进程和线程
进程模型
进程是正在运行程序的抽象
进程的模型就是一个顺序执行的过程,来保证并行
一个进程是一个正在执行的程序,包括程序计数器,寄存器和变量等,即每个进程都有自己的虚拟CPU
我们把CPU的程序计数器叫做物理程序计数器,进程保存的程序计数器叫做逻辑程序计数器
如下图所示,每个进程都有自己的程序,彼此独立运行,然而实际上只有一个CPU,只有一个物理的程序计数器,所以当进程运行的时候,进程的逻辑程序计数器被加载到实际的程序计数器,运行时间结束的时候,就会把物理程序计数器保存到逻辑程序计数器。所以看上去程序都在并行运行,但是在任意时间,都只有一个进程在运行
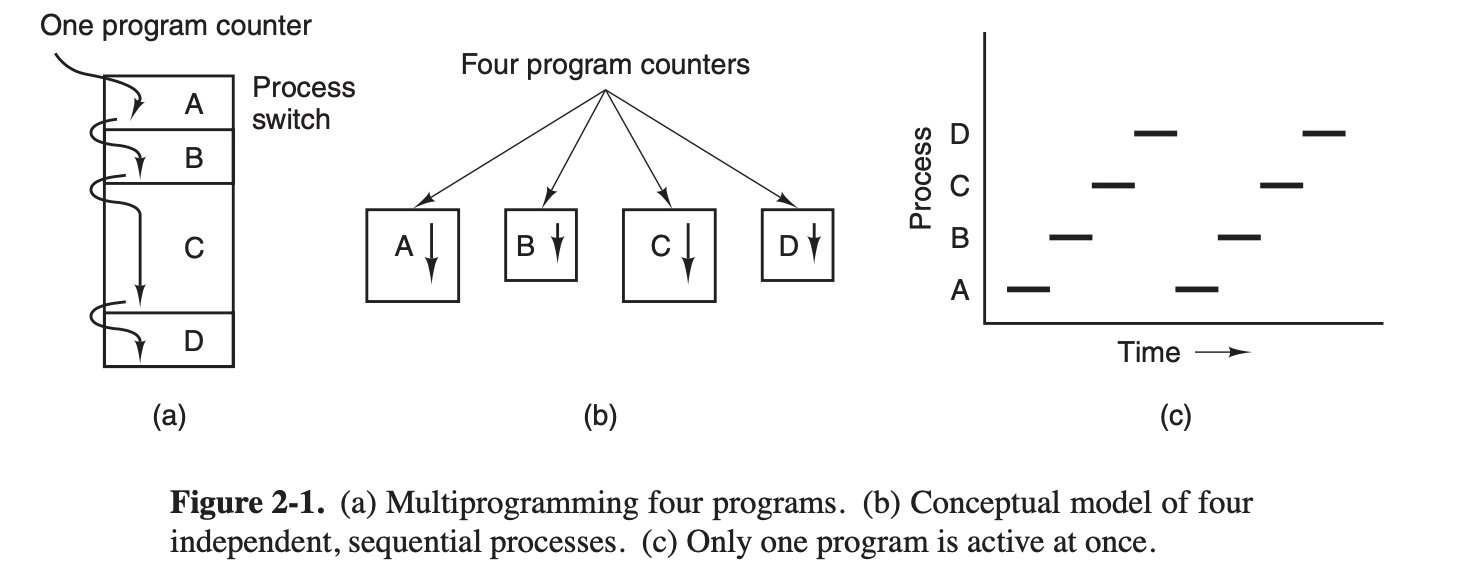
由于上下文切换时间不确定,所以不能对进程进行基于时间假定的编程。进程是正在运行的程序,而程序一般是保存在磁盘上的,一个程序运行两个,那就是两个进程,但是是同一个程序
总结来说进程模型是基于两个独立的概念:资源整合和执行
创建进程
创建进程四个首要条件:
- 系统初始化
- 通过运行的进程来执行进程创建的系统调用
- 用户请求来创建一个新进程
- 批量任务的初始化
创建进程的场景:
- 系统在启动的时候,会创建一些进程,一般称为守护进程(daemons)。可以使用
ps查看进程列表 - 启动之后,也会创建新进程,用来处理一些相关但独立的工作
- 交互式系统中,可以通过双击图标或者输入命令来创建新进程
- 批处理系统
UNIX系统中,使用系统调用fork创建进程,调用之后,会有父子两个进程,两个进程内容完全一致
,子进程使用exec系统调用来改变内存镜像。分为两步的主要原因是允许子进程组装自己的文件描述符,完成输入输出重定向
