
04 正则表达式 和 re模块
一、正则表达式
#正则引入
用户输入手机号后怎么样辨别是否合法呢?看我python的!常规写法一句一句逐个条件来?low不low


while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码')
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码')
看完两种方法是不是若有所思?难道还要坚持骑自行车么?
1.正则基本概念
#用来筛选字符串中的特定内容,带有reg的一般都是正则相关
#re模块与正则表达式之间的关系: 正则表达式不是python独有的
它是一门独立的技术 所有的编程语言都可以使用正则
但是如果你想在python中使用,你就必须依赖于re模块
#正则的用途: 1.爬虫 (爬虫必备 书籍推荐:正则指引)
2.数据分析
#在线测试工具:在线测试工具 http://tool.chinaz.com/regex/
2.字符组: [字符组]
#只要符合【】中字符组的任何一个元素就会被筛选
#【1-9】或【1-8a-zA-Z】等形式,字符组紧挨着字符组,且必须是 小-大
#字符组中的字符可以逐个列出,也可以给出范围,如[abc]或[a-c]
#[^abc]表示取反,即非abc


4.量词
两次必须跟在正则符号后面,取值不固定的默认贪婪匹配往多了取
量词只能够限制它紧挨着的那一个正则符号 如:bb23456 [a-z]\d匹配到b2 [a-z]\d+ 匹配到b23456,字母并没有增多

5.实例练习
^ . $

? + * {} 贪婪匹配
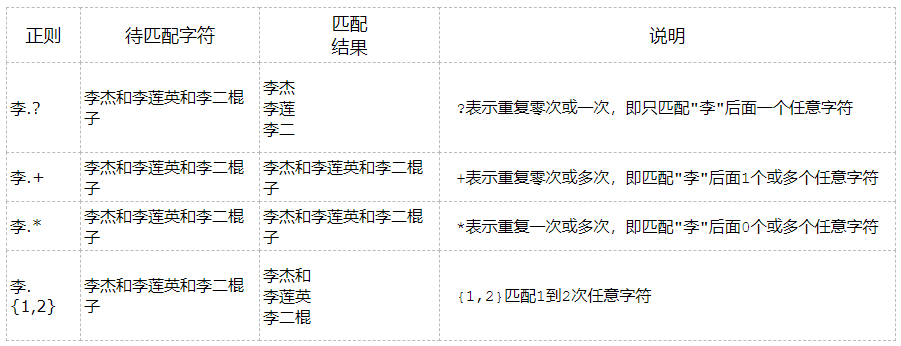
? + * {n,m} 默认贪婪匹配,后面加?号使其变成惰性匹配
字符集 [ ] [ ^ ]
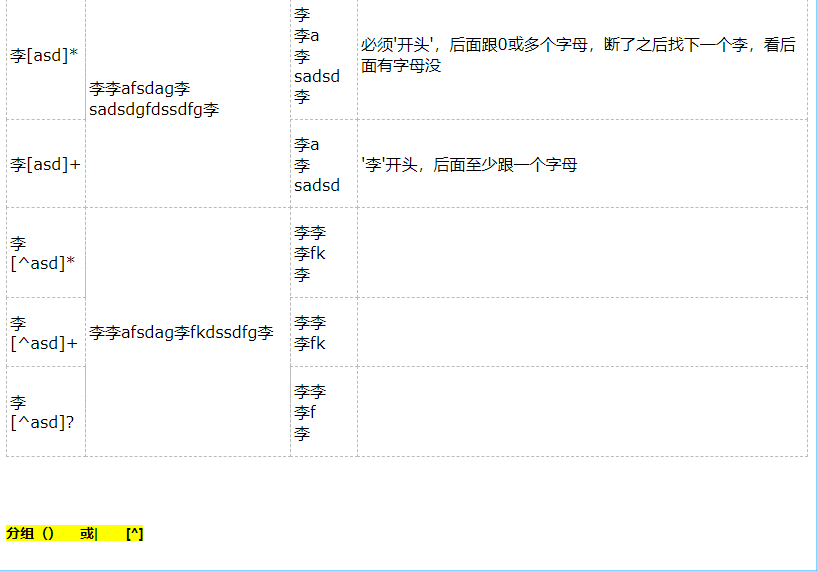
分组: 当多个正则符号需要重复多次的时候或者当做一个整体进行其他操作,那么可以分组的形式
分组在正则的语法中就是()括起来
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:

