01 模块导入 、包介绍
一、模块基本认识
1.1 什么是模块: 模块:就是一系列功能的结合体 1.2 模块的三种来源: 1.内置的(python解释器自带) 2.第三方的(别人写的) 3.自定义的(你自己写的) 1.3 模块的四种表现形式: 1.py文件: 使用python编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为一个模块) 2.共享库: 使用C编写并连接到python解释器的内置模块 3.一系列模块文件的结合体(包): 把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件夹称之为包) 4.已被编译为共享库或DLL的C或C++扩展(了解) 1.5 为什么要用模块(提高开发效率 减少代码冗余 使项目结构更加清晰) 1.内置的,第三方:典型的拿来主义,极大的提高开发效率 2.自定义的:当程序比较庞大的时候,你的项目不可能只在一个py中,那么当多个文件中都需要使用相同的方法的时候
可以将该公共的方法写到一个py文件中其他的文件以模块的形式导过去直接调用即可 1.6 如何区分哪个是执行文件,哪个是被导入文件(******) print(__name__): 1.当文件被当做执行文件执行的时候__name__打印的结果是__main__ 2.当文件被当做模块导入的时候__name__打印的结果是模块名(没有后缀) 3. if __name__ == '__main__': #快捷方法:写出main直接按tab 后面的加引号
二、模块导入方式
2.1 import os #导入模块一定不要加后缀名
#导入过程 import md #import md 多次导入不会再执行模块文件,会沿用第一次导入的成果(******) 再次调用时python会查找名称空间,一旦发现就直接使用不再重复调用 1.右键运行run.py文件首先会创建一个run.py的名称空间 2.首次导入模块(md.py)(******) 1.执行md.py文件,创建md的名称空间 2.运行md.py文件中的代码将产生的名字与值存放到md.py名称空间中 3.在执行文件中产生一个指向模块名称空间的名字(md) #访问模块中变量 md.money # 访问md模块中的money 1.指名道姓的访问模块中的名字 永远不会与执行文件中的名字冲突 2.你如果想访问模块中名字 必须用模块名.名字的方式 #访问模块中函数 md.change() #会调用md中的change函数 1.只要你能拿到函数名 无论在哪都可以通过函数加括号来调用这个函数(会回到函数定义阶段 依次执行代码) 2.函数在定义阶段 名字查找就已经固定死了 不会因为调用位置的变化而改变 #分次导入原则 导入模块通常情况情况下应该 分多次导入 结构清晰 import os import time import md ps:通常导入模块的句式会写在文件的开头(函数中也可能会有,这样不调用函数不调用模块省内存) #给模块起外号 import ttttttttttttttttttttt as f f.name #访问ttttttttttttttttt中的name 当模块名字比较复杂的情况下 可以给该模块名取别名
2.2 from ... import ...