Windows中,使用CreateProcess创建和执行新进程,有很多参数
无论是UNIX还是Windows,进程创建后,都有自己独立的地址空间。在UNIX中,子进程的初始化地址空间是父进程的一个副本,但是有两个完全独立的地址空间,可写的内存不会被共享。这也被称为写时复制(copy-on-write)。
终止进程
终止进程的四个原因
- 正常退出
- 错误退出
- 严重错误
- 由其他进程杀死
UNIX的系统调用是exit,Windows的系统调用是ExitProcess
进程层次结构
每个子进程只有一个父进程,在UNIX中,一个进程和它所有的子进程组成了一个进程组,进程组内都能捕获到信号,各自进程按需处理
进程状态
- 运行态(Running) 正在占用CPU
- 就绪态(Ready) 可以运行的,但是临时暂停让其他进程运行。没有占用CPU
- 阻塞态(Blocked) 直到一些事件发生的时候才能运行。就算CPU空闲都不会运行
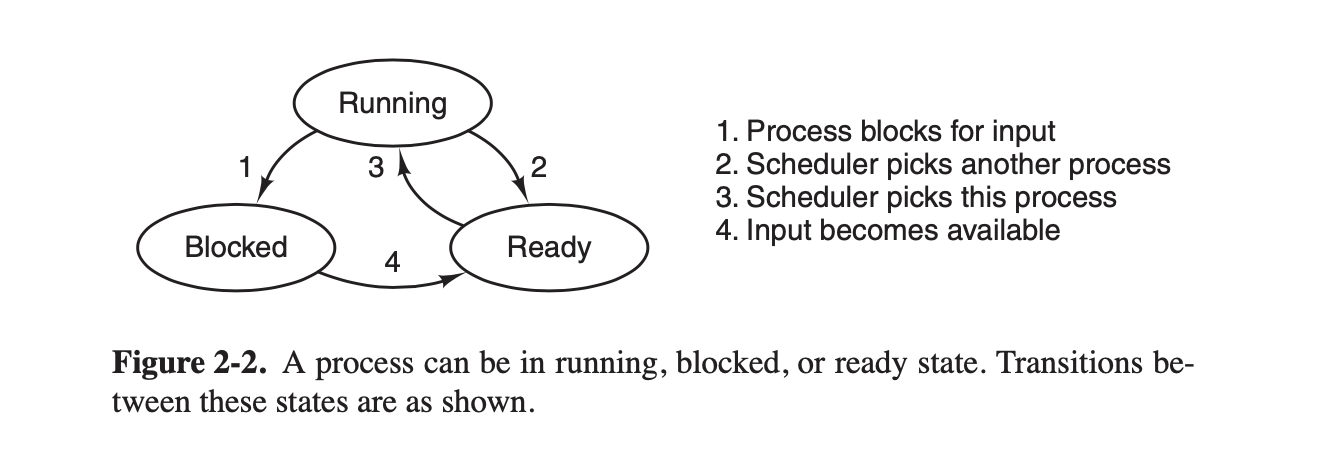
如上图,三个状态之间有四个转换
- 转换1: 运行态->阻塞态。一般是执行系统调用或者等待事件
- 转换2: 运行态->就绪态。进程调度导致,CPU主动让出CPU
- 转换3: 就绪态->运行态。进程调度,跟转换2是逆反过程
- 转换4: 阻塞态->就绪态。转换1中的等待完成了
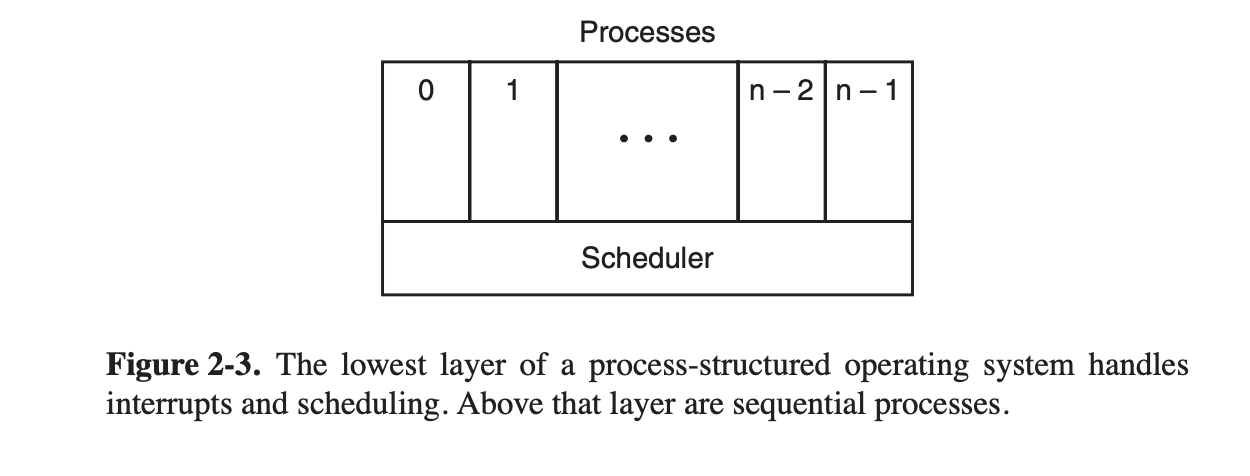
所以进程模型总结来说就是下面这个图。操作系统底层是调度器,上层是各种进程,调度器实现了一些隐藏的细节比如上下文切换,进程数据保存和恢复等
进程实现
