1.1 代码
/*
* Todo:
* Implement the kernel function while satisfying the following requirements*
* 1.1 Utilizing shared memory to achieve coalesced memory access to both input and output matrices *
*/
__global__ void kernel_transpose_per_element_tiled(DTYPE *input, DTYPE *output, int num_rows, int num_cols)
{
__shared__ DTYPE Shared[BLOCK_SIZE][BLOCK_SIZE];
int x = threadIdx.x;
int y = threadIdx.y;
int col_idx = blockIdx.x * blockDim.x + threadIdx.x;
int row_idx = blockIdx.y * blockDim.y + threadIdx.y;
if (row_idx < num_rows && col_idx < num_cols) {
Shared[x][y] = input[row_idx * num_cols + col_idx];
}
__syncthreads();
col_idx = blockIdx.y * blockDim.y + threadIdx.x;
row_idx = blockIdx.x * blockDim.x + threadIdx.y;
if (row_idx < num_cols && col_idx < num_rows) {
output[row_idx * num_rows + col_idx] = Shared[y][x];
}
}
/*
* Todo:
* Implement the kernel function while satisfying the following requirements*
* 2.1 Utilizing shared memory to achieve coalesced memory access to both input and output matrices *
* 2.2 Avoid bank conflicts *
*/
__global__ void kernel_transpose_per_element_tiled_no_bank_conflicts(DTYPE *input, DTYPE *output, int num_rows, int num_cols)
{
__shared__ DTYPE Shared[BLOCK_SIZE][BLOCK_SIZE + 1];
int x = threadIdx.x;
int y = threadIdx.y;
int col_idx = blockIdx.x * blockDim.x + threadIdx.x;
int row_idx = blockIdx.y * blockDim.y + threadIdx.y;
if (row_idx < num_rows && col_idx < num_cols) {
Shared[x][y] = input[row_idx * num_cols + col_idx];
}
__syncthreads();
col_idx = blockIdx.y * blockDim.y + threadIdx.x;
row_idx = blockIdx.x * blockDim.x + threadIdx.y;
if (row_idx < num_cols && col_idx < num_rows) {
output[row_idx * num_rows + col_idx] = Shared[y][x];
}
}
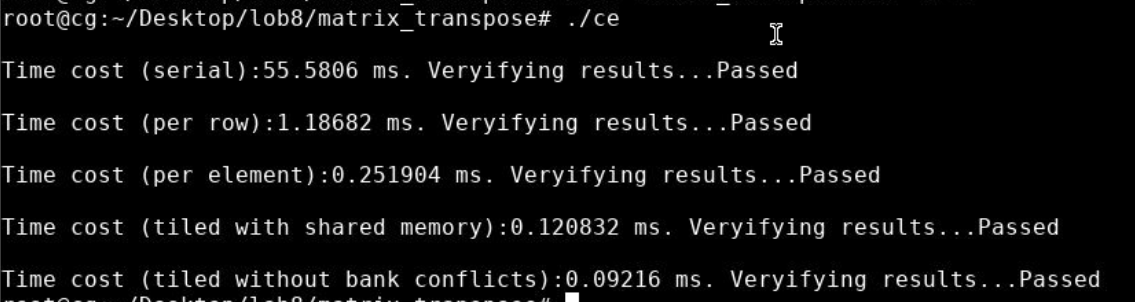
1.2 运行结果