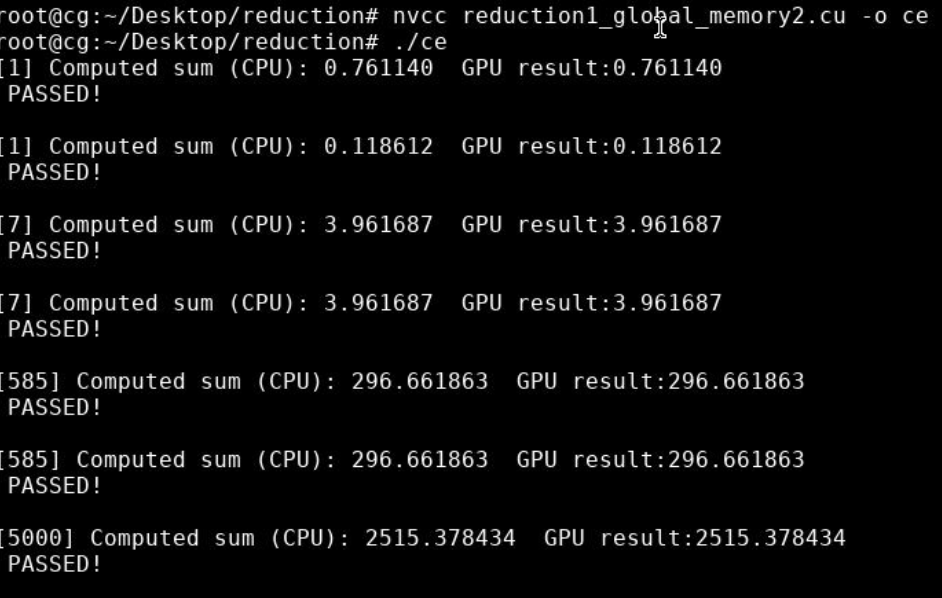
/*
* Todo:
* reduction kernel in which the threads are mapped to data with stride 2
*/__global__ voidkernel_reduction_non_consecutive(DTYPE *input, DTYPE *output, int n){
int id = blockIdx.x * BLOCK_SIZE;
int tid = threadIdx.x;
for (int s = 1; s <= (n / 2); s <<= 1) {
if (tid % s == 0) {
input[id + tid * 2] += input[id + tid * 2 + s];
__syncthreads();
}
}
if (tid == 0) output[blockIdx.x] = input[id];
}
/*
* Todo:
* reduction kernel in which the threads are consecutively mapped to data
*/__global__ voidkernel_reduction_consecutive(DTYPE *input, DTYPE *output, int n){
int id = blockIdx.x * BLOCK_SIZE;
int tid = threadIdx.x;
for (int s = n / 2; s >= 1; s >>= 1) {
if(tid < s){
input[id + tid] += input[id + tid + s];
__syncthreads();
}
}
if (tid == 0) output[blockIdx.x] = input[id];
}
/*
* Todo:
* Wrapper function that utilizes cpu computation to sum the reduced results from blocks
*/DTYPE gpu_reduction_cpu(DTYPE *input, int n,
void (*kernel)(DTYPE *input, DTYPE *output, int n)){
DTYPE *Input, *Output;
CHECK(cudaMalloc((void**)&Input, n * sizeof(DTYPE)));
CHECK(cudaMemcpy(Input, input, n * sizeof(DTYPE), cudaMemcpyHostToDevice));
dim3 block(BLOCK_SIZE / 2);
int BLOCK_NUM = n / BLOCK_SIZE;
CHECK(cudaMalloc((void**)&Output, BLOCK_NUM * sizeof(DTYPE)));
DTYPE* result = (DTYPE*)malloc(BLOCK_NUM * sizeof(DTYPE));
dim3 grid(BLOCK_NUM);
kernel <<<grid, block>>>(Input, Output, BLOCK_SIZE);
CHECK(cudaMemcpy(result, Output, BLOCK_NUM * sizeof(DTYPE), cudaMemcpyDeviceToHost));