进程主要是通过进程表(process table)结构体实现整个进程,也有称为进程控制块(process control blocks,即PCB)。主要的数据有:程序计数器,栈计数器,内存分配,打开文件的状态,还有一些上下文切换所必须要的数据
每个I/O关联了一个位置(通常是内存底部的位置),这个位置称为中断向量。它包含中断服务程序的地址,当进程发送中断的时候,操作系统会跳转到中断向量的地址处执行。所有的中断都是由保存寄存器开始,通常是当前进程的进程表入口,然后通过中断压入到栈上的信息会被移除,栈指针指向当前进程处理器使用的一个临时栈,这个操作只能由汇编语言完成。这些完成之后,会调用C程序执行。当调度器要切换进程时,会回到汇编语言去保存之前的进程数据,并加载新进程的寄存器和内存映射,执行完之后,再回到C程序执行
经典线程模型
线程拥有的资源:
- 程序计数器。用来跟踪下一条要进行的指令
- 寄存器。用来保存当前工作变量
- 栈。用来保存历史执行的指令
进程是用来组织资源的,线程是CPU调度执行的最小单元
线程模型就是在进程模型上面增加了允许多次执行来代替相同的进程环境。一个进程的所有线程共享一个地址空间
线程没有父子继承关系,所有的线程都是平等的。
线程系统调用:
thread_create创建一个线程,返回值是一个线程id来命名一个新的线程;thread_exit结束线程;thread_join一个线程等待其他线程退出;thread_yield是允许线程放弃CPU,让其他线程运行;CPU没有时钟中断线程调用,所以需要这个系统调用让线程主动让出
用户级和内核级线程
用户级线程,每个进程都自己维护一个线程表,线程表和内核的进程表类似
内核级线程,内核维护一张线程表,线程的操作都是通过内核调用来实现的
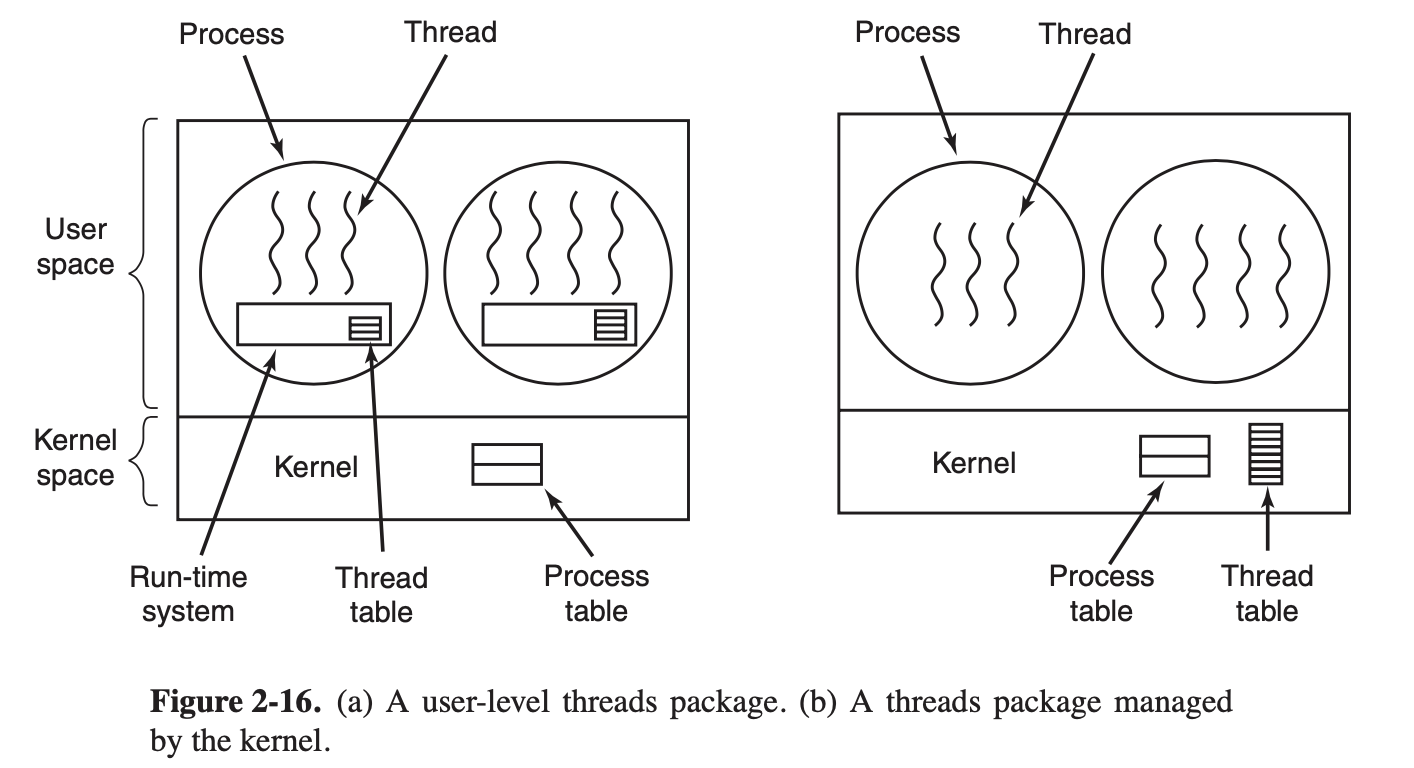
