
08 线程GIL锁 GIL与普通互斥锁 死锁递归锁 事件 信号量
一、多线程实现TCP的并发
TCP服务端实现并发
1.将不同的功能尽量拆分成不同的函数
拆分出来的功能可以被多个地方使用
2.将连接循环和通信循环拆分成不同的函数
3.将通信循环做成多线程
import socket from threading import Thread import time """ 服务端 1.要有固定的IP和PORT 2.24小时不间断提供服务 3.能够支持并发 """ server = socket.socket() server.bind(('127.0.0.1',8080)) server.listen(5) def talk(conn): while True: try: data = conn.recv(1024) if len(data) == 0:break print(data.decode('utf-8')) time.sleep(10) #开启一个客户端的时候10s打印一个结果,多个客户端就会有并发效果,开10个感觉上10s打印10个 conn.send(data.upper()) except ConnectionResetError as e: print(e) break conn.close() while True: conn, addr = server.accept() # 监听 等待客户端的连接 阻塞态 print(addr) t = Thread(target=talk,args=(conn,)) t.start()


import socket client = socket.socket() client.connect(('127.0.0.1',8080)) while True: client.send(b'hello') data = client.recv(1024) print(data.decode('utf-8'))
一、GIL(global interpreter lock)介绍(******)
1.GIL基本认识
【问题一】 只有python有GIL吗?
GIL全局解释器锁目前是所有解释型语言的通病不可调和,必须加锁,编译型语言在编译的时候已经管理好了多线程运行的问题
有人给处理的数据加锁,虽然可以,但是那样就会有很多锁,出现大量的串行,给解释器加锁虽然也是串行,但是至少还可以实现并发
【问题二】 GIL全局解释器锁的存在是python的问题么?
GIL并不是Python的特性,Python完全可以不依赖于GIL,只是Cpython的内存管理不是线程安全,就引入这一个概念,JPython就不存在
内存管理(垃圾回收机制)
引用计数: 值与变量的绑定关系的个数
标记清除: 当内存快要满的时候 会自动停止程序的运行 检测所有的变量与值的绑定关系
给没有绑定关系的值打上标记,最后一次性清除
分代回收: (垃圾回收机制也是需要消耗资源的,而正常一个程序的运行内部会使用到很多变量与值
并且有一部分类似于常量,减少垃圾回收消耗的时间,应该对变量与值的绑定关系做一个分类)
新生代(5S)》》》青春代(10s)》》》老年代(20s)
垃圾回收机制扫描一定次数发现关系还在,会将该对关系移至下一代
随着代数的递增 扫描频率是降低的
2. GIL作用原理:
将并发运行变成串行,牺牲效率来提高数据的安全(所有互斥锁的本质)
控制同一时间内共享数据只能被一个线程所修改(不能并行但是能够实现并发)
3.GIL原因详解
一个进程中必带一个解释器和一个垃圾回收线程
一个进程下的多个线程都需要运行,就必须去调解释器,垃圾回收线程也要用解释器,
如果不加限制,如果回收机制和其他线程同时使用解释器,会同时执行,回收机制就可能误删掉那些刚创建还没来得及绑定的变量资源
因此必须给解释器加锁,只能允许一个线程使用,我干活的时候你滚一边去,不要干扰我,这样才不会冲突
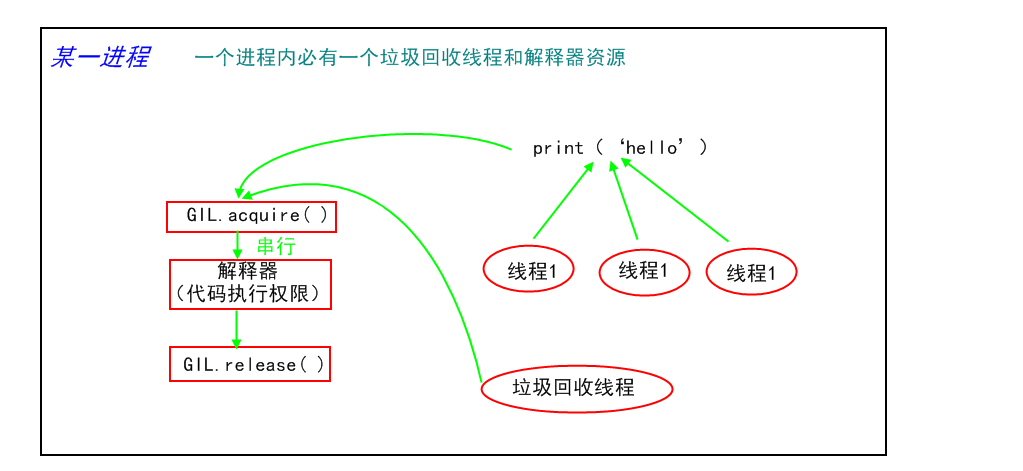
4、多核单核下多线程作用
【问题】 进程可以利用多核,但是开销大,python的多线程开销小,但却无法利用多核优势,难道说说python多线程没用了?
