GPU 编程第六次作业(实验七)
1 实验步骤一
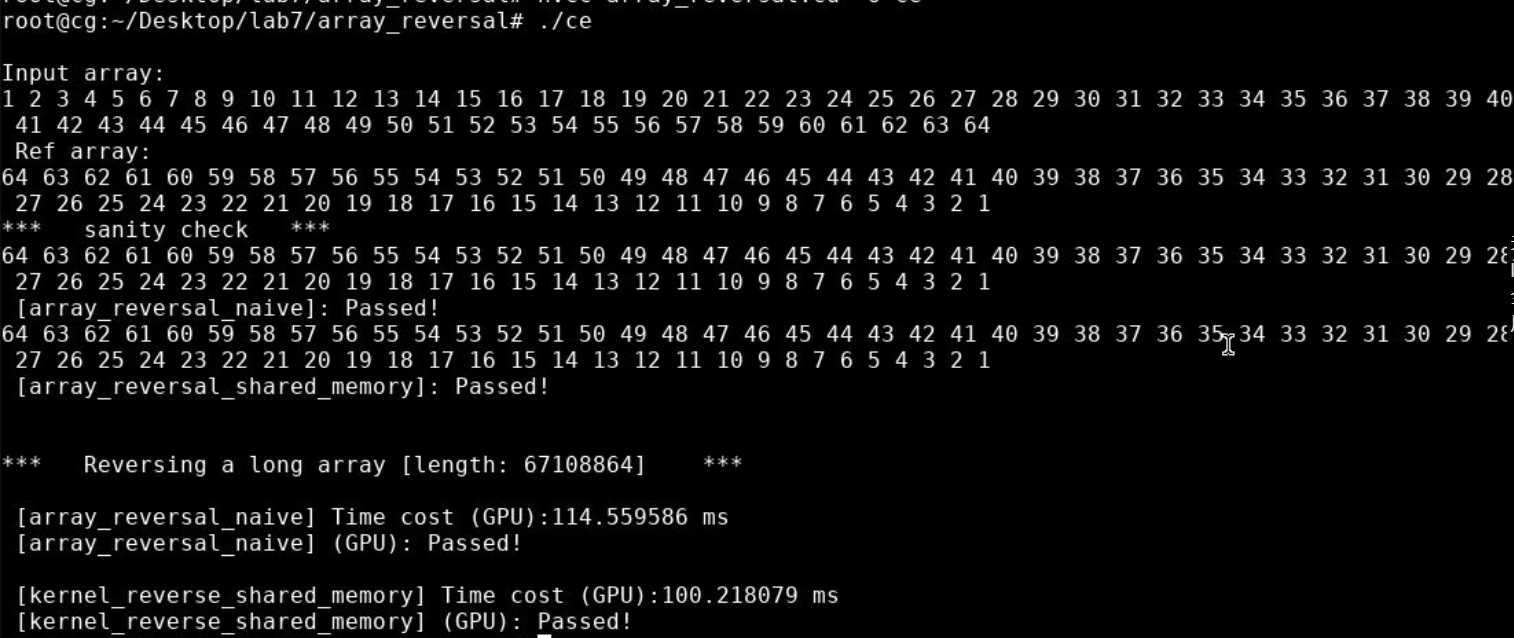
1.1 运行结果:
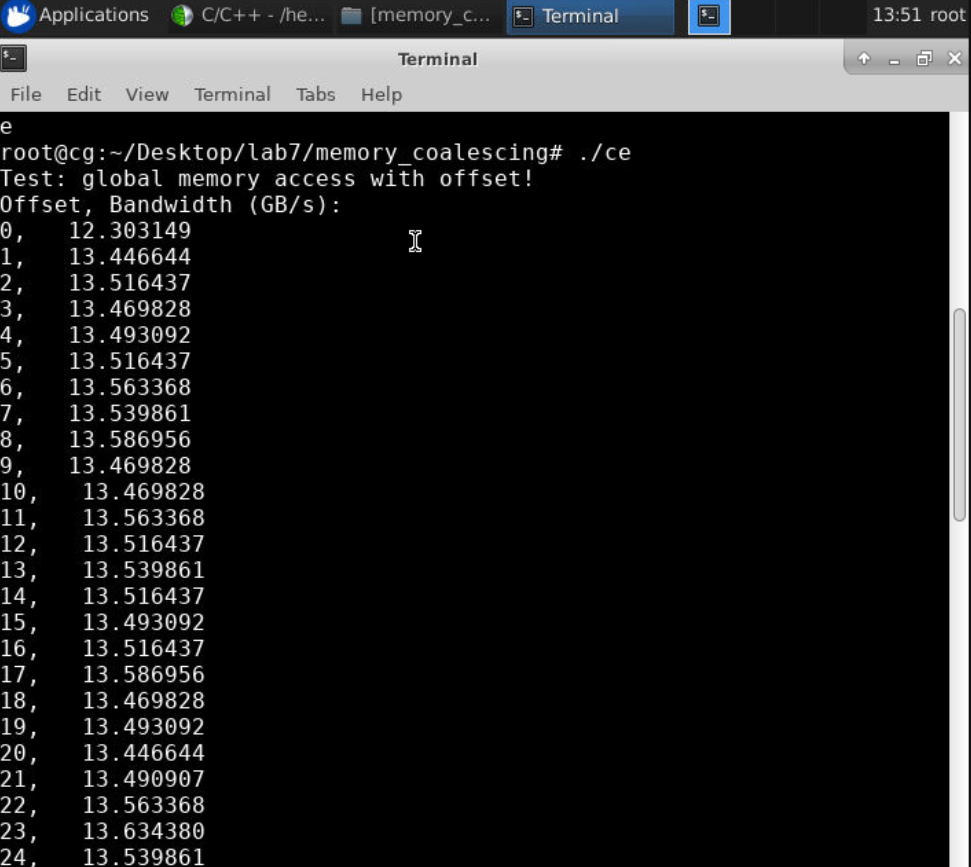
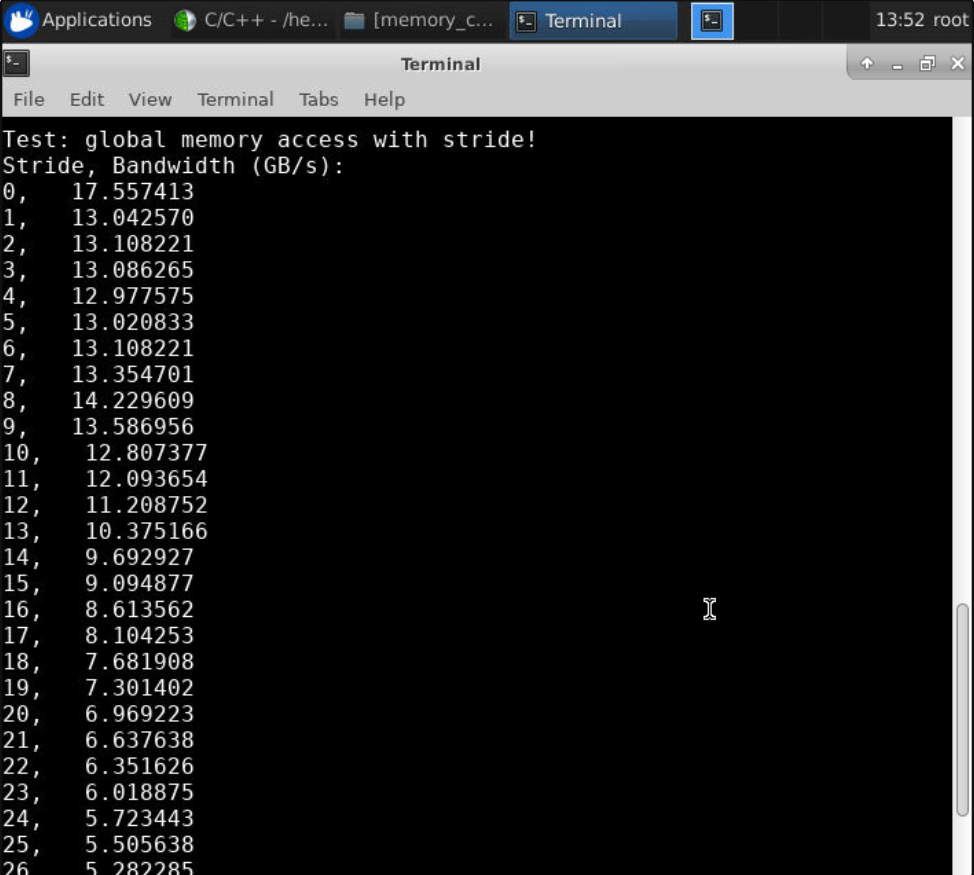
1.2 绘制图像
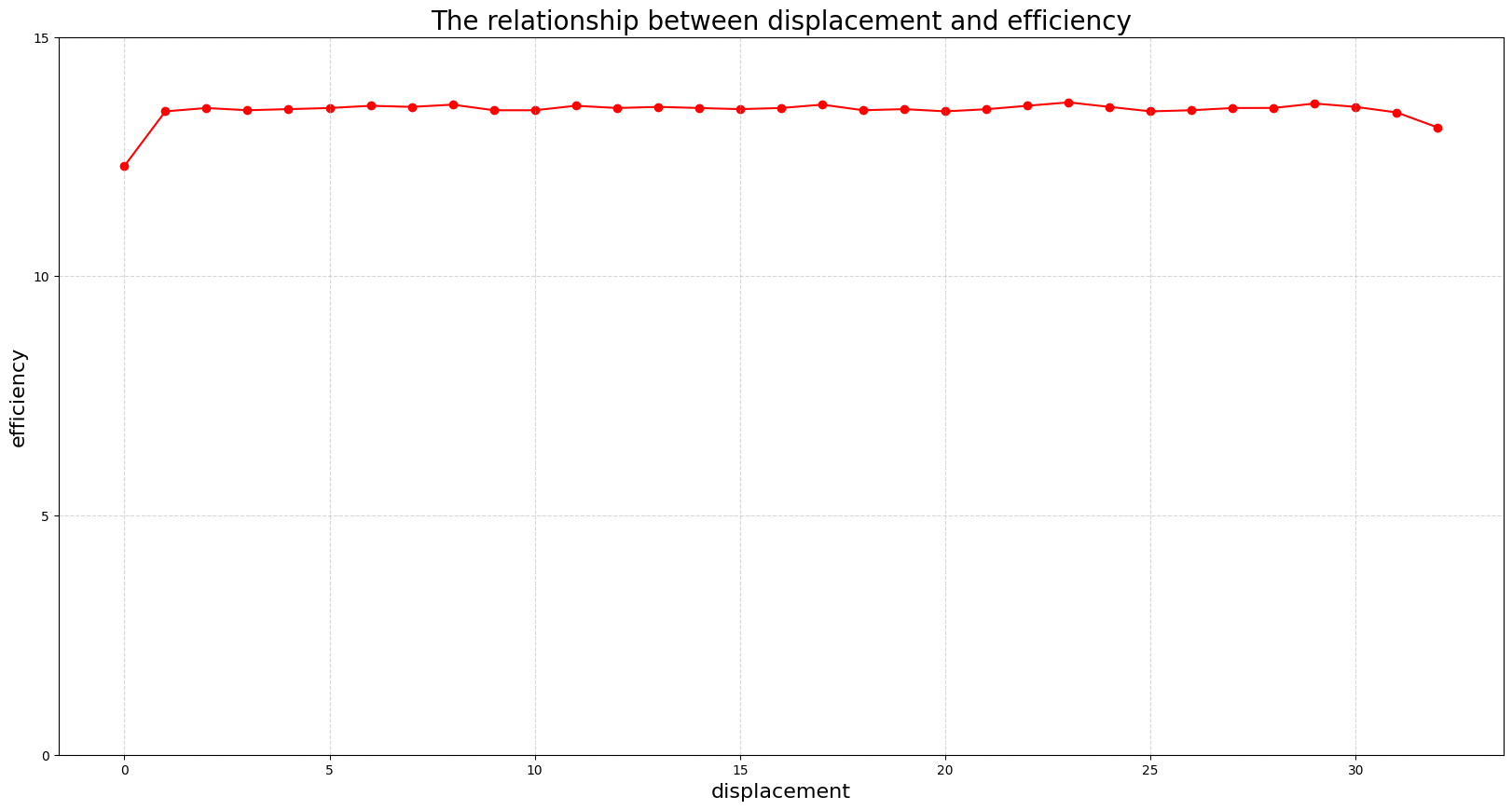