#两种方式
1.from md1 import money,read1 #从md1模块中拿出变量名或者函数名,可以导出封装的私有属性
2.from dir1.dir import m1 # 从dir1文件中的dir文件里取出m1模块
#导入过程 1.会先创建run1.py的名称空间 2.首次导入md1.py模块 1.运行md1.py,创建md1的名称空间 2.将产生的名字存放到md1.py名称空间中 3.执行文件直接拿到指向模块md1.py名称空间中某个值的名字 # 这一步与import导入不同 #缺点:(目前缺点,习惯就好) 1.访问模块中的名字不需要加模块名前缀 2.在访问模块中的名字可能会与当前执行文件中的名字冲突(执行文件中一定不要用和模块中变量或者函数一样的名字) # 一次取出多个变量或函数 1. from md1 import money,read1,read2,change 2.from md1 import * # 一次性将md1模块中的名字全部加载过来 不推荐使用 名字太多时贼占内存 *的实质:模块文件末尾有个__all__,不写默认全部拿出,写了只拿出你写的那部分,如拿出三个在模块中写: __all__ = ['money','read1','read2']或者拿一个__all__ = ['money']
__all__后面支持函数或者变量等,支持公有属性和私有属性,即封装的也可以
2.3 循环导入(一般不会用 了解即可)
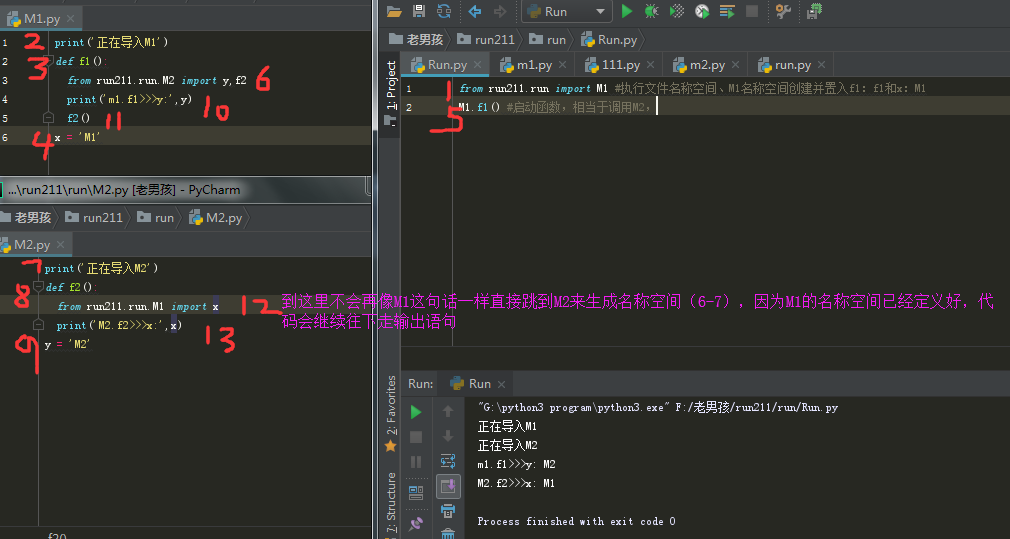
1.如果出现循环导入问题 那么一定是你的程序设计的不合理 循环导入问题应该在程序设计阶段就应该避免 2.解决循环导入: 1.方式1 将循环导入的句式写在文件最下方() #这样一来各个文件中变量都定义完毕都能找到,如果放在中间,变量在循环句式下方定义,找变量的时候就找不到会报错 2.方式2 函数内导入模块
三、模块的查找顺序
#模块的查找顺序 1.先从内存中找 2.内置中找 3.sys.path中找(环境变量):是一个大列表,里面放了一对文件路径,第一个路径永远是执行文件所在的文件夹,可以往该列表中添加路经
#往环境变量中添加路经 当执行文件和md模块(dir1文件下dir文件中)不在一个目录下时: import md 直接调用会出错 第一种方法: import sys sys.path.append(r'D:\Python项目\day14\dir1') #往大列表中添加md所在的文件夹路经 from dir import md #此时就可以找到dir文件再找到md模块 第二种方法: from dir1.dir import md #直接指定路径 #说明先找内存 import time import md time.sleep(20) #先调用md模块文件,然后将其加载读到内存创建md的名称空间,这时候让系统睡20s, # 期间把md文件删除,但是睡醒后还能继续往下运行至结束,执行完毕内存会立马释放名称空间,再次调用就会报错, # 说明先找的是内存 md.f1() #验证再找内置 import time print(name) #新写一个time模块,保证内存中没有,然后运行发现什么也没有输出,说明找的是内置不是路经下的 print(time.name)#我们调用内置的time模块方法能输出时间戳说明找到的就是内置
四、模块的绝对和相对导入
#引子 执行文件和模块m1、m2不在一个文件夹下,m1和m2在一起,m1调用m2 import m2 # 报错 找路经的时候是站在执行文件的立场上,即使模块m1和m2在一个文件中,m1调m2也不能直接找到 from dir1.dir import m2 #绝对路径找,正确 from . import m2 # 相对路径找,正确 #绝对导入(常用,结构清晰) 必须依据执行文件所在的文件夹路径为准,无论在执行文件中还是模块中都适用 #相对导入(执行文件中不能用) .代表的当前路径 ..代表的上一级路径 ...代表的是上上一级路径 注意相对导入不能在执行文件中使用,相对导入只能在被导入的模块中使用,使用相对导入 ,就不需要考虑执行文件到底是谁,只需要知道模块与模块之间路径关系
五、包
5.1 什么是包?