用户级线程优点(内核级线程缺点):
- 可以在不支持多线程的操作系统上实现
- 线程切换时不需要陷入内核,不用做上下文切换,所以比内核线程快,同时对系统损害小
- 让每个进程有自定义的调度算法
用户级线程缺点(内核级线程优点):
- 阻塞系统调用该怎么实现。非阻塞(如非阻塞的
read)或者事件(如select) - 如果运行了一个线程,那么在这个线程让出CPU之前,其他线程都不会运行
现在基本上都是混合实现,用户级进程维护自己的线程表,同时绑定到内核进程,类似于go语言的协程实现
进程和线程的区别
这是一个面试常问的问题,关于这一点,只需要抓住进程和线程最根本的区别就可以扩展。进程是管理资源的最小单位,线程是CPU执行的最小单位。 这句话怎么理解,线程是需要扔到CPU去执行的,所以它自己只包括CPU执行的基本数据,如程序计数器,堆栈信息,寄存器等,其他资源都是共享的;进程是地址空间的抽象,是虚拟的,它包含一个程序要运行的一些基本资源,如I/O,文件描述符,进程数据,地址空间等,它是用来管理整个程序运行的资源的,当然它也包括上下文切换,CPU调度等,但它的调度最终还是执行在线程中。所以什么线程比进程更轻量,进程拥有自己的独立地址空间等都是由其原理推断出来的,为了简单描述,还是做了以下的总结
- 线程在进程下进行,一个进程可以包含多个线程
- 不同进程间数据很难贡献,不同线程可以共享同一个进程的地址空间
- 进程比线程要消耗更多的资源
- 进程间不会相互影响,线程挂掉会导致整个进程挂掉
- 进程使用的内存地址可以上锁,即线程使用共享地址空间时,需要上锁
- 进程使用的内存地址可以限定使用量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号