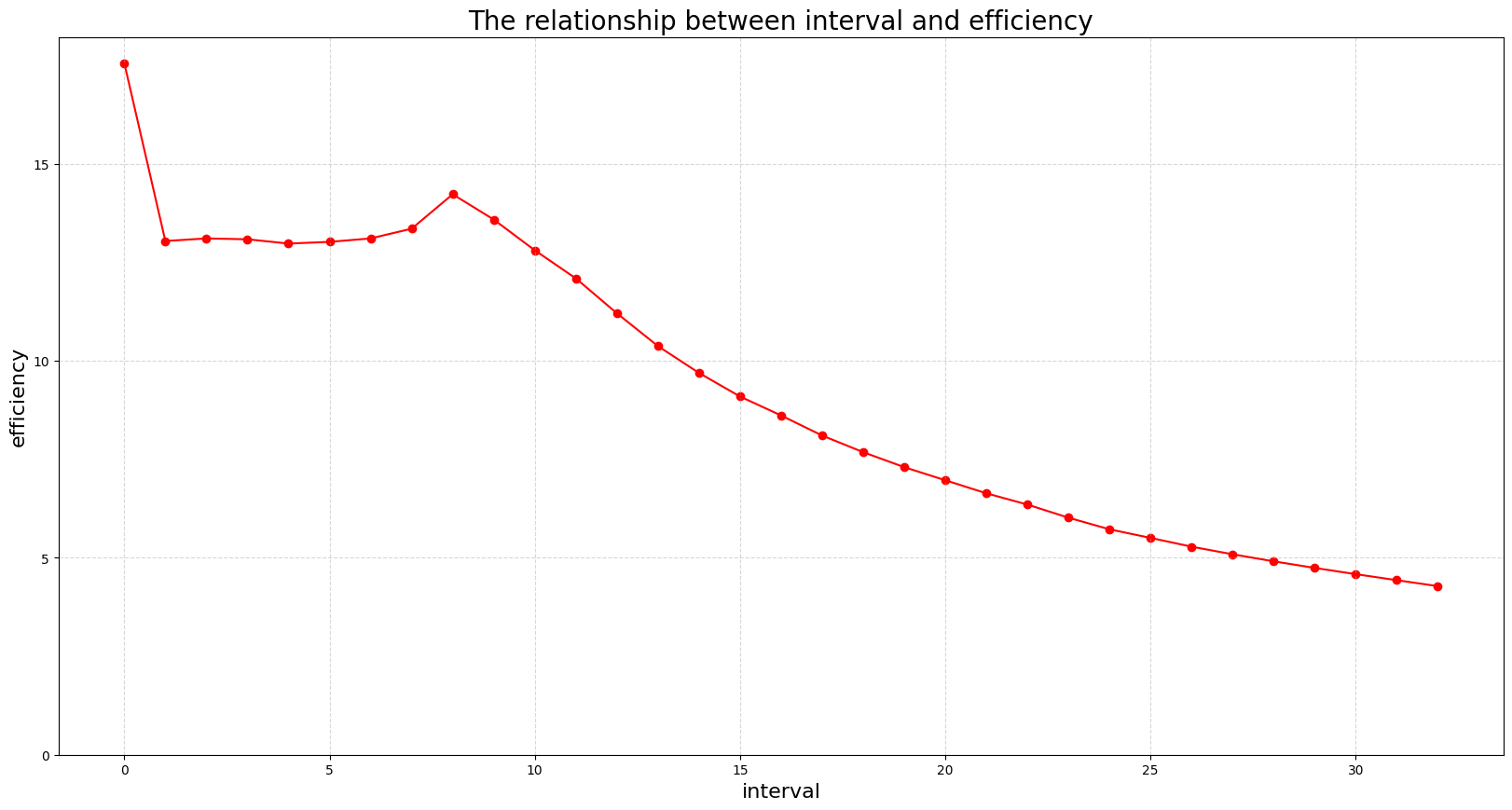
1.3 分析原因
就和这个图表现出的是一样的
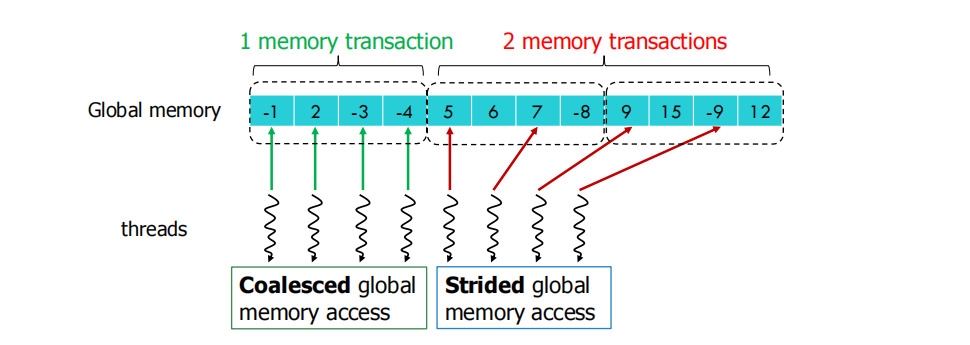
图一的访问尽管会有位移,但总归是顺序连续的访问,所以可以通过Coalesce 进行少量的 memory transactions,位移是多少没什么差别
图二表示说,访问的位置越稀疏速度就越慢,因为一次 transaction 访问到的显存位置就变少,访问次数就增加,效率就低
2 实验步骤二
2.1 代码
__global__ void kernel_reverse_shared_mem(DTYPE *input, DTYPE *output, int n)
{
unsigned int i = blockDim.x*blockIdx.x+threadIdx.x;
if(i>=n) return;
__shared__ DTYPE data[BLOCK_SIZE];
data[BLOCK_SIZE-1-threadIdx.x]=input[i]; //逆序
__syncthreads();
unsigned int j=((n-1-i)/BLOCK_SIZE)*BLOCK_SIZE+threadIdx.x;
output[j]=data[threadIdx.x]; //顺序
}
2.2 实验结果