GPU 编程第四次作业(实验五)
GPU 编程第四次作业(实验五)
1 实验步骤一:
1.1 代码
#include<stdio.h>
#include<stdlib.h>
#define N 4
int main(void)
{
int arr[N][N] = {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}, {13,14,15,16}};
printf("Original 2D array: \n");
for(int i=0; i<N; i++){
for(int j=0; j<N; j++){
printf("%d ", arr[i][j]);
}
printf("\n");
}
printf("\n Row-major layout: \n");
int *p1 = NULL;
int *p2 = NULL;
int *p3 = NULL;
// Todo
p1 = arr[0];
printf("Approach 1: (address:%p)\n", p1);
for(int j=0; j<N*N; j++){
printf("%d ", *(p1+j));
}
// Todo
p2 = *arr;
printf("Approach 2: (address:%p)\n", p2);
for(int j=0; j<N*N; j++){
printf("%d ", *(p2+j));
}
// Todo
p3 = arr[0][0];
printf("Approach 3: (address:%p)\n", p3);
for(int j=0; j<N*N; j++){
printf("%d ", *(p3+j));
}
return 0;
}
1.2 运行结果
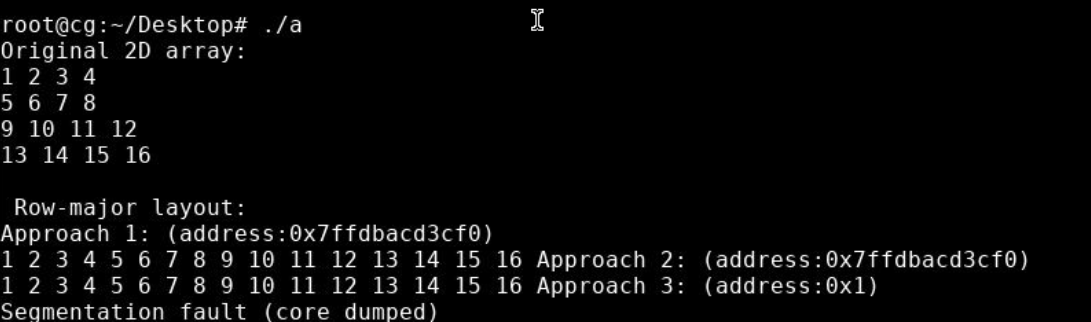
2 实验步骤二
2.1 代码
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define STB_IMAGE_IMPLEMENTATION
#include "stb_image/stb_image.h"
#define STB_IMAGE_WRITE_IMPLEMENTATION
#include "stb_image/stb_image_write.h"
#include"error_check.h"
#include"time_helper.h"
// Todo
// Implement the cuda kernel function ***rgb_to_sepia_gpu***
__global__ void rgb_to_sepia_gpu(unsigned char *input_image, unsigned char *output_image, int width, int height, int channels) {
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
if (Col < width && Row < height) {
int offset = (Row * width + Col) * channels;
unsigned char c1 = input_image[offset];
unsigned char c2 = input_image[offset + 1];
unsigned char c3 = input_image[offset + 2];
*(output_image + offset) = (unsigned char)fmin((c1 * 0.393 + c2 * 0.769 + c3 * 0.189), 255.0);
*(output_image + offset + 1) = (unsigned char)fmin((c1 * 0.349 + c2 * 0.686 + c3 * 0.168), 255.0);
*(output_image + offset + 2) = (unsigned char)fmin((c1 * 0.272 + c2 * 0.534 + c3 * 0.131), 255.0);
if (channels == 4) {
*(output_image + offset + 3) = input_image[offset + 3];
}
}
}
void rgb_to_sepia_cpu(unsigned char *input_image, unsigned char *output_image, int width, int height, int channels)
{
for(int row=0; row<height; row++)
{
for(int col=0; col<width; col++)
{
int offset = (row*width + col)*channels;
unsigned char c1 = input_image[offset];
unsigned char c2 = input_image[offset+1];