DTYPE sum = 0;
for (int i = 0; i < BLOCK_NUM; i++) sum += result[i];
for (int i = BLOCK_SIZE * BLOCK_NUM; i < n; i++) sum += input[i];
return sum;
}
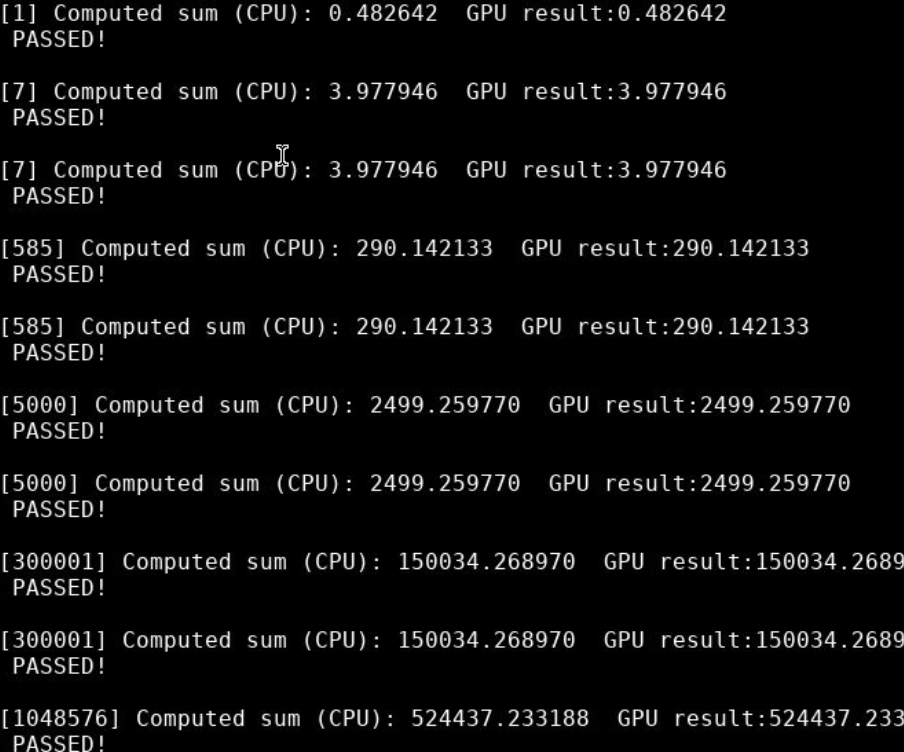
1.2 GPU上统计答案,实验代码
DTYPE gpu_reduction_gpu(DTYPE *input, int n,
void (*kernel)(DTYPE *input, DTYPE *output, int n)){
DTYPE *Input_1, *Input_2, *Output_1, *Output_2;
CHECK(cudaMalloc((void**)&Input_1, n * sizeof(DTYPE)));
CHECK(cudaMemcpy(Input_1, input, n * sizeof(DTYPE), cudaMemcpyHostToDevice));
dim3 block(BLOCK_SIZE / 2);
int BLOCK_NUM_1 = n / BLOCK_SIZE;
dim3 grid_1(BLOCK_NUM_1);
CHECK(cudaMalloc((void**)&Output_1, (BLOCK_NUM_1 + 1) * sizeof(DTYPE)));
DTYPE* result_1 = (DTYPE*)malloc((BLOCK_NUM_1 + 1) * sizeof(DTYPE));
kernel << <grid_1, block>> >(Input_1, Output_1, BLOCK_SIZE);
CHECK(cudaMemcpy(result_1, Output_1, (BLOCK_NUM_1 + 1) * sizeof(DTYPE), cudaMemcpyDeviceToHost));
if (n % BLOCK_SIZE != 0) {
for (int i = BLOCK_SIZE * BLOCK_NUM_1; i < n; i++) result_1[BLOCK_NUM_1] += input[i];
BLOCK_NUM_1++;
}
DTYPE sum = 0;
int BLOCK_NUM_2 = BLOCK_NUM_1 / BLOCK_SIZE;
dim3 grid_2(BLOCK_NUM_2);
CHECK(cudaMalloc((void**)&Input_2, BLOCK_NUM_1 * sizeof(DTYPE)));
CHECK(cudaMemcpy(Input_2, result_1, BLOCK_NUM_1 * sizeof(DTYPE), cudaMemcpyHostToDevice));
CHECK(cudaMalloc((void**)&Output_2, BLOCK_NUM_2 * sizeof(DTYPE)));
DTYPE* result_2 = (DTYPE*)malloc((BLOCK_NUM_2 + 1) * sizeof(DTYPE));
kernel << <grid_2, block>> >(Input_2, Output_2, BLOCK_SIZE);