同一个进程下的多个线程虽不能实现并行,但是能够实现并发
多个进程下的线程能够实现并行,发挥多核优势
对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用
当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高)
这是因为一个程序基本上不会是纯计算或者纯I/O
所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地
#分析: 我们有四个任务需要处理,处理方式肯定是要玩出并发的效果,解决方案可以是: 方案一:开启四个进程 方案二:一个进程下,开启四个线程 #单核情况下:
如果四个任务是计算密集型,没有多核来并行计算,方案一徒增了创建进程的开销,开线程牛逼 如果四个任务是I/O密集型,创建进程的开销大,且进程的切换速度远不如线程,开线程牛逼 #多核情况下:
如果四个任务是计算密集型,多核意味着并行计算,在python中一个进程中同一时刻只有一个线程执行用不上多核,开进程牛逼 如果四个任务是I/O密集型,再多的核去开再多进程还是要一个个等IO的时间,也解决不了I/O问题,多线程节约了资源还交互进行提高效率,开线程牛逼
目前计算机都是多核,所以:
计算密集型:多线程还不如串行(没有大量切换),多核多进程牛逼
IO密集型: 多线程明显提高效率,多核没屌用
多线程和多进程都有自己的优点,要根据项目需求合理选择
目前大多数软件都是IO密集型:socket 爬虫 web
也有计算密集型的:金融分析
# IO密集型 from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) #睡觉也是典型的IO操作 if __name__ == '__main__': l=[] print(os.cpu_count()) #获取本机cpu数量 start=time.time() for i in range(300): # p=Process(target=work) #用进程跑 耗时12.69s p=Thread(target=work) #用线程跑 耗时2.03s l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))
# 计算密集型 from multiprocessing import Process from threading import Thread import os,time def work(): res=0 for i in range(100000000): res*=i if __name__ == '__main__': l=[] print(os.cpu_count()) # 本机为4核 start=time.time() for i in range(8): p=Process(target=work) #耗时24.21s # p=Thread(target=work) #耗时43.61s l.append(p) p.start() for p in l: p.join() stop=time.time() print('run time is %s' %(stop-start))
二、普通互斥锁
当多个 进程 / 线程 操作同一份数据的时候 会造成数据的错乱
这个时候必须加锁处理
将并发变成串行
虽然降低了效率但是提高了数据的安全
注意:
1.锁不要轻易使用 容易造成死锁现象
2.只在处理数据的部分加锁 不要在全局加锁
对于进程,锁必须在主进程中产生,交给子进程去使用
#模拟抢票 不加锁情况下如果有一张票是个人都能抢到,加锁后只有一个人可以抢到 from multiprocessing import Process,Lock #第一步 导入模块 import time import json # 查票 def search(i): with open('data','r',encoding='utf-8') as f: data = f.read() t_d = json.loads(data) print('用户%s查询余票为:%s'%(i,t_d.get('ticket'))) # 买票 def buy(i): with open('data','r',encoding='utf-8') as f: data = f.read() t_d = json.loads(data) time.sleep(1) if t_d.get('ticket') > 0: # 票数减一 t_d['ticket'] -= 1 # 更新票数 with open('data','w',encoding='utf-8') as f: json.dump(t_d,f) print('用户%s抢票成功'%i) else: print('没票了') def run(i,mutex): #第五步 接收锁 search(i) mutex.acquire() # 第六步 抢锁 只要有人抢到了锁 其他人必须等待该人释放锁 buy(i) mutex.release() # 第七步 释放锁 if __name__ == '__main__': mutex = Lock() # 第二步 主程序中生成了一把锁 for i in range(10): p = Process(target=run,args=(i,mutex)) #第三步传给子进程 p.start()
三、GIL与普通互斥锁
GIL并不能保证数据的安全,它是对Cpython解释器加锁,针对的是线程,保证的是同一个进程下多个线程之间的安全
普通互斥锁可以保证数据的安全
#GIL内置存在,只允许一个线程通过,但数据依然不安全
from threading import Thread import time n = 100 def task(): global n tmp = n time.sleep(0.1) # 在睡觉的情况下,输出99,1拿到全局锁遇到IO去睡觉时,GIL必须交出来,2抢到,1还没运行完,0.1s足够大家能抢一遍GIL,所以都拿到100去睡觉了 # 不睡觉的情况下,输出0,1抢到GIL没有IO会一直拿着直到输出后释放,释放后2才能抢到GIL才能继续搞 n = tmp -1 t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(n)
#加自定义锁保证数据安全
from threading import Thread,Lock import time n = 100 mutex = Lock() def task(): global n tmp = n #99 放在这里,tmp受到GIL控制,GIL还没有出计算结果就释放,0.1s的睡眠时间GIL够大家搞一遍了,也就是都得到了tmp=100 mutex.acquire() # tmp = n #0 放在这里,tmp受到自定义锁控制,自定义锁必须在运行结束才能释放,大家拿到的n都是上次结果-1 time.sleep(0.1) n = tmp -1 mutex.release() t_list = [] for i in range(100): t = Thread(target=task) t.start() t_list.append(t) for t in t_list: t.join() print(n)
四、死锁、递归锁现象