行转义,变成'\\'。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成'\\n',那么正则里就要写成"\\\\n",这样就太麻烦了。这个时候我们就用到了r'\n'这个概念,此时的正则是r'\\n'就可以了。

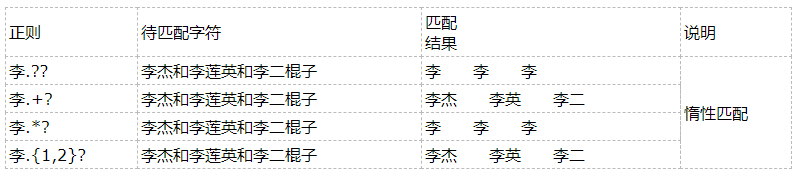
贪婪匹配与非贪婪匹配******
正则默认贪婪匹配往多了取,可以再两次后面加上?来取消贪婪匹配

.*?用法
. 是任意字符
* 是取 0 至 无限长度
? 是非贪婪模式。
何在一起就是 取尽量少的任意字符,一般不会这么单独写,他大多用在:
.*?x
就是取前面任意长度的字符,直到一个x出现
常用的非贪婪匹配
*? 重复任意次,但尽可能少重复 取0个
+? 重复1次或更多次,但尽可能少重复 每次取1个取好多次
?? 重复0次或1次,但尽可能少重复 取0个
{n,m}? 重复n到m次,但尽可能少重复 每次取n个取好多次
{n,}? 重复n次以上,但尽可能少重复 每次取n个取好多次
二、re模块
python要想使用正则 必须借助于re模块或者是一些本身就支持正则表达式书写的方法
1.常用方法findall search match
#findall
findall('正则','待匹配的字符串')
依据正则查找字符串中所有符合该正则的匹配内容,然后组织成一个列表的形式返回
#search
search('正则','待匹配的字符串')
依据正则查找字符串中第一个符合该正则的匹配内容,然后立即结束本次查找 返回一个结果对象
当匹配到的值得时候 查看对象里面的值 用 对象.group()
当匹配不到值得时候 返回的是一个None 对象.group()就直接报错 因为None没有内置的group()方法
#match
match('正则','待匹配的字符串')
依据正则查找字符串开头是否符合该正则的匹配内容,如果有然后立即结束本次查找 返回一个结果对象
当匹配到的值得时候 查看对象里面的值 用 对象.group()
当匹配不到值得时候 返回的是一个None 对象.group()就直接报错 因为None没有内置的group()方法
ps:
通常用search和match,为防止报错,用if判断
res = search/match('正则','待匹配的字符串')
if res:
print(res.group())
import re
findall ('正则表达式','带匹配的字符串')
注意:
1.返回所有满足匹配条件的结果,放在列表里(不用再使用group取值)
2.找不到也不报错,返回空列表
res = re.findall('z','eva egon jason')
print(res) #[] 没有就返回空列表,不报错
search('正则表达式','带匹配的字符串')
注意:
1.search只会依据正则查一次 只要查到了结果 就不会再往后查找
2.当查找的结果不存在的情况下 调用group直接报错
res = re.search('a','eva egon jason')
print(res) # <_sre.SRE_Match object; span=(2, 3), match='a'> search返回一个对象
print(res.group()) # a 只有一个a 必须调用group才能看到匹配到的结果
if res:
print(res.group()) #if判断防止出错
#match('正则表达式','带匹配的字符串')
注意:
1.match只会匹配字符串的开头
2.当字符串的开头不符合匹配规则的情况下 返回的也是None 调用group也会报错
# res = re.match('a','eva egon jason')
# print(res) #对象
# print(res.group()) #报错
if res:
print(res.group()) #找不到不报错什么也不返回
2.其他用法 (了解)
import re
# 1.分割 split
ret = re.split('[ab]', 'abcdaubdd') # 先按'a'分割'a'前为空得到''和'bcdbubdd',在对''和'bcdbubdd'分别按'b'分割得到''和cdbubdd
# 再往后走遇到a,再切,但是a前有cd,所以得到cd和ubdd,再走遇到b切一下,得到u和dd
print(ret) # ['', '', 'cd', 'u', 'dd'] 返回的是列表
# 2.替换sub 和 subn
# # sub('正则表达式','新的内容','待替换的字符串',n) 直接返回结果
# 先按照正则表达式查找所有符合该表达式的内容 统一替换成'新的内容' 还可以通过n来控制替换的个数
ret = re.sub('\d', 'H', 'eva3egon4yuan4',1) # 将数字替换成'H',参数1表示只替换1个
print(ret) # evaHegon4yuan4
# # subn('正则表达式','新的内容','待替换的字符串',n) 返回元祖
# 和sub功能用法一样,只是返回的是一个元组(替换的结果,替换了多少次)
ret = re.subn('\d', 'H', 'eva3egon4yuan4')
ret1 = re.subn('\d', 'H', 'eva3egon4yuan4',1)
print(ret) #('evaHegonHyuanH', 3)
print(ret1) #('evaHegon4yuan4', 1) 指定1次就替换一次
# 3.生成正则对象,再调用方法传入参数进行匹配
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123ee456ee') #正则表达式对象调用search,参数为待匹配的字符串
res1 = obj.findall('347982734729349827384')
print(ret.group()) #结果 : 123
print(res1) #结果 : ['347', '982', '734', '729', '349', '827', '384']
# 4.生成一个匹配结果迭代器对象
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
