GPU 编程第五次作业(实验六)
1 步骤一
1.1 任务一:完成Todo部分,要求分别使用静态方式和动态方式来分配shared memory
完成的代码如下:
// Todo 1
// Implement the Adjacent Difference application with *STATICALLY* allocated shared memory
// 1.1
// __global__ void kernel_adj_diff_static_shmem(DTYPE *input, DTYPE *output, int n)
__global__ void kernel_adj_diff_static_shmem(DTYPE *input, DTYPE *output, int n){
unsigned int i = blockDim.x*blockIdx.x+threadIdx.x;
__shared__ DTYPE s_data[BLOCK_SIZE];
s_data[threadIdx.x] = input[i];
__syncthreads();
if(i>0&&i<n){
if(threadIdx.x>0) output[i] = s_data[threadIdx.x] - s_data[threadIdx.x-1];
else output[i] = s_data[threadIdx.x] - input[i-1];
}
}
//
// 1.2 Implement
// DTYPE adj_diff_static_shmem(DTYPE *data_input, DTYPE *data_output, int n)
DTYPE adj_diff_static_shmem(DTYPE *data_input, DTYPE *data_output, int n){
double begin, time_cost;
DTYPE *d_data_input = NULL;
DTYPE *d_data_output = NULL;
CHECK(cudaMalloc((void **)&d_data_input, n*sizeof(DTYPE)));
CHECK(cudaMalloc((void **)&d_data_output, n*sizeof(DTYPE)));
CHECK(cudaMemcpy(d_data_input, data_input, n*sizeof(DTYPE), cudaMemcpyHostToDevice));
CHECK(cudaMemset(d_data_output, 0, n*sizeof(DTYPE)));
int blockDim = BLOCK_SIZE;
int gridDim = (n-1)/blockDim + 1;
begin = cpuSecond();
kernel_adj_diff_static_shmem<<<gridDim, blockDim>>>(d_data_input, d_data_output, n);
CHECK(cudaDeviceSynchronize());
time_cost = cpuSecond()-begin;
CHECK(cudaGetLastError());
CHECK(cudaMemcpy(data_output, d_data_output, n*sizeof(DTYPE), cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_data_input));
CHECK(cudaFree(d_data_output));
return time_cost;
}
// Todo 2
// Implement the Adjacent Difference application with *DYNAMICALLY* allocated shared memory
// 2.1
// __global__ void kernel_adj_diff_dynamic_shmem(DTYPE *input, DTYPE *output, int n)
__global__ void kernel_adj_diff_dynamic_shmem(DTYPE *input, DTYPE *output, int n){
unsigned int i = blockDim.x*blockIdx.x+threadIdx.x;
extern __shared__ DTYPE s_data[];
s_data[threadIdx.x] = input[i];
__syncthreads();
if(i>0&&i<n){
if(threadIdx.x>0) output[i] = s_data[threadIdx.x] - s_data[threadIdx.x-1];
else output[i] = s_data[threadIdx.x] - input[i-1];
}
}
//
// 2.2 Implement
// DTYPE adj_diff_dynamic_shmem(DTYPE *data_input, DTYPE *data_output, int n)