CHECK(cudaMemcpy(result_2, Output_2, BLOCK_NUM_2 * sizeof(DTYPE), cudaMemcpyDeviceToHost));
if (BLOCK_NUM_1 % BLOCK_SIZE != 0) {
for (int i = BLOCK_SIZE * BLOCK_NUM_2; i < BLOCK_NUM_1; i++) result_2[BLOCK_NUM_2] += result_1[i];
BLOCK_NUM_2++;
}
for (int i = 0; i < BLOCK_NUM_2; i++) sum += result_2[i];
return sum;
}
2 步骤二
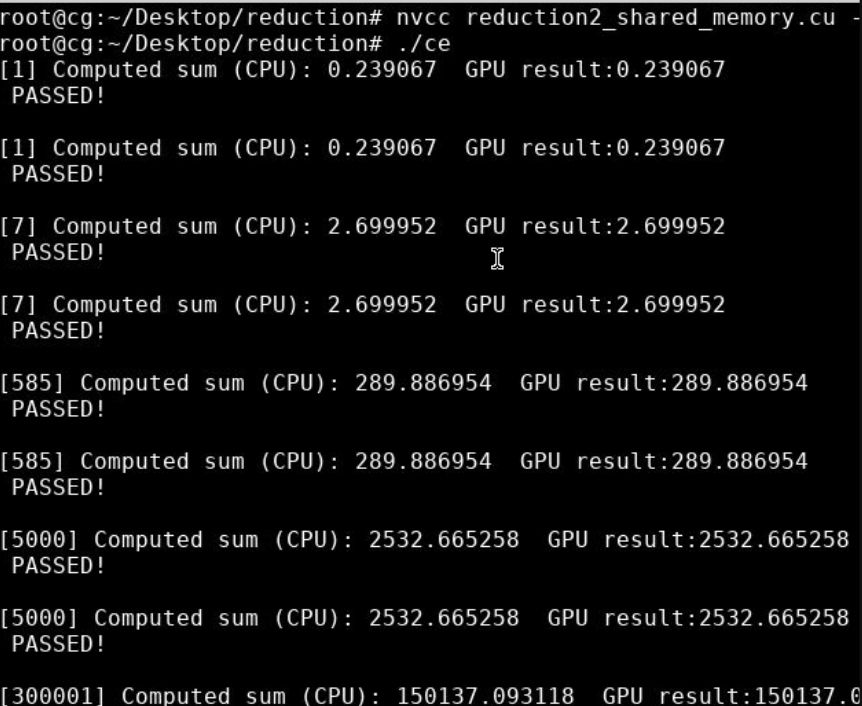
2.1 shared memory版 实验代码
/*
* Todo:
* 1. reduction kernel in which the threads are mapped to data with stride 2
* 2. using shared memory
*/__global__ voidkernel_reduction_shm_non_consecutive(DTYPE *input, DTYPE *output, int n){
__shared__ DTYPE Shared[BLOCK_SIZE];
int id = blockIdx.x * BLOCK_SIZE;
int tid = threadIdx.x;
Shared[tid * 2] = input[id + tid * 2];
Shared[tid * 2 + 1] = input[id + tid * 2 + 1];
__syncthreads();
for (int s = 1; s <= (n / 2); s <<= 1) {
if (tid % s == 0) {
Shared[tid * 2] += Shared[tid * 2 + s];
__syncthreads();
}
}
if (tid == 0) output[blockIdx.x] = Shared[0];
}
/*
* Todo:
* reduction kernel in which the threads are consecutively mapped to data
* 2. using shared memory
*/__global__ voidkernel_reduction_shm_consecutive(DTYPE *input, DTYPE *output, int n){
__shared__ DTYPE Shared[BLOCK_SIZE];
int id = blockIdx.x * BLOCK_SIZE;
int tid = threadIdx.x;
Shared[tid * 2] = input[id + tid * 2];
Shared[tid * 2 + 1] = input[id + tid * 2 + 1];
__syncthreads();
for (int s = n / 2; s >= 1; s >>= 1) {
if(tid<s){
Shared[tid] += Shared[tid + s];
__syncthreads();
}
}
if (tid == 0) output[blockIdx.x] = Shared[0];