1.它是一系列模块文件的结合体,表示形式就是一个文件夹,本质还是一个模块
2.包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来
5.2.python2和python3的不同(补充知识)
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件
5.3首次导入包名称空间创建:
先产生一个执行文件的名称空间
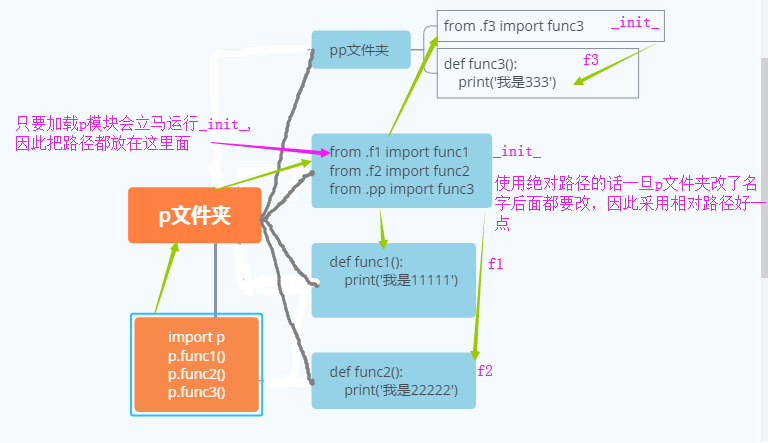
1.创建包下面的__init__.py文件的名称空间(运行包首先会立马运行_init_文件,因此把其他小包路径都放在这里)
2.执行包下面的__init__.py文件中的代码 将产生的名字放入包下面的__init__.py文件名称空间中
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
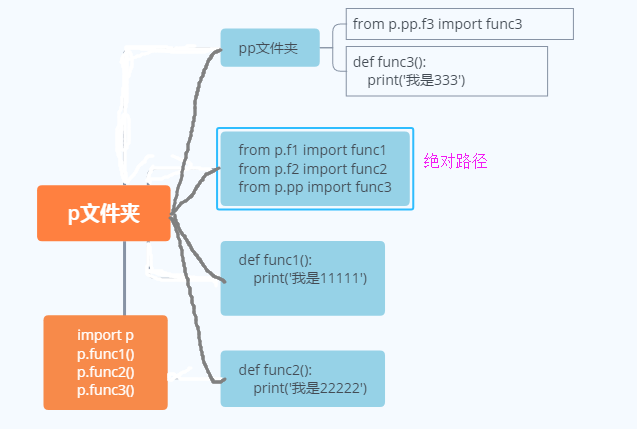
ps:在导入语句中 .号的左边肯定是一个包(文件夹)
5.4 作为包的设计者:
1.当模块的功能特别多的情况下 应该分文件管理
2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是被导入的模块)
ps:创建包的目的不是为了运行,而是被导入使用,不用担心相对导入后就不能执行了
3.如果使用绝对路径来管理的自己的模块 那么它只需要永远以包的路径为基准依次导入模块
站在包的使用者:
如果包和执行文件不是同级文件夹,例如本来执行文件和包p文件夹同级,用户把包放在了与执行文件同级的的outter文件夹下
就必须得将包所在的那个文件夹(outter文件夹)路径添加到system path中,无论使用相对导入还是绝对导入都避免不了这个问题(******)
绝对导入和相对导入(执行文件和包顶级文件P同级情况下)