DTYPE adj_diff_dynamic_shmem(DTYPE *data_input, DTYPE *data_output, int n){
double begin, time_cost;
DTYPE *d_data_input = NULL;
DTYPE *d_data_output = NULL;
CHECK(cudaMalloc((void **)&d_data_input, n*sizeof(DTYPE)));
CHECK(cudaMalloc((void **)&d_data_output, n*sizeof(DTYPE)));
CHECK(cudaMemcpy(d_data_input, data_input, n*sizeof(DTYPE), cudaMemcpyHostToDevice));
CHECK(cudaMemset(d_data_output, 0, n*sizeof(DTYPE)));
int blockDim = BLOCK_SIZE;
int gridDim = (n-1)/blockDim + 1;
begin = cpuSecond();
kernel_adj_diff_dynamic_shmem<<<gridDim, blockDim, BLOCK_SIZE * sizeof(int)>>>(d_data_input, d_data_output, n);
CHECK(cudaDeviceSynchronize());
time_cost = cpuSecond()-begin;
CHECK(cudaGetLastError());
CHECK(cudaMemcpy(data_output, d_data_output, n*sizeof(DTYPE), cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_data_input));
CHECK(cudaFree(d_data_output));
return time_cost;
}
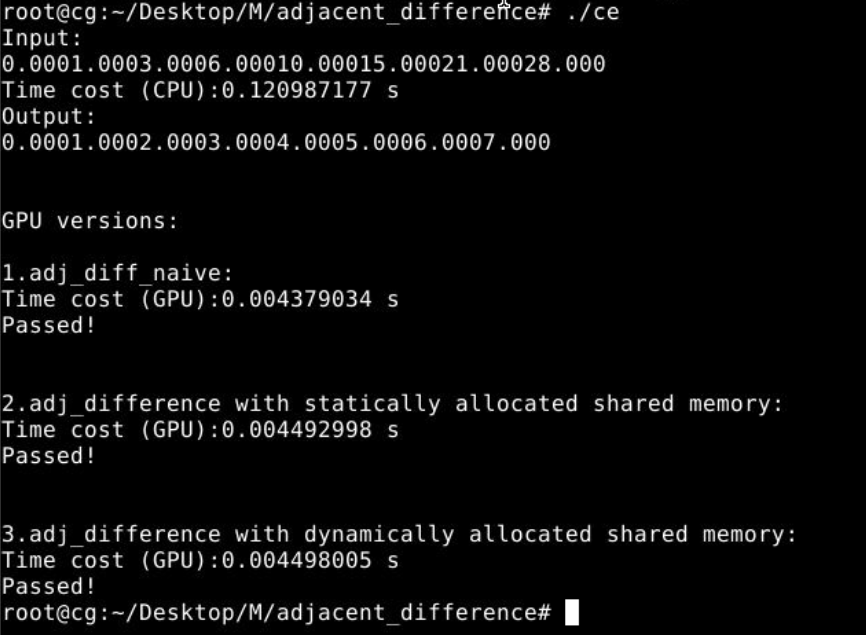
运行结果:
1.2 任务二:自由修改上述代码,尝试在同时满足以下两个条件的情况下,准确计算相邻元素差
要求没有时间的损失,我有两个想法:
第一个想法是把 __shared__ DTYPE s_data[BLOCK_SIZE]; 当作全局变量,然后在两个 \(gpu\) 函数中分别修改和调用
__shared__ DTYPE s_data[BLOCK_SIZE];
__global__ void init_gpu(DTYPE *input, int n){
unsigned int i = blockDim.x*blockIdx.x+threadIdx.x;
if(i<n&&i>0)s_data[threadIdx.x] = input[i];
}
__global__ void adj_diff_gpu(DTYPE *input, DTYPE *output, int n){
unsigned int i = blockDim.x*blockIdx.x+threadIdx.x;
if(i>0&&i<n){
if(threadIdx.x==0) output[i]=s_data[threadIdx.x]-input[i-1];
else output[i]-=s_data[threadIdx.x]-s_data[threadIdx.x-1];
}
}
但是运行出来还是错误的,分析原因应该是 __shared__ DTYPE s_data[BLOCK_SIZE]; 这个东西只能当局部变量。
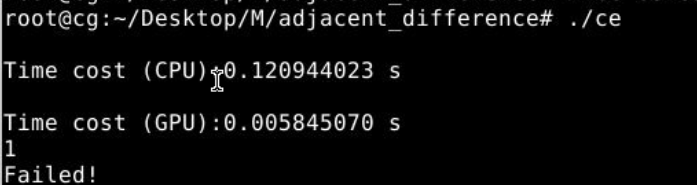
第二个想法是可以在 s_data[threadIdx.x] = input[i]; 之后,就把 input[i] 的贡献给计算了。
可以看代码:
__global__ void adj_diff_gpu(DTYPE *input, DTYPE *output, int n){
unsigned int i = blockDim.x*blockIdx.x+threadIdx.x;
__shared__ DTYPE s_data[BLOCK_SIZE];
s_data[threadIdx.x] = input[i];
if(i>0&&i<n){
output[i] += s_data[threadIdx.x];
//让output[i]加上input[i]
if(threadIdx.x==0) output[i]-=input[i-1];
if(i+1!=n&&threadIdx.x+1!=BLOCK_SIZE) output[i+1]-=s_data[threadIdx.x];
//让output[i+1]减去input[i]
}
}
但是很遗憾这个做法跑出来是错的,分析原因可能是我在不同的线程中都修改了 output[i] ,可能不合法?

但是可以发现,每次错误的地方都32的倍数(很奇怪),于是把 BLOCK_SIZE 改为32答案就全部对了。