# print(ret) # <callable_iterator object at 0x10195f940> 可调用对象
# print(next(ret)) #查看第一个 <_sre.SRE_Match object; span=(2, 3), match='3'> next(ret)等价于ret.__next__()
# print(next(ret).group()) #查看第二个4 等价于ret.__next__()
# print(next(ret).group()) #查看第三个7 next方法取值每次取出一个,超出范围直接报错
print([i.group() for i in ret]) #查看全部或剩余的匹配结果,且不会报错
3.分组对各种方法的影响
#search和match (用法基本一样)
res = re.search('^[1-9]\d{14}(\d{2}[0-9x])?$','110105199812067023')
print(res.group()) #110105199812067023 不写默认0即全部输出
print(res.group(1)) #023 第一个分组
res = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','110105199812067023')
print(res.group(1)) #10105199812067 第一个分组
print(res.group(2)) #023 第二个分组
#分组起名字 格式:组内( ?P<名字>+正则)
res = re.search('^[1-9](?P<password>\d{14})(?P<username>\d{2}[0-9x])?$','110105199812067023')
print(res.group('password')) #10105199812067
print(res.group(1)) #10105199812067
print(res.group(2) #023
print(res.group('username')) #023
#findall分组优先机制
# findall会优先把匹配结果组里内容返回,如果想要匹配结果,分组内(?:+正则)取消分组优先权限即可
ret1 = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') # 忽略分组优先的机制
print(ret1,ret2) # ['oldboy'] ['www.oldboy.com']
#split分组保留机制
#常规不保留切分标志,分组后保留标志
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret1=re.split("(\d+)","eva3egon4yuan")
print(ret1) #结果 : ['eva', '3', 'egon', '4', 'yuan']
三、正则应用之小爬虫
小爬虫:
爬虫其实就是爬取网页的html代码(就是一堆字符串)
1.研究网站是否有反爬措施
2.研究该网站页面url的规律
3.想要什么内容 正则如何写
从这一堆字符串中筛选出你想要的内容,刚好可以借助于正则
import re import json from urllib.request import urlopen """ https://movie.douban.com/top250?start=0&filter= https://movie.douban.com/top250?start=25&filter= https://movie.douban.com/top250?start=50&filter= https://movie.douban.com/top250?start=75&filter= <li> <div class="item"> <div class="pic"> <em class="">1</em> <a href="https://movie.douban.com/subject/1292052/"> <img width="100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class=""> </a> </div> <div class="info"> <div class="hd"> <a href="https://movie.douban.com/subject/1292052/" class=""> <span class="title">肖申克的救赎</span> <span class="title"> / The Shawshank Redemption</span> <span class="other"> / 月黑高飞(港) / 刺激1995(台)</span> </a> <span class="playable">[可播放]</span> </div> <div class="bd"> <p class=""> 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br> 1994 / 美国 / 犯罪 剧情 </p> <div class="star"> <span class="rating5-t"></span> <span class="rating_num" property="v:average">9.6</span> <span property="v:best" content="10.0"></span> <span>1489907人评价</span> </div> <p class="quote"> <span class="inq">希望让人自由。</span> </p> </div> </div> </div> </li> """ def getPage(url): response = urlopen(url) return response.read().decode('utf-8') def parsePage(s): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>', re.S) ret = com.finditer(s) for i in ret: yield { "id": i.group("id"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num response_html = getPage(url) ret = parsePage(response_html) print(ret) f = open("move_info7", "a", encoding="utf8") for obj in ret: print(obj) data = str(obj) f.write(data + "\n") count = 0 for i in range(10): main(count) count += 25