unsigned char c3 = input_image[offset+2];
*(output_image + offset) = (unsigned char)fmin((c1 * 0.393 + c2 * 0.769 + c3 * 0.189), 255.0);
*(output_image + offset + 1) = (unsigned char)fmin((c1 * 0.349 + c2 * 0.686 + c3 * 0.168), 255.0);
*(output_image + offset + 2) = (unsigned char)fmin((c1 * 0.272 + c2 * 0.534 + c3 * 0.131), 255.0);
if(channels==4)
{
*(output_image + offset + 3) = input_image[offset + 3];
}
}
}
}
int main(int argc, char *argv[])
{
if(argc<4)
{
printf("Usage: command input-image-name output-image-name option option(cpu/gpu)");
return -1;
}
char *input_image_name = argv[1];
char *output_image_name = argv[2];
char *option = argv[3];
int width, height, original_no_channels;
int desired_no_channels = 0; // Pass 0 to load the image as is
unsigned char *stbi_img = stbi_load(input_image_name, &width, &height, &original_no_channels, desired_no_channels);
if(stbi_img==NULL){ printf("Error in loading the image.\n"); exit(1);}
printf("Loaded image with a width of %dpx, a height of %dpx. The original image had %d channels, the loaded image has %d channels.\n", width, height, original_no_channels, desired_no_channels);
int channels = original_no_channels;
int img_mem_size = width * height * channels * sizeof(char);
double begin;
if(strcmp(option, "cpu")==0)
{
printf("Processing with CPU!\n");
unsigned char *sepia_img = (unsigned char *)malloc(img_mem_size);
if(sepia_img==NULL){ printf("Unable to allocate memory for the sepia image. \n"); exit(1); }
// Time stamp
begin = cpuSecond();
// CPU computation (for reference)
rgb_to_sepia_cpu(stbi_img, sepia_img, width, height, channels);
// Time stamp
printf("Time cost [CPU]:%f s\n", cpuSecond()-begin);
// Save to an image file
stbi_write_jpg(output_image_name, width, height, channels, sepia_img, 100);
free(sepia_img);
}
else if(strcmp(option, "gpu")==0)
{
printf("Processing with GPU!\n");
// Todo: 1. Allocate memory on GPU
unsigned char *Input, *Output;
CHECK(cudaMalloc((void**)&Input, img_mem_size));
CHECK(cudaMalloc((void**)&Output, img_mem_size));
// Todo: 2. Copy data from host memory to device memory
CHECK(cudaMemcpy(Input, stbi_img, img_mem_size, cudaMemcpyHostToDevice));
// Todo: 3. Call kernel function
// 3.1 Declare block and grid sizes
const int block_x = 32, block_y = 32;