}
2.2 实验效果
3 步骤三
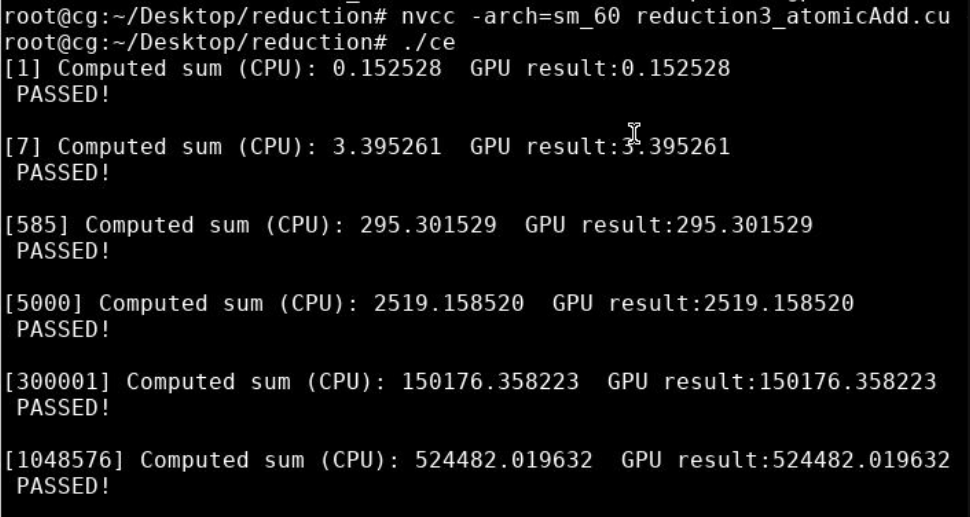
3.1 在核函数中求和 实验代码
/*
* Todo:
* 1. reduction kernel in which the threads are consecutively mapped to data
* 2. using atomicAdd to compute the total sum
*/__global__ voidkernel_reduction_atomicAdd(DTYPE *input, DTYPE *global_sum, int n){
__shared__ DTYPE Shared[BLOCK_SIZE];
int id = blockIdx.x * BLOCK_SIZE;
int tid = threadIdx.x;
Shared[tid * 2] = input[id + tid * 2];
Shared[tid * 2 + 1] = input[id + tid * 2 + 1];
__syncthreads();
for (int s = n / 2; s >= 1; s >>= 1) {
if(tid<s){
Shared[tid] += Shared[tid + s];
__syncthreads();
}
}
if (tid == 0) atomicAdd((double*)&global_sum[0], (double)Shared[tid]);
//统计答案
}
/*
* Todo:
* Wrapper function without the need to sum the reduced results from blocks
*/DTYPE gpu_reduction(DTYPE *input, int n,
void (*kernel)(DTYPE *input, DTYPE *global_sum, int n)){
DTYPE *Global_sum;
CHECK(cudaMalloc((void**)&Global_sum, sizeof(DTYPE)));
DTYPE *Input;
CHECK(cudaMalloc((void**)&Input, n * sizeof(DTYPE)));
CHECK(cudaMemcpy(Input, input, n * sizeof(DTYPE), cudaMemcpyHostToDevice));
dim3 block(BLOCK_SIZE / 2);
int BLOCK_NUM = n / BLOCK_SIZE;
dim3 grid(BLOCK_NUM);
kernel <<<grid, block>>>(Input, Global_sum, BLOCK_SIZE);
DTYPE *res = (DTYPE *)malloc(sizeof(DTYPE));
CHECK(cudaMemcpy(res, Global_sum, sizeof(DTYPE), cudaMemcpyDeviceToHost));
for (int i = BLOCK_NUM * BLOCK_SIZE; i < n; i++) res[0] += input[i];
return res[0];
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)