进程也有死锁与递归锁,用法相似
1.只要类加括号实例化对象
无论传入的参数是否一样生成的对象肯定不一样,不信你打印id
单例模式除外
mutexA = Lock() mutexB = Lock()
mutexA 和 mutexB 可不是一样东西
2.链式赋值出来的对象那可是一毛一样 mutexA = mutexB = RLock() # A B现在是同一把锁
4.1 lock 死锁现象
lock锁 一次acquire必须对应一次release,不能连续acquire
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,(你拿了我想要的锁,我拿了你想要的锁)
若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程
如下就是死锁:
from threading import Thread,Lock,current_thread,RLock import time """ 自定义锁一次acquire必须对应一次release,不能连续acquire 自己千万不要轻易的处理锁的问题 """ mutexA = Lock() mutexB = Lock() class MyThread(Thread): def run(self): # 创建线程自动触发run方法 run方法内调用func1 func2相当于也是自动触发 self.func1() self.func2() def func1(self): mutexA.acquire() print('%s抢到了A锁'%self.name) # self.name等价于current_thread().name mutexB.acquire() print('%s抢到了B锁'%self.name) mutexB.release() print('%s释放了B锁'%self.name) mutexA.release() print('%s释放了A锁'%self.name) def func2(self): mutexB.acquire() print('%s抢到了B锁'%self.name) time.sleep(1) mutexA.acquire() print('%s抢到了A锁' % self.name) mutexA.release() print('%s释放了A锁' % self.name) mutexB.release() print('%s释放了B锁' % self.name) for i in range(3): t = MyThread() t.start() ''' Thread-1抢到了A锁 Thread-1抢到了B锁 Thread-1释放了B锁 Thread-1释放了A锁 Thread-1抢到了B锁 Thread-2抢到了A锁 #到这里之后就出现死锁了,你想要的我的锁我想要你的锁 '''
4.2Rlock递归锁 解决死锁
解决死锁方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
Rlock可以被第一个抢到锁的人连续的acquire和release
每acquire一次锁身上的计数加1
每release一次锁身上的计数减1
只要锁的计数不为0 其他人都不能抢
from threading import Thread,Lock,current_thread,RLock import time """ Rlock可以被第一个抢到锁的人连续的acquire和release 每acquire一次锁身上的计数加1 每release一次锁身上的计数减1 只要锁的计数不为0 其他人都不能抢 """ mutexA = mutexB = RLock() # A B现在是同一把锁,抢锁之后会有一个计数 抢一次计数加一 针对的是第一个抢到我的人 print(id(mutexB)) #35379080 print(id(mutexA)) #35379080 class MyThread(Thread): def run(self): # 创建线程自动触发run方法 run方法内调用func1 func2相当于也是自动触发 self.func1() self.func2() def func1(self): mutexA.acquire() print('%s抢到了A锁'%self.name) # self.name等价于current_thread().name mutexB.acquire() print('%s抢到了B锁'%self.name) mutexB.release() print('%s释放了B锁'%self.name) mutexA.release() print('%s释放了A锁'%self.name) def func2(self): mutexB.acquire() print('%s抢到了B锁'%self.name) time.sleep(1) mutexA.acquire() print('%s抢到了A锁' % self.name) mutexA.release() print('%s释放了A锁' % self.name) mutexB.release() print('%s释放了B锁' % self.name) for i in range(3): t = MyThread() t.start()
五、Semaphore 信号量
进程也有
信号量可能在不同的领域中 对应不同的知识点
互斥锁:一个厕所(一个坑位)
信号量:公共厕所(多个坑位)
from threading import Semaphore,Thread import time import random sm = Semaphore(3) # 造了一个含有五个的坑位的公共厕所 def task(name): sm.acquire() print('%s占了一个坑位'%name) time.sleep(random.randint(1,30)) print('%s放出一个坑位' % name) sm.release() for i in range(5): t = Thread(target=task,args=(i,)) t.start() ''' 0占了一个坑位 1占了一个坑位 2占了一个坑位 2放出一个坑位 3占了一个坑位 0放出一个坑位 4占了一个坑位 1放出一个坑位 3放出一个坑位 4放出一个坑位 '''
六、event事件 子等子
进程也有
from threading import Event,Thread import time # 先生成一个event对象 e = Event() def light(): print('红灯正亮着') time.sleep(3) e.set() # 发信号 print('绿灯亮了') def car(name): print('%s正在等红灯'%name) e.wait() # 等待信号 print('%s加油门飙车了'%name) t = Thread(target=light) t.start() for i in range(3): t = Thread(target=car,args=('伞兵%s'%i,)) t.start() ''' 红灯正亮着 伞兵0正在等红灯 伞兵1正在等红灯 伞兵2正在等红灯 绿灯亮了 伞兵1加油门飙车了 伞兵2加油门飙车了 伞兵0加油门飙车了 '''

