3-len(triple) triple = triple +"\x00"*r#补几个0 #print(triple,r) #将3个字节看成一个整体转成字节bytes,大端模式 #abc=>0x616263 b = int.from_bytes(triple.encode(),"big")#小端模式为"little" print(hex(b)) #01100001 01100010 01100011 #abc #011000 010110 001001 100011 #每6位断开 for i in range(18,-1,-6): if i==18: index = b>>i else: index = b>>i &0x3F #0b0011 1111 ret.append(alphabet[index])#得到base64编码的列表 #策略是不管是不是补0,都补满,只有最后一次可能出现补0的 #在最后替换掉就是了,代码清晰,而且替换至多2次 #在上一个循环中判断r!=0,效率可能会更高些 for i in range(1,r+1):#1到r,补几个0替换几个= ret[-i]=0x3D return ret print(base64(tsetstr))
结果为:
0x4d616e 0x6d6100 bytearray(b'TWFubWE=')
#base64实现
import base64
print(base64.b64encode(teststr.encode()))
结果为:
b'TWFubWE='
练习3:求两个字符串的最长公共子串
思考:
s1 = "abcdefg"
s2 = "defabcd"
方法一:矩阵算法
让s2的每一个元素,去分别和s1的每一个元素比较,相同为1 ,不同为0,有下面的矩阵。

上面都是s1的索引。
看与斜对角平行的线,这个线是穿过1的,那么最长的就是最长子串。
print(s1[3:3+3])
print(s1[0:0+4])最长
矩阵求法还需要一个字符扫描最长子串的过程,扫描的过程就是len(s1)len(s2)次,O(nm).
有办法一遍循环就找出最长的子串嘛?
0001000第一行,索引为3,0。
第二行的时候如果4,1是1,就判断3,0是否为1,为1就把3,0加1。
第二行的时候如果5,2是1,就判断4,1是否为1,是1就加1,再就判断3,0是否为1,为1就把3,0加1 。
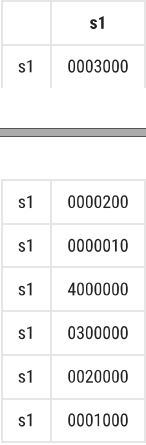
上面的方法是个递归问题,不好。
最后在矩阵中找到最大的元素,从它开始就能写出最长的子串了。
但是这个不好算,因为是逆推的,改为顺推。

顺推的意思,就是如果找到一个就看前一个的数字是几,然后在它的基础上加1。
s1 = "abcdefg" s2 = "defabcd" s2 = "defabcdoabcdeftw" s3 = "1234a" s4 = "5678" s5 = "abcdd" def findit(str1,str2): matrix = [] #从x轴或者y轴取都可以,选择x轴,xmax和xindex xmax = 0 xindex = 0 for i,x in enumerate(str2): matrix.append([]) for j,y in enumerate(str1): if x!=y:#若两个字符不相等 matrix[i].append(0) else: if i==0 or j ==0:#两个字符相等,有字符在边上的 matrix[i].append(1) else:#不在边上 matrix[i].append(matrix[i-1][j-1]+1) if matrix[i][j]>xmax:#判断当前加入的值和记录的最大值比较 xmax = matrix[i][j]#记录最大值,用于下次比较 xindex = j#记录当前值的x轴偏移量,和str1[xindex+1-xmax:xindex+1匹配] xindex+=1#只是为了计算的需求才+1,和str1[xindex-xmax:xindex]匹配 #return str1[xindex+1-xmax:xindex+1] return str1[xindex - xmax:xindex] print(findit(s1,s2)) print(findit(s1,s3)) print(findit(s1,s4)) print(findit(s1,s5)) s1 = " abcdefg " s2 = "304abcdd" print(findit(s1,s5)) 结果为: abcdef a abcd abcd
方法二:
可不可以这样思考?
字符串都是连续的字符,所以才有了下面的思路。
思路一:
第一轮
从s1中依次取1个字符,在s2中查找,看是否能够找到子串。
如果没有一个字符在s2中找到,说明就没有公共子串,直接退出。如果找到了至少一个公共子串,则很有可能还有更长的公共子串,可以进入下一轮。
第二轮
然后从s1中取连续的2个字符,在s2中查找,看看能够找到公共的子串。如果没有找到,说明最大公共子串就是上一轮的随便的哪一个就行了。如果找到至少一个,则说明公共子串可能还可以再长一些。可以进入下一轮。
改进,其实只要找到第一轮的公共子串的索引,最长公共子串也就是从它开始的,所以以后的轮次都从这些索引位置开始,可以减少比较的次数。
思路二:
既然是求最大子串,我先看s1全长作为子串。
在s2中搜索,是否返回正常的index, 正常就找到了最长的子串。
没有找到,把s1按照length-1取多个子串。
在s2中搜索,是否能返回正常的index。
注意:
不要一次把s1的所有子串生成,用不了,也不要从最短开始,因为题目要最长的。
但是也要注意,万一他们的公共子串就只有一个字符,或者很少字符的,思路一就会占优势。
s1 = "abcdefg" s2 = "defaabcdoabcdeftw" s3 = "1234a" def findit(str1,str2): count = 0#看看效率,计数 length = len(str1) for sublen in range(length,0,-1): for start in range(0,length - sublen +1): substr = str1[start:start+sublen] count+=1 if str2.find(substr)>-1:#found print("count={},substrlen={}".format(count,sublen)) return substr print(findit(s1,s2)) print(findit(s1,s3)) 结果为: count=2,substrlen=6 abcdef count=22,substrlen=1 a


 浙公网安备 33010602011771号
浙公网安备 33010602011771号