dim3 block(block_x, block_y);
const int grid_x = (width - 1) / block_x + 1, grid_y = (height - 1) / block_y + 1;
dim3 grid(grid_x, grid_y);
// 3.2 Record the time cost of GPU computation
begin = cpuSecond();
// Todo: 3.3 Call the kernel function (Don't forget to call cudaDeviceSynchronize() before time recording)
rgb_to_sepia_gpu<<<grid, block>>>(Input, Output, width, height, channels);
CHECK(cudaDeviceSynchronize());
printf("Time cost [GPU]:%f s\n", cpuSecond()-begin);
// Todo: 4. Copy data from device to host
unsigned char *sepia_img = (unsigned char *)malloc(img_mem_size);
CHECK(cudaMemcpy(sepia_img, Output, img_mem_size, cudaMemcpyDeviceToHost));
// Todo: 5. Save results as an image
/* stbi_write_jpg(output_image_name, width, height, channels, sepia_img_from_gpu, 100); */
stbi_write_jpg(output_image_name, width, height, channels, sepia_img, 100);
// Todo: 6. Release host memory and device memory
CHECK(cudaFree(Input));
CHECK(cudaFree(Output));
free(sepia_img);
}
else
{
printf("Unexpected option (please use cpu/gpu) !\n");
}
stbi_image_free(stbi_img);
return 0;
}
2.2 运行结果


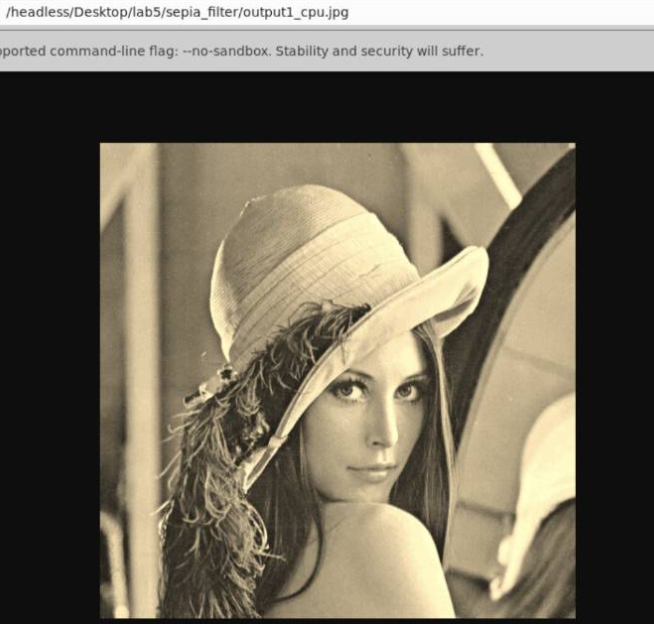
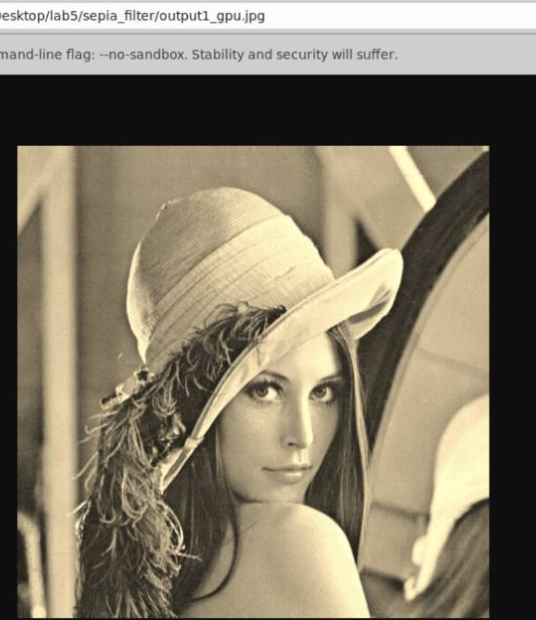
3 实验步骤三
3.1 主要代码
__global__ void BLUR_gpu(unsigned char *input_image, unsigned char *output_image, int width, int height, int channels, int blur_size) {
int Col = blockIdx.x * blockDim.x + threadIdx.x;
int Row = blockIdx.y * blockDim.y + threadIdx.y;
if ((Col < width) && (Row < height)) {
double* sum = (double*) malloc(channels * sizeof(double));
for (int i = 0; i < channels; i++) {
sum[i] = 0.0;
}
double cnt = 0.0;
for (int movRow = -blur_size; movRow <= blur_size; movRow++) {
for (int movCol = -blur_size; movCol <= blur_size; movCol++) {
int newRow = Row + movRow;
int newCol = Col + movCol;
if ((newRow >= 0) && (newRow < height) && (newCol >= 0) && (newCol < width)) {
cnt++;
int newOffset = (newRow * width + newCol) * channels;
for (int i = 0; i < channels; i++) {
unsigned char v = *(input_image + newOffset + i);
sum[i] += (double) v;
}
}
}
}
int offset = (Row * width + Col) * channels;
for (int i = 0; i < channels; i++) {
*(output_image + offset + i) = (unsigned char) (sum[i] / cnt);
}
free(sum);
}
}
3.2 一些结果
blur_size=15

blur_size=20


