
排序算法之选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
也就是:n个数从左至右,索引从0开始到n-1,两两依次比较,记录大值索引,此轮所有数比较完毕,将大数和索引0数交换,如果大数就是索引1,不交换。第二轮,从1开始比较,找到最大值,将它和索引1位置交换,如果它就在索引1位置则不交换。依次类推,每次左边都会固定下一个大数。
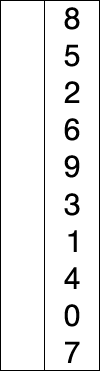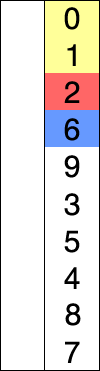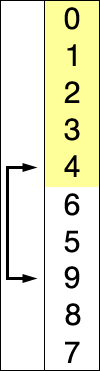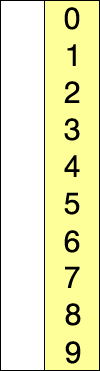
以列表 [8, 5, 2, 6, 9, 3, 1, 4, 0, 7] 为例。第一次从列表 [8, 5, 2, 6, 9, 3, 1, 4, 0, 7] 中找到最小的数 0,放到数组的最前面(与第一个元素进行交换):

交换后:

然后在剩余的序列中 [5, 2, 6, 9, 3, 1, 4, 8, 7] 中找到最小的数 1,与该序列的第一个个元素进行位置交换:

交换后:

再在剩余的序列中 [2, 6, 9, 3, 5, 4, 8, 7] 中找到最小的数 2,与该序列的第一个个元素进行位置交换(实际上不需要交换):

重复上述过程,直到最后一个元素就完成了排序。
示例动图如下:
代码实现如下:
lst = [17, 23, 20, 14, 12, 25, 1, 20, 81, 158, 11, 12] print(lst) for i in range(len(lst)): #print(i) minindex = i for j in range(i+1,len(lst)): if lst[minindex]>lst[j]: minindex = j if i == minindex: pass else: lst[i],lst[minindex] = lst[minindex],lst[i] print(lst) 结果为: [17, 23, 20, 14, 12, 25, 1, 20, 81, 158, 11, 12] [1, 11, 12, 12, 14, 17, 20, 20, 23, 25, 81, 158]
m_list = [[1,9,8,5,6,7,4,3,2], [1,2,3,4,5,6,7,8,9], [9,8,7,6,5,4,3,2,1]] nums = m_list[1] length = len(nums) count_swap = 0 count_iter = 0 for i in range(length): maxindex = i for j in range(i+1,length): count_iter +=1 if nums[maxindex] <nums[j]: maxindex = j if i != maxindex: tmp = nums[i] nums[i] = nums[maxindex] nums[maxindex] = tmp count_swap += 1 print(nums,count_swap,count_iter) 结果为: [9, 8, 7, 6, 5, 4, 3, 2, 1] 4 36
上面的代码不管列表排序好了没有,都需要循环那么多次,这个时候可以进一步优化代码。跑一趟的时候,同时固定左边最大值和右边的最小值。这样就可以减少循环迭代的次数。这个排序也叫着二元选择排序。
m_list = [[1,9,8,5,6,7,4,3,2], [1,2,3,4,5,6,7,8,9], [9,8,7,6,5,4,3,2,1]] nums = m_list[1] length = len(nums) print(nums) count_swap = 0 count_iter = 0 #二元选择排序 for i in range(length//2): maxindex = i minindex = -i - 1 minorigin = minindex for j in range(i+1,length -i):#每次左右都要少比较一个 count_iter+=1 if nums[maxindex]<nums[j]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 #print(maxindex,minindex) if i!= maxindex: nums[i],nums[maxindex] = nums[maxindex],nums[i] count_swap +=1 #如果最小值被交换过,要更新索引 if i == minindex or i ==length + minindex: minindex = maxindex if minorigin != minindex: tmp = nums[minorigin] nums[minorigin] = nums[minindex] nums[minindex] = tmp count_swap +=1 print(nums,count_swap,count_iter) 结果为: [1, 2, 3, 4, 5, 6, 7, 8, 9] [9, 8, 7, 6, 5, 4, 3, 2, 1] 8 20
上面的代码如果元素相同的时候,也就是一轮比较后,极大值和极小值的值相等,说明比较的序列元素全部相等,还可以进一步进行代码优化:
m_list = [[1,9,8,5,6,7,4,3,2], [1,2,3,4,5,6,7,8,9], [9,8,7,6,5,4,3,2,1], [1,1,1,1,1,1,1,1,1]] nums = m_list[3] length = len(nums) print(nums) count_swap = 0 count_iter = 0 #二元选择排序 for i in range(length//2): maxindex = i minindex = -i - 1 minorigin = minindex for j in range(i+1,length -i):#每次左右都要少比较一个 count_iter+=1 if nums[maxindex]<nums[j]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 #print(maxindex,minindex) if nums[maxindex] == nums[minindex]:#元素全相同 break if i!= maxindex: nums[i],nums[maxindex] = nums[maxindex],nums[i] count_swap +=1 #如果最小值被交换过,要更新索引 if i == minindex or i ==length + minindex: minindex = maxindex if minorigin != minindex: tmp = nums[minorigin] nums[minorigin] = nums[minindex] nums[minindex] = tmp count_swap +=1 print(nums,count_swap,count_iter) 结果为: [1, 1, 1, 1, 1, 1, 1, 1, 1] [1, 1, 1, 1, 1, 1, 1, 1, 1] 0 8
如果是[1, 1, 1, 1, 1, 1, 1, 1, 2] 这种情况,找到的最小值索引是-2,最大值索引8,上面的代码会交换2次,最小值两个1交换是无用功,所以,增加一个判断。
m_list = [[1,9,8,5,6,7,4,3,2], [1,2,3,4,5,6,7,8,9], [9,8,7,6,5,4,3,2,1], [1,1,1,1,1,1,1,1,1], [1,1,1,1,1,1,1,1,2]] nums = m_list[4] length = len(nums) print(nums) count_swap = 0 count_iter = 0 #二元选择排序 for i in range(length//2): maxindex = i minindex = -i - 1 minorigin = minindex for j in range(i+1,length -i):#每次左右都要少比较一个 count_iter+=1 if nums[maxindex]<nums[j]: maxindex = j if nums[minindex] > nums[-j-1]: minindex = -j-1 #print(maxindex,minindex) if nums[maxindex]==nums[minindex]:#元素相同 break if i!= maxindex: nums[i],nums[maxindex] = nums[maxindex],nums[i] count_swap +=1 #如果最小值被交换过,要更新索引 if i == minindex or i ==length + minindex: minindex = maxindex #最小值索引不同,但值相同就没有必要交换了 if minorigin != minindex and nums[minorigin] != nums[minindex]: tmp = nums[minorigin] nums[minorigin] = nums[minindex] nums[minindex] = tmp count_swap +=1 print(nums,count_swap,count_iter)
结果为:
[1, 1, 1, 1, 1, 1, 1, 1, 2] [2, 1, 1, 1, 1, 1, 1, 1, 1] 1 14
总结:
选择排序需要数据一轮轮比较,并在每一轮中发现极值。它没有办法知道当前轮是否已经达到排序要求,但是可以知道极值是否在目标索引位置上。
它的遍历次数1,...,n-1之和n(n-1)/2,时间复杂度O(n2),减少了交换次数,提高了效率,性能略好于冒泡